Monitor Your SaaS Product in 10 Minutes
Every minute of downtime erodes customer trust and revenue. Get full visibility into your servers, databases, APIs, and uptime — before your customers notice a problem.
15-day free trial · No credit card required · Production-ready in minutes
When Your SaaS Goes Down, Trust Disappears
Downtime is devastating
The average cost of IT downtime is $5,600 per minute for mid-size companies. For a SaaS product, it's not just lost revenue — it's churned customers, broken integrations, and SLA penalties. A single prolonged outage can undo months of customer acquisition.
DIY monitoring is a project you'll never finish
Setting up Prometheus, Grafana, Alertmanager, and long-term storage takes weeks. Then you need to maintain it, upgrade it, and write alert rules for every service. That's engineering time not spent building your product.
Bleemeo: production monitoring without the project
Bleemeo gives you complete infrastructure monitoring — servers, databases, web servers, caches, message queues, and uptime — in 10 minutes, with zero configuration. Know about problems before your customers open a support ticket.
Scales with your architecture
Whether you're running a monolith on a single server or a microservices architecture across multiple clouds, Bleemeo adapts to your stack automatically. You get server metrics, database performance, cache efficiency, and external uptime monitoring — all from one agent and one dashboard, with alerts that work out of the box.
3 Steps to Complete SaaS Monitoring
Your engineering team can set this up during a coffee break.
Install the Agent on Your Servers
One command per server. Bleemeo's Glouton agent auto-discovers your entire SaaS stack: web server, application runtime, database, cache, message broker, and search engine.
wget -qO- 'https://get.bleemeo.com?accountId=...' Run this on each server in your stack. The agent detects everything running on the machine — no configuration file to write.
Auto-detected SaaS stacks
Why auto-discovery matters for SaaS
SaaS stacks evolve fast — new services get deployed, containers get replaced, dependencies change. Manually configuring monitoring for each component means hours of YAML and the constant risk of blind spots. Bleemeo detects every service on your machine in seconds, so nothing falls through the cracks — even as your architecture evolves.
Add Uptime Monitors for Your Critical Endpoints
Monitor your most important URLs from 7 global locations. Bleemeo checks availability, response time, SSL certificate expiration, and content validation every 60 seconds.
- API endpoints — your product's backbone
- Web application — login page, dashboard, key flows
- Webhook receivers — integration reliability
- Status page — what your customers see
- Admin panel — your operational backbone
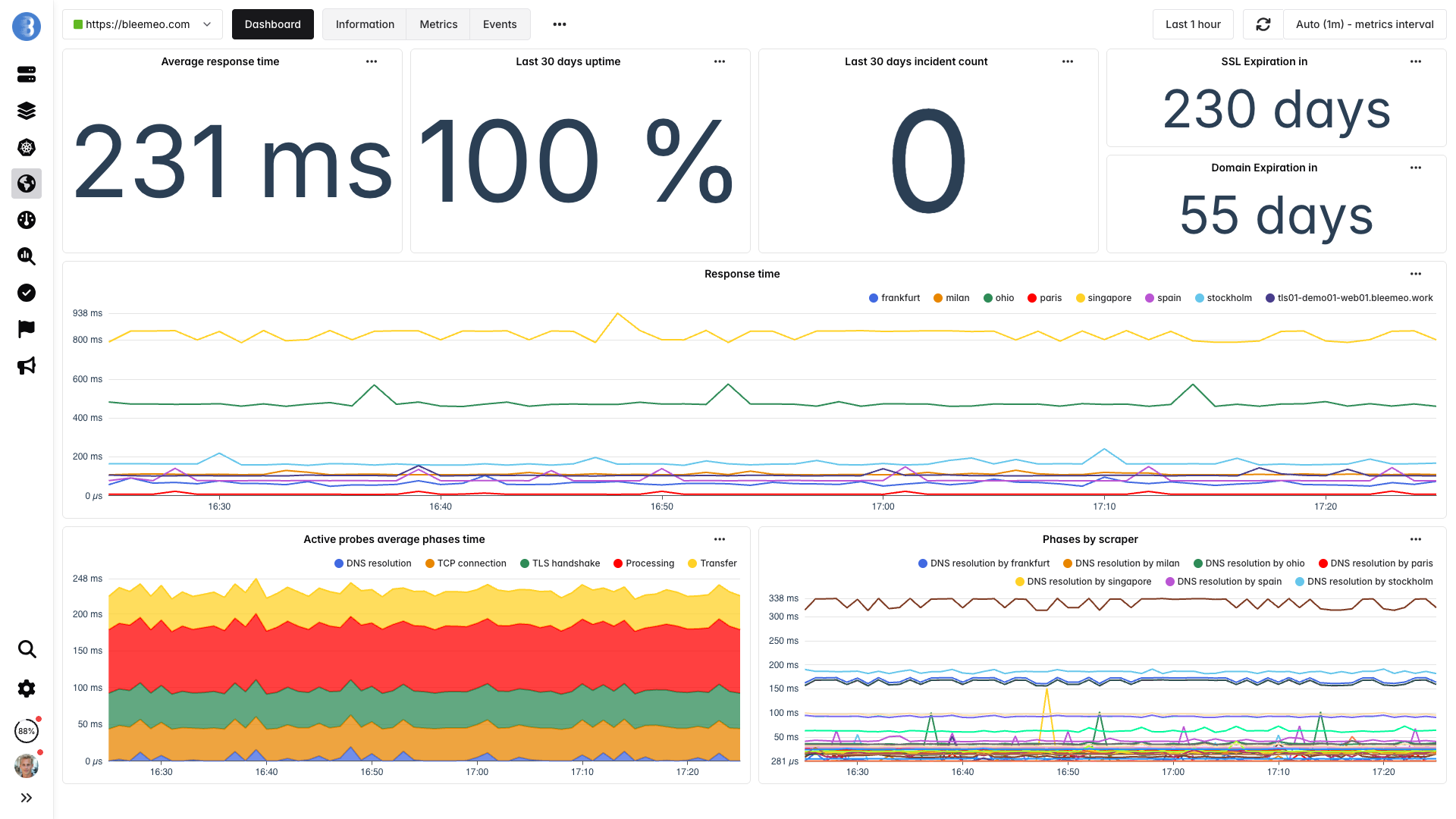
Learn more: Uptime Monitoring Features
Why external monitoring is critical for SaaS
Your servers might show green across the board, but a DNS issue, CDN misconfiguration, or certificate expiry can still block customers from reaching your product. Monitoring from 7 global locations sees what your customers see — and catches problems that internal health checks miss.
Get Alerted Before Your Customers Notice
Default alert rules are active immediately. Route notifications to where your team works — whether it's 2 PM or 2 AM.
Server issues
- High CPU usage
- Memory pressure
- Disk full
Database problems
- Slow queries
- Connection pool exhaustion
- Replication lag
Web server errors
- 5xx error spike
- High response time
- SSL expiration
Cache & uptime
- Redis/Memcached memory pressure
- Downtime from any location
- Message queue backlog
- Slack and Microsoft Teams
- Email (enabled by default)
- PagerDuty, OpsGenie, VictorOps
- SMS via Twilio or MessageBird
- Webhooks for custom integrations
Why smart defaults beat manual configuration
Writing effective alert rules requires deep knowledge of each service's failure modes. Bleemeo ships with battle-tested thresholds for every auto-detected service — so you're protected from minute one, without spending hours tuning alert conditions that might still miss the problem that actually matters.
What You Monitor Across Your SaaS Stack
Every layer of your infrastructure, covered automatically.
A SaaS product is a chain — and it's only as strong as its weakest link. A slow database query makes your API crawl. A full disk crashes your worker processes. A cache eviction spike hammers your database during a traffic surge. Bleemeo monitors every layer so you can see where problems start, not just where they surface.
Customer-facing layer
This is what your customers experience. If your API is slow or your login page is down, you need to know immediately — not from a support ticket an hour later.
- Uptime from 7 global locations
- Response time tracking
- SSL certificate monitoring
Web / Application layer
Your web server and application runtime handle every request. A misconfigured worker pool or a memory leak here affects every user of your product.
Data layer
- MySQL / PostgreSQL query performance
- Redis / Memcached hit rate & memory
- RabbitMQ / Kafka queue depth & throughput
Infrastructure layer
- CPU, memory, disk, network per server
- Docker container and Kubernetes pod metrics
- Log collection and search
The Cost of Not Monitoring
Downtime = Lost Revenue & Trust
For a SaaS with $50K MRR, even 1% downtime costs $500/month in direct SLA credits — not counting the customers who quietly churn. Bleemeo detects outages in under 60 seconds from 7 global locations, so you can start fixing in minutes, not hours.
Slow APIs = Lost Customers
Research shows 53% of users abandon a service if it takes more than 3 seconds to respond. Track response times across your API endpoints, web app, and webhooks — and get alerted before latency degrades to the point where customers look for alternatives.
Monitoring Costs < One Incident
Monitoring 10 servers with Bleemeo costs €109.90/month. That's less than the engineering time wasted debugging a single blind outage. Try the cost calculator.
Built for Growing SaaS Teams
Bleemeo is built for engineering teams that need to ship features, not maintain monitoring infrastructure. There's no Prometheus to configure, no Grafana dashboards to build, no alerting rules to write. Your team can set it up during a coffee break and get back to building the product your customers pay for.
Most SaaS companies run lean engineering teams. The same people who build product features also manage infrastructure, handle deployments, and respond to incidents. Bleemeo takes monitoring off that plate entirely — you get production-grade observability without hiring a dedicated SRE or spending weeks on tooling that isn't your core business.
See How It WorksTrusted by SaaS teams in production
Engineers and CTOs trust Bleemeo to monitor their infrastructure
During a short lunch break we installed Bleemeo, created a custom metric, tested alerts, and were ready for production. The speed of deployment is remarkable.

Bleemeo support is simply legendary — fast, knowledgeable, and always there when we need it.
Bleemeo was incredibly fast to deploy. In about an hour we rolled it out across more than 100 servers and immediately gained full visibility into our infrastructure.

We set up monitoring for all our servers in just a few hours. The dashboard is clear, powerful, and genuinely enjoyable to use.

We deployed Bleemeo across our server infrastructure in only a few hours. Uptime monitoring now alerts us instantly whenever a service encounters an issue.

Our Prometheus + Grafana stack had become a maintenance project. With Bleemeo we deployed the agent in minutes and finally focused on using monitoring instead of maintaining it.
After installing the agent, Bleemeo automatically discovered our databases, containers, and services. Within an hour we had full infrastructure visibility — no dashboards or exporters to build.
Bleemeo replaced several monitoring tools with a single platform. Metrics, alerts, and logs are now in one place, saving our team significant time.
Bleemeo gave us immediate insight into our infrastructure without the usual complexity. Within a couple of hours we had metrics, alerts, and dashboards running smoothly.
Setting up Bleemeo was refreshingly simple. The agent deployment took minutes and the automatic discovery saved us days of configuration.
Thanks to Bleemeo, our team now detects issues before our users notice them. The alerting is reliable and the interface makes troubleshooting much faster.
Moving to Bleemeo simplified our monitoring stack dramatically. Instead of managing multiple tools, everything we need is available in a single platform.
Centralizing our logs in Bleemeo drastically simplified troubleshooting. Instead of jumping between tools, we can now correlate metrics and logs instantly to understand what's happening.
Bleemeo made Kubernetes monitoring surprisingly easy. Within minutes we had visibility into our clusters, pods, and workloads without having to build complex dashboards ourselves.
Your SaaS Deserves Better Than Hoping for the Best
Get complete SaaS monitoring in 10 minutes. Know about problems before your customers do.
15-day free trial · No credit card required · Cancel anytime
Frequently Asked Questions
How long does it take to start monitoring my SaaS?
Most teams go from zero to full monitoring in under 10 minutes. Create an account, run one install command per server, and dashboards and alerts activate automatically as services are discovered.
Do I need to configure dashboards manually?
No. Bleemeo automatically creates dashboards for every discovered service — databases, web servers, caches, message brokers, and more. You get production-ready dashboards from minute one without writing any configuration.
What SaaS infrastructure components does Bleemeo monitor?
Bleemeo monitors servers, containers, Kubernetes clusters, databases (PostgreSQL, MySQL, MongoDB, Redis), web servers (Nginx, Apache), message brokers (RabbitMQ, Kafka), and 100+ other services. It also provides uptime monitoring and log management.
Can I monitor multi-region deployments from a single dashboard?
Yes. Install the agent on servers in any region or cloud provider. All data flows to the same Bleemeo dashboard, giving you a unified view across AWS, GCP, Azure, on-premise, and hybrid environments.
How does Bleemeo help me meet my SLAs?
Bleemeo provides uptime monitoring from 7 global locations, real-time alerting, and historical availability data. You can track response times, set thresholds aligned with your SLA targets, and get alerted before breaches happen.
Is the monitoring agent open source?
Yes. Glouton, Bleemeo's monitoring agent, is fully open source under the Apache 2.0 license. You can audit the code, contribute, and verify exactly what data is collected.
What alert channels are supported?
Bleemeo sends alerts via email, Slack, Microsoft Teams, PagerDuty, and webhooks. You can configure different channels for different severity levels, so critical issues reach on-call engineers immediately.
Can Bleemeo monitor my API endpoints?
Yes. Set up HTTP monitors for any URL — API endpoints, health checks, webhooks. Bleemeo checks availability and response time from multiple global locations every 60 seconds and alerts you if performance degrades or endpoints go down.
How does pricing work for a growing SaaS?
Bleemeo charges per server per month with no long-term commitment. As you scale up, add agents to new servers with a single command. Scale down by simply removing them. You only pay for what you actively monitor. See pricing details.
Can I integrate Bleemeo with my existing tools?
Yes. Bleemeo exposes a PromQL-compatible query interface, so you can keep your existing Grafana dashboards. It also integrates with Slack, Teams, PagerDuty, and provides a REST API for custom integrations into your CI/CD pipelines.