AI & Machine Learning
Bleemeo brings artificial intelligence and machine learning directly into your monitoring workflow — no data science expertise required. These features work out of the box, analyzing your metrics 24/7 to help your team move from reactive firefighting to proactive operations.
Why AI-Powered Monitoring Matters
Traditional monitoring relies on static thresholds: alert when CPU exceeds 90%, when memory drops below 10%, when disk usage crosses 80%. These rigid rules generate constant false positives because they cannot distinguish between a harmless nightly backup spike and a genuine runaway process. Teams learn to ignore alerts, and when a real problem surfaces, it gets lost in the noise.
Intelligent Anomaly Detection
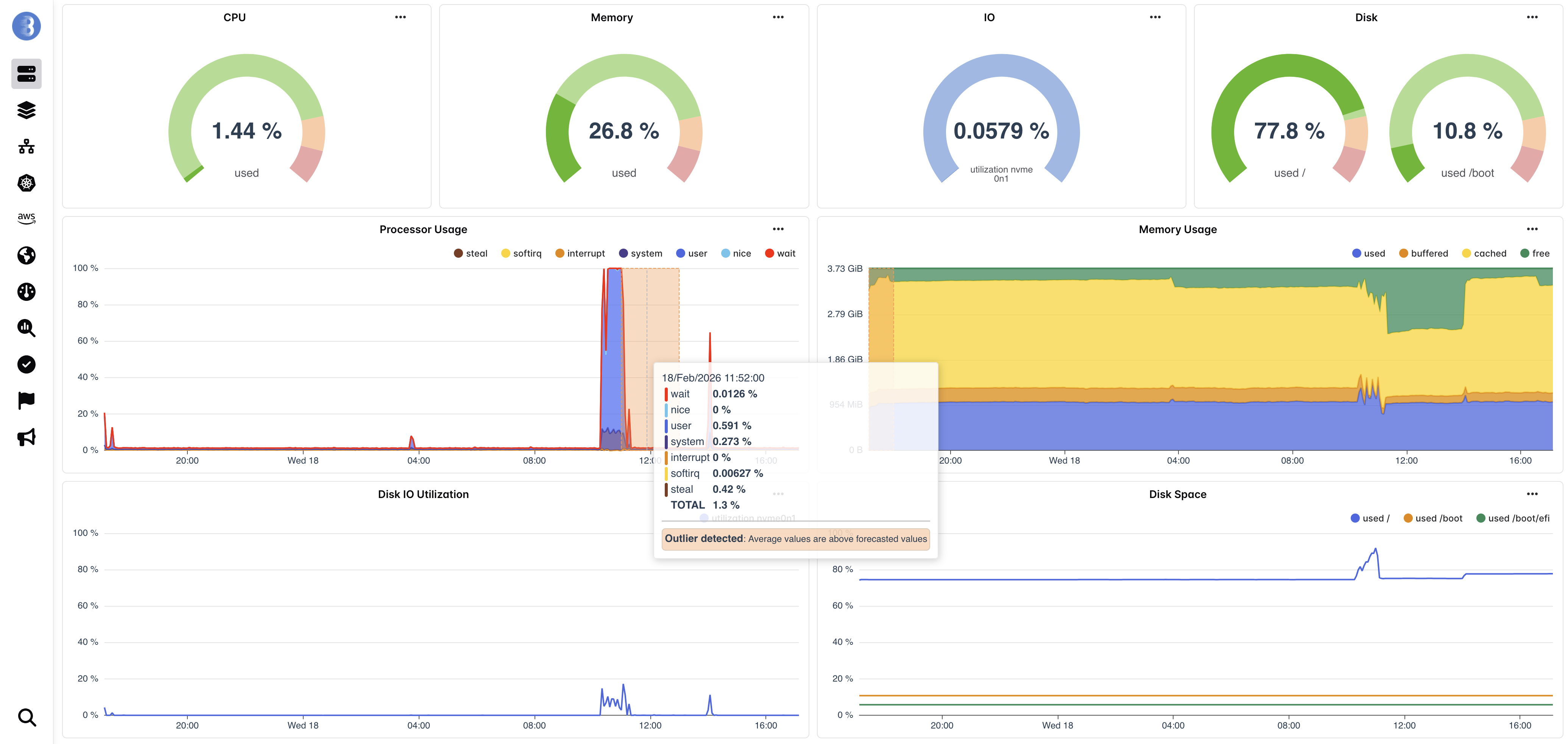
Instead of asking you to define what "normal" looks like for every metric on every server, Bleemeo's machine learning models learn it automatically. A neural network trained on your infrastructure's actual behavior generates probabilistic forecasts with confidence bounds that adapt to time-of-day patterns, weekly cycles, and seasonal trends. When a metric moves outside these dynamic bounds, you know something genuinely unusual is happening.
Predictive Capacity Planning
One of the most common causes of infrastructure outages is running out of disk space. Bleemeo fits linear regression models to 30 days of storage usage history and calculates exactly when each disk partition will reach warning, critical, and full thresholds. Instead of discovering a full disk at 3 AM when a database crashes, your team gets advance notice days or weeks ahead — with time to act.
Conversational Infrastructure
The Bleemeo MCP server bridges the gap between your monitoring data and modern AI assistants. Connect Claude Desktop, Cursor, VS Code, or Zed to your account and ask questions in natural language: "Which servers have critical alerts?", "What changed this week?" The MCP server provides read-only access to over 26 monitoring tools, transforming your platform into a conversation partner that understands your infrastructure.
How AI Enhances Your Monitoring
AI-Powered Capabilities
Neural Network Forecasting
A fine-tuned Amazon Chronos transformer model analyzes 7 days of metric history and generates probabilistic forecasts with confidence bounds. The model processes 32 prediction samples per metric to ensure stable, reliable bounds that adapt to your infrastructure's actual behavior rather than relying on static rules.
Predictive Capacity Planning
Linear regression models analyze 30 days of disk usage trends to calculate exactly when partitions will reach warning (80%), critical (90%), and full (100%) thresholds. Get multi-level advance alerts with precise timestamps — not vague warnings, but actionable forecasts like "this volume will be full on March 15th."
MCP Server for AI Assistants
Connect Claude Desktop, Cursor, VS Code, or Zed to your Bleemeo account and query your infrastructure using natural language. Over 26 read-only tools let AI assistants search agents, services, containers, events, logs, and audit trails — transforming monitoring data into a conversational experience.
Zero-Configuration Intelligence
AI features work out of the box with no manual setup. The system automatically selects relevant metrics, trains models on your data, runs predictions every 15 minutes, and delivers alerts when anomalies are detected. The underlying models have been fine-tuned on real-world infrastructure metrics for production-grade accuracy.
Reduced Alert Fatigue
Dynamic prediction bounds adapt to daily and weekly patterns, eliminating false positives caused by predictable load variations. Instead of alerting on a nightly backup CPU spike that happens every day, Bleemeo's AI recognizes the pattern as normal and only fires when genuinely unusual behavior is observed.
Continuous Learning
Models are re-evaluated every 15 minutes with fresh data, so predictions stay current as your infrastructure evolves. When you deploy new services, scale capacity, or change traffic patterns, the AI automatically adapts its forecasts to reflect the new normal within hours rather than requiring manual recalibration.
Anomaly Detection with Neural Networks
Bleemeo's anomaly detection engine is powered by a fine-tuned version of Amazon's Chronos-t5 model, a transformer-based architecture specifically designed for time-series forecasting. Unlike simple threshold checks that compare a metric against a fixed value, the Chronos model generates probabilistic predictions with high and low confidence bounds that reflect the expected range of behavior for each metric at each point in time.
The model operates on a 7-day context window, using 168 hours of historical metric data sampled at hourly intervals to produce 25-point forecasts. Each forecast represents the model's estimate of where the metric should be, along with confidence intervals that capture natural variation. When actual metric values consistently fall outside these bounds, Bleemeo triggers an anomaly alert that represents a statistically significant deviation from expected behavior — not just a metric crossing a number someone picked months ago.
- Probabilistic Confidence Bounds
Each prediction includes high and low bounds derived from 32 ensemble samples. The gap between bounds is automatically calibrated using the metric's standard deviation plus a configurable tolerance, ensuring alerts are sensitive enough to catch real problems without flagging normal variance.
- Resilient to Missing Data
Infrastructure metrics are not always perfectly continuous. Network outages, agent restarts, and maintenance windows create gaps. The Chronos model handles up to 90% missing data points gracefully, generating valid predictions even with sparse historical data by leveraging the transformer architecture's ability to attend to available context.
- Fine-Tuned on Real Infrastructure
The base Chronos model has been fine-tuned using real Bleemeo customer metrics, covering patterns like CPU utilization cycles, memory allocation trends, network throughput patterns, and disk I/O profiles. This domain-specific training produces significantly more accurate predictions than generic time-series models.
- Automatic Metric Selection
Bleemeo automatically identifies which metrics benefit from anomaly detection and configures forecasting without manual intervention. The minimum data requirement of 60 data points ensures predictions are only generated when sufficient history exists for meaningful analysis.
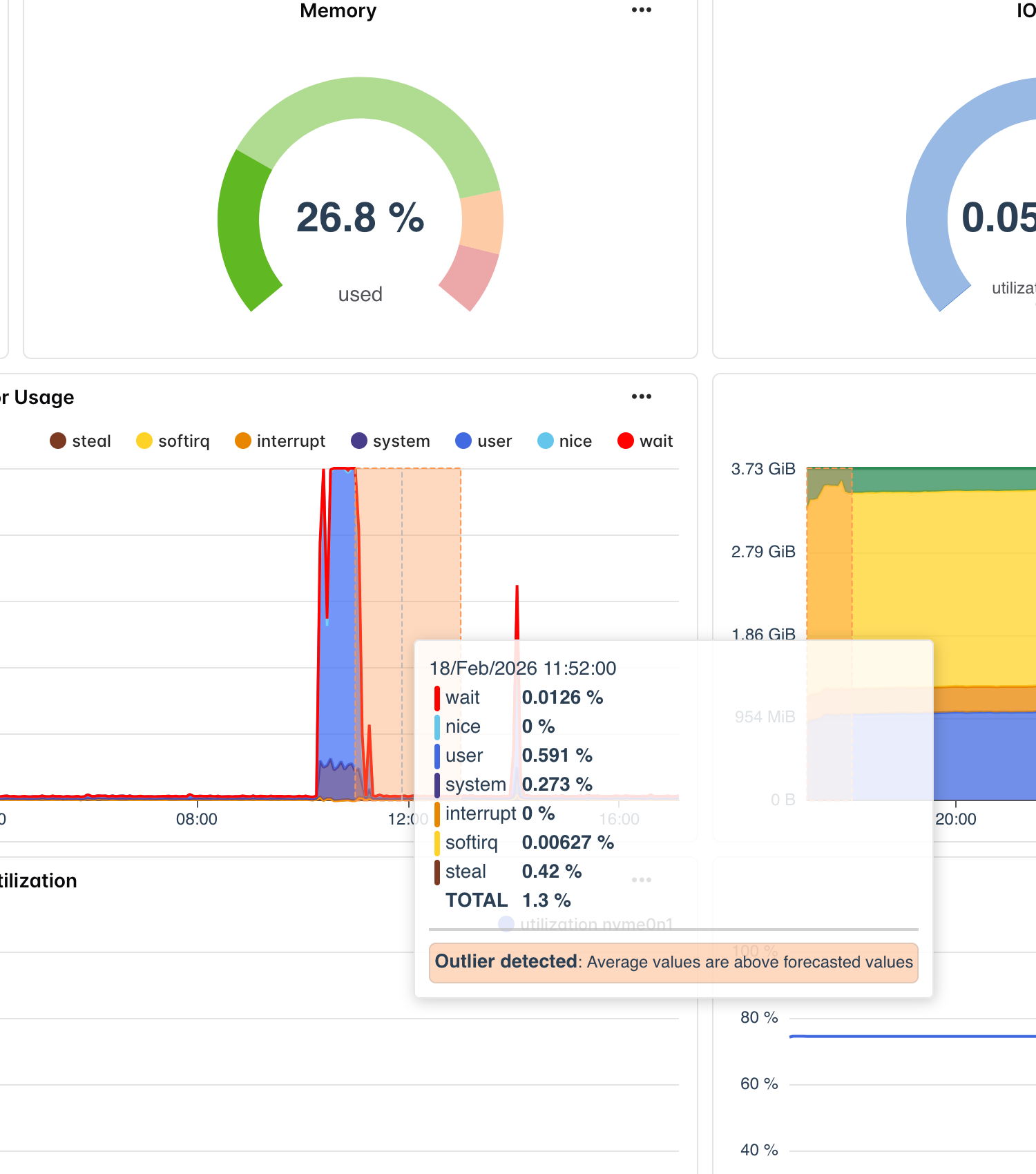
Disk Full Prediction
Running out of disk space remains one of the top causes of unexpected downtime. Databases crash, log files stop writing, applications fail with cryptic errors, and backups silently stop completing. The damage often extends far beyond the immediate outage — corrupted data, incomplete transactions, and cascading failures across dependent services. Yet disk exhaustion is almost always preventable with enough advance warning.
Bleemeo's disk full prediction system analyzes 30 days of storage usage history for every monitored partition and fits a linear regression model to project future growth. The model calculates the slope (growth rate per unit of time) and uses it to determine exactly when the partition will cross three configurable thresholds: warning at 80% capacity, critical at 90% capacity, and shortage at 100% capacity. Each prediction returns a specific ISO-8601 timestamp — not a vague "running low" warning, but an exact date like "this partition will reach 90% capacity on April 3rd, 2026 at 14:30 UTC."
- Three-Tier Threshold Predictions
Get advance warning at warning (80%), critical (90%), and shortage (100%) levels. Each threshold generates its own predicted timestamp, letting you prioritize response: plan cleanup at the warning stage, schedule expansion at the critical stage, and escalate at the shortage stage.
- Precise Timestamp Forecasts
Instead of approximate warnings, Bleemeo provides exact dates and times for when each threshold will be reached. This enables precise capacity planning — you know whether you have hours, days, or weeks to respond, and can plan accordingly without panic.
- 30-Day Trend Analysis
The model uses a full month of hourly data points to fit the regression, smoothing out daily fluctuations and capturing the true underlying growth trend. This long baseline produces stable, reliable predictions that are not skewed by temporary spikes from log rotation or cache invalidation.
- Automatic Coverage
Every monitored disk partition is automatically enrolled in predictive capacity planning. As soon as the Glouton agent starts reporting disk metrics, the forecasting system begins accumulating history and generating predictions — no per-server or per-partition configuration needed.
MCP Server: Talk to Your Infrastructure
Query your monitoring data using natural language through your favorite AI assistant
The Bleemeo MCP (Model Context Protocol) server connects your monitoring platform to the world of AI assistants. Once configured, you can ask questions about your infrastructure in plain English and receive instant, contextual answers backed by real-time monitoring data. There is no need to learn query languages, navigate complex dashboards, or write custom scripts — simply describe what you want to know, and the AI assistant queries Bleemeo on your behalf.
The MCP server exposes over 26 read-only tools that cover every aspect of your monitoring data. AI assistants can list all deployed agents and their status, retrieve service health details, check container metrics, query events and alerts, search across all resources globally, inspect audit logs, and even list invoices. All access is authenticated via OAuth and strictly read-only — the MCP server cannot create, modify, or delete any resources on your Bleemeo account, ensuring your infrastructure remains safe while enabling powerful AI-driven analysis.
Infrastructure Health
Ask your AI assistant "What is the overall health of my infrastructure?" and get a comprehensive summary of server statuses, active alerts, service availability, and resource utilization across your entire fleet. The MCP server queries agents, events, and services simultaneously to build a complete picture.
- List and inspect agents
- Query active events and alerts
- Check service health status
- Global search across resources
Troubleshooting & Analysis
During an incident, ask "Which services have critical alerts right now?" or "What changed in the last hour?" The AI assistant cross-references alert data, recent events, audit logs, and container statuses to help you identify root causes faster than navigating multiple dashboard views manually.
- Review logs from infrastructure
- Inspect container status and metrics
- Access audit trail of changes
- Examine healthcheck results
Conversational Monitoring
Go beyond simple queries with follow-up questions. Start with "Show me my Kubernetes agents" and then drill down: "Which one has the highest CPU usage?", "What services are running on that node?", "Are there any recent alerts for it?" The AI maintains context across the conversation.
- List agent types (AWS, K8s, SNMP)
- Retrieve agent facts and metadata
- List applications and details
- Query Glouton configuration
Supported AI Assistants
The MCP server integrates with the leading AI development tools. Authentication is handled via OAuth — launch the MCP connection, authorize in your browser, select your Bleemeo account, and you are ready to start querying. Each platform provides tool management to enable or disable specific capabilities.
- Claude Desktop (tools + prompts)
- Cursor (tools)
- Visual Studio Code (tools)
- Zed (tools)
Why AI Monitoring Helps Your Team
The real value of AI in monitoring is not the technology itself — it is the operational transformation it enables. Teams using Bleemeo's AI features consistently report fewer middle-of-the-night pages, shorter incident resolution times, and more effective capacity planning. Here is how each capability translates into concrete business outcomes.
Anomaly detection eliminates the guesswork of threshold tuning. Every SRE team has spent hours debating whether CPU alert should fire at 85% or 90%, only to have both values generate noise during predictable peaks. With AI-driven bounds, those debates disappear. The model learns that 95% CPU at 2 AM during the nightly ETL job is normal, while 75% CPU at noon on a Tuesday is unusual. Your team responds to the alerts that matter and ignores the ones that do not, without touching a single threshold configuration.
Disk full prediction turns reactive scrambling into planned maintenance. The average cost of a disk-full outage is not just the downtime — it includes data recovery, transaction replay, customer impact, and the post-mortem investigation. Bleemeo transforms this from an emergency into a scheduled task. When you know a volume will reach capacity on March 15th, you can order storage, schedule expansion during a maintenance window, or implement retention policies — all during business hours with zero customer impact.
The MCP server makes monitoring accessible to everyone on the team. Not everyone on a team speaks PromQL or knows where to find the right dashboard during an incident. With conversational access to monitoring data, a product manager can check service health, a developer can investigate deployment impact, and an on-call engineer can triage alerts — all using natural language. This democratizes operational intelligence without requiring everyone to become a monitoring expert.
Want to go further? Learn how to configure the MCP server with your AI assistant, understand anomaly detection thresholds, and set up disk full prediction alerts.
Read the DocumentationFrequently Asked Questions
Everything you need to know about Bleemeo's AI and machine learning features
What AI and machine learning features does Bleemeo offer?
Bleemeo offers three core AI/ML features: neural network-based anomaly detection using a fine-tuned transformer model, predictive capacity planning with disk full forecasting using linear regression, and an MCP server that lets you query your monitoring data through AI assistants like Claude Desktop, Cursor, and VS Code. All features work automatically with zero configuration.
How does Bleemeo's anomaly detection work?
Bleemeo uses a fine-tuned Amazon Chronos transformer model to analyze 7 days of historical metric data and generate probabilistic forecasts with confidence bounds. The model produces 32 prediction samples per metric to ensure stable bounds. When actual values fall outside the predicted range, an anomaly is detected. The model runs every 15 minutes and handles up to 90% missing data points.
How far in advance can Bleemeo predict a disk full event?
Bleemeo analyzes 30 days of disk usage trends using linear regression to project when storage will reach warning (80%), critical (90%), and full (100%) thresholds. Depending on the growth rate, predictions can range from days to months in advance, with specific ISO-8601 timestamps for each threshold crossing.
What is the Bleemeo MCP server?
The Bleemeo MCP server implements the Model Context Protocol, allowing AI assistants to query your monitoring data using natural language. It provides 26+ read-only tools covering agents, services, containers, events, logs, and audit trails. Authentication uses OAuth, and all access is strictly read-only for security.
Which AI assistants are compatible with the MCP server?
The Bleemeo MCP server supports Claude Desktop (full support with tools and prompts), Cursor (tools only), Visual Studio Code (tools only), and Zed (tools only). Each platform provides tool management to enable or disable specific capabilities as needed.
Is the MCP server access read-only?
Yes, the Bleemeo MCP server is entirely read-only. It can query and retrieve data — metrics, alerts, logs, events, configurations, and audit trails — but it cannot create, modify, or delete any resources on your Bleemeo account. This design ensures your infrastructure remains completely safe while enabling powerful AI-driven analysis.
Do I need to configure anything for anomaly detection?
No. Bleemeo's anomaly detection works out of the box with zero configuration. The system automatically selects appropriate metrics, collects historical data, runs predictions every 15 minutes, and generates alerts when anomalies are detected. The underlying model has been fine-tuned on real infrastructure metrics for optimal accuracy.
What machine learning models does Bleemeo use?
Bleemeo uses two complementary models: a fine-tuned Amazon Chronos-t5 transformer for probabilistic time-series forecasting and anomaly detection, and a linear regression model optimized for capacity planning and disk full prediction. The Chronos model uses PyTorch and Hugging Face Transformers for neural network inference.
How does AI-powered monitoring reduce alert fatigue?
Traditional threshold-based alerts fire on fixed values that ignore normal variations. Bleemeo's AI learns your infrastructure's actual patterns — daily cycles, weekly trends, seasonal changes — and only alerts when behavior genuinely deviates from the predicted range. This eliminates false positives from expected load spikes, nightly jobs, and routine batch processing.
Which Bleemeo plans include AI and ML features?
The MCP server is available on Free, Starter, and Professional plans. Anomaly detection and predictive capacity planning are available on Starter and Professional plans. All features work automatically without additional configuration, setup, or extra costs beyond the plan subscription.
Start Monitoring with AI Intelligence
Anomaly detection, capacity predictions, and conversational monitoring — all active from day one. Start your free 15-day trial with full AI feature access and see how machine learning transforms your infrastructure operations.