A Managed Alternative to Self-Hosted Prometheus
Prometheus is the standard for metrics, but running it in production means managing Alertmanager, Grafana, long-term storage, and capacity planning. Bleemeo gives you the same visibility with zero servers to provision and zero midnight pages about your monitoring stack.
15-day free trial • No credit card required • Predictable pricing always
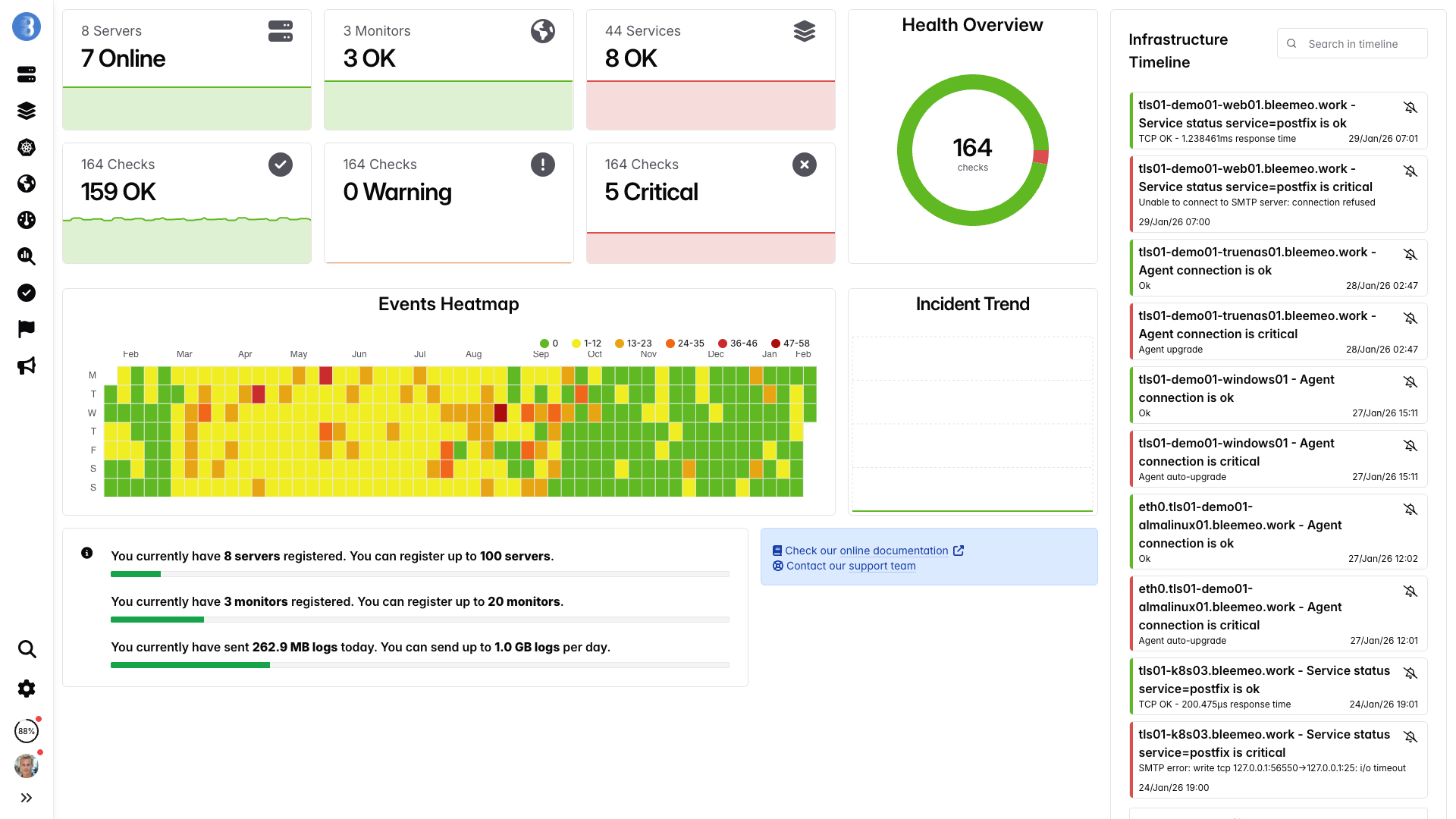
Real-time dashboards, ready in minutes — no configuration needed
Common Prometheus Challenges
Infrastructure Overhead
Running Prometheus at scale means maintaining multiple Prometheus instances, configuring federation or sharding, and building pipelines to move data between components. Each additional instance requires its own resource allocation, scrape configuration, and recording rules—creating an operational burden that grows linearly with your infrastructure.
Storage Complexity
Prometheus defaults to just 15 days of retention, which means any historical analysis or capacity planning requires a separate long-term storage solution. Thanos, Cortex, and Mimir each solve this problem but introduce their own architecture, object storage dependencies, and compaction processes that need careful tuning and monitoring.
Dashboard & Alert Setup
Prometheus ships with only a basic expression browser—no built-in dashboards or polished UI. You need Grafana for visualization and Alertmanager for notifications, both of which require manual setup. Every dashboard panel, every alerting rule, and every recording rule must be written by hand in PromQL and maintained through version control as your infrastructure evolves.
Scaling Challenges
High cardinality metrics from dynamic environments like Kubernetes can cause sudden memory spikes and OOM kills that take down your entire monitoring stack. Scaling Prometheus requires sharding across multiple instances or setting up federation hierarchies, and retention policies must be carefully balanced against available disk space. Capacity planning becomes a recurring task that pulls engineers away from product work.
Prometheus vs Bleemeo
| Feature | Prometheus (self-hosted) | Bleemeo |
|---|---|---|
| Setup Time | Hours to days of configuration | 5 minutes, one command |
| Infrastructure Required | Prometheus + Alertmanager + Grafana + storage | None — fully managed SaaS |
| Long-term Storage | Thanos/Cortex/Mimir required | 13 months included |
| Service Discovery | Manual scrape config per target | Automatic, zero config |
| Dashboards | Build in Grafana from scratch | Pre-built, auto-activated |
| Alert Rules | Write and maintain PromQL rules | Smart defaults + ML anomaly detection |
| High Availability | Duplicate stacks + federation | Built-in redundancy |
| Maintenance | Upgrades, scaling, troubleshooting | Zero — we handle everything |
| Network Model | Pull-based: requires network access to all targets | Push-based: agents send data outbound, no inbound ports needed |
| Cardinality Management | High cardinality causes memory pressure and OOM kills | Managed server-side with automatic cardinality controls |
| Log Management | Not included — requires Loki or separate stack | Built-in log collection and search alongside metrics |
| PromQL Compatibility | Native | Prometheus-compatible metrics |
| Open Source Agent | Prometheus exporters | Glouton (Apache 2.0) |
Real Cost Comparison
For a typical 100-server infrastructure with self-hosted Prometheus, the true cost extends far beyond compute and storage — it includes the engineering hours spent maintaining, troubleshooting, and scaling your monitoring stack instead of building product features.
Prometheus (self-hosted)
*Plus hidden costs: on-call fatigue, knowledge silos, and opportunity cost of engineers not working on product
Bleemeo
*With 1-year reservation. No infrastructure costs.
Why Teams Choose Bleemeo
Zero Infrastructure
No Prometheus servers to maintain, no Thanos clusters to babysit, no Grafana instances to upgrade, and no object storage buckets to manage. Bleemeo handles all the infrastructure so your team can focus on building product features instead of keeping the monitoring stack alive. You never have to worry about disk space, memory pressure, or OOM kills in your observability layer again.
Prometheus Compatible
Glouton scrapes Prometheus exporters directly and keeps your existing exporters and instrumentation code untouched. Bleemeo supports the same Prometheus-compatible metric formats and labels you already use, making it a drop-in replacement for your Prometheus backend without rewriting a single recording rule or relabeling config.
Automatic Discovery
Unlike Prometheus, which requires manual scrape configuration for every new target, Bleemeo's agent Glouton automatically detects running services — databases, web servers, message brokers, and more — and starts collecting the right metrics immediately. No YAML editing, no service discovery plugins, no relabeling rules to maintain.
Pre-built Everything
While Prometheus gives you a blank expression browser, Bleemeo provides rich pre-built dashboards, smart alerting thresholds, and ML-powered anomaly detection that activate automatically the moment a service is discovered. No more spending days crafting Grafana panels or writing PromQL alerting rules from scratch for each new application you deploy.
Open Source Agent
Glouton, our monitoring agent, is fully open source under the Apache 2.0 license. You can audit every line of code running on your servers, contribute improvements, and rest assured there is no vendor lock-in. Your metrics data remains yours, and you can export it at any time using standard Prometheus formats.
European Data Residency
All your monitoring data is stored in European data centers with full GDPR compliance built in from day one. Unlike US-based SaaS alternatives, Bleemeo is a European company that keeps your infrastructure telemetry under EU jurisdiction, giving you straightforward compliance for data residency requirements.
Feature Parity Where It Matters
Infrastructure Monitoring
Comprehensive CPU, memory, disk, network, and process monitoring with automatic service discovery that detects databases, web servers, and application runtimes without any configuration. Get deeper visibility than standard Prometheus node_exporter metrics out of the box.
Container & Kubernetes
Native Docker and Kubernetes support with pod-level metrics, node health monitoring, and cluster-wide overviews. Unlike Prometheus, which requires kube-state-metrics, cAdvisor, and complex relabeling rules, Bleemeo provides container monitoring that works immediately after agent installation.
Log Management
Collect, index, and search logs alongside your metrics in a single unified platform. Prometheus has no log management at all — teams typically bolt on Loki, Elasticsearch, or Splunk as yet another system to manage. With Bleemeo, logs and metrics live together, making root cause analysis faster and simpler.
Intelligent Alerting
Machine-learning-based anomaly detection identifies unusual patterns before they become outages, complementing pre-configured alert thresholds for every discovered service. No more manually writing and tuning PromQL alerting rules or maintaining Alertmanager routing trees — intelligent defaults cover the common cases while you customize what matters most.
Custom Dashboards
Build the exact views your team needs with intuitive drag-and-drop widgets, or start from the rich library of pre-built dashboards that activate automatically. Unlike Grafana, where every panel requires manual PromQL queries and JSON configuration, Bleemeo dashboards are ready to use the moment your agents connect.
Uptime Monitoring
HTTP, TCP, and ICMP uptime checks from multiple global locations, with SSL certificate expiry monitoring and response time tracking. Prometheus blackbox_exporter provides basic probing, but Bleemeo offers a fully managed, multi-location approach with built-in alerting and status pages that require no infrastructure on your side.
Migrating from Prometheus
Most teams run both systems in parallel for a few weeks before fully switching. The migration is straightforward and non-disruptive — Bleemeo agents run alongside your existing Prometheus setup without conflict. Our team is available to help with migration planning and validation at every step.
Deploy Bleemeo Agents
Install the Bleemeo agent alongside your existing Prometheus exporters with a single command. The agent runs independently and does not interfere with your current monitoring stack, so there is zero risk during the transition period:
wget -qO- 'https://get.bleemeo.com?accountId=...' | sudo bashVerify Discovery
Open the Bleemeo dashboard and verify that all your servers and services have been automatically detected. Compare the discovered services list against your Prometheus scrape targets to confirm full coverage. Glouton identifies databases, web servers, message brokers, and application runtimes without any configuration files.
Configure Custom Exporters (optional)
If you have custom Prometheus exporters or application-level instrumentation, configure Glouton to scrape their endpoints directly. This gives you a unified view of both agent-collected and exporter-scraped metrics in a single platform, while preserving your existing labels and metric names.
Validate Dashboards
Review the pre-built Bleemeo dashboards and compare them side by side with your existing Grafana panels. Confirm that the metrics, time ranges, and granularity match your operational needs. Most teams find that Bleemeo's automatic dashboards cover their key use cases without any customization required.
Set Up Notifications
Set up your preferred notification channels — Slack, PagerDuty, email, Microsoft Teams, or custom webhooks — to replace your Alertmanager routing configuration. Bleemeo's alerting comes with sensible default thresholds already active for every discovered service, so you are covered from the start while you fine-tune notification preferences.
Decommission Prometheus Stack
Once you have validated that Bleemeo provides full coverage and your team is comfortable with the new dashboards and alerting, decommission your self-hosted Prometheus servers, Alertmanager clusters, Grafana instances, and Thanos or Mimir storage backends. Reclaim the compute resources and free your engineering team from monitoring-stack maintenance permanently.
What Our Customers Say
Engineers and CTOs trust Bleemeo to monitor their infrastructure
During a short lunch break we installed Bleemeo, created a custom metric, tested alerts, and were ready for production. The speed of deployment is remarkable.

Bleemeo support is simply legendary — fast, knowledgeable, and always there when we need it.
Bleemeo was incredibly fast to deploy. In about an hour we rolled it out across more than 100 servers and immediately gained full visibility into our infrastructure.

We set up monitoring for all our servers in just a few hours. The dashboard is clear, powerful, and genuinely enjoyable to use.

We deployed Bleemeo across our server infrastructure in only a few hours. Uptime monitoring now alerts us instantly whenever a service encounters an issue.

Our Prometheus + Grafana stack had become a maintenance project. With Bleemeo we deployed the agent in minutes and finally focused on using monitoring instead of maintaining it.
After installing the agent, Bleemeo automatically discovered our databases, containers, and services. Within an hour we had full infrastructure visibility — no dashboards or exporters to build.
Bleemeo replaced several monitoring tools with a single platform. Metrics, alerts, and logs are now in one place, saving our team significant time.
Bleemeo gave us immediate insight into our infrastructure without the usual complexity. Within a couple of hours we had metrics, alerts, and dashboards running smoothly.
Setting up Bleemeo was refreshingly simple. The agent deployment took minutes and the automatic discovery saved us days of configuration.
Thanks to Bleemeo, our team now detects issues before our users notice them. The alerting is reliable and the interface makes troubleshooting much faster.
Moving to Bleemeo simplified our monitoring stack dramatically. Instead of managing multiple tools, everything we need is available in a single platform.
Centralizing our logs in Bleemeo drastically simplified troubleshooting. Instead of jumping between tools, we can now correlate metrics and logs instantly to understand what's happening.
Bleemeo made Kubernetes monitoring surprisingly easy. Within minutes we had visibility into our clusters, pods, and workloads without having to build complex dashboards ourselves.
See Bleemeo in action
Watch how teams go from install to full monitoring in under 5 minutes
Frequently Asked Questions
Can Bleemeo replace a self-hosted Prometheus stack?
Yes. Bleemeo collects the same infrastructure metrics, natively scrapes Prometheus exporters for custom metrics, and includes dashboards, alerting, and 13 months of storage — without running any servers.
Does Bleemeo support PromQL?
Glouton, the Bleemeo agent, scrapes Prometheus exporters natively using the standard exposition format. Your existing exporters and instrumentation work out of the box.
What about long-term storage?
Bleemeo stores metrics at full resolution for 13 months, included in the base price. No need for Thanos, Cortex, or Mimir.
Is the Bleemeo agent open source?
Yes. Glouton is Apache 2.0 licensed and supports automatic service discovery for 100+ services — no scrape configs needed.
Does Bleemeo support custom metrics from Prometheus exporters?
Yes. Glouton natively scrapes any Prometheus exporter endpoint. Your existing exporters and custom instrumentation work without modification.
What about alerting without Alertmanager?
Bleemeo includes pre-configured alert thresholds for every discovered service, plus ML-based anomaly detection. Notifications via email, Slack, PagerDuty, and webhooks — no Alertmanager to configure.
Is there a free tier?
Yes. Monitor up to 3 servers for free with no time limit. All features included — dashboards, alerts, service discovery.
Can I keep some Prometheus instances running alongside Bleemeo?
Yes. Many teams run both during migration. Glouton operates independently and doesn't interfere with existing Prometheus scraping.
Ready to Stop Maintaining Your Monitoring Stack?
Stop spending engineering hours on Prometheus upgrades, Thanos compaction issues, and Grafana dashboard maintenance. Get production-ready monitoring with 13 months of retention, automatic service discovery, and intelligent alerting — all without a single server to manage.
No credit card required • Free tier available • Cancel anytime