

Construit sur Prometheus & OpenTelemetry
Sans verrouillage fournisseur
Chaque minute d'indisponibilité érode la confiance de vos clients et votre chiffre d'affaires. Obtenez une visibilité complète sur vos serveurs, bases de données, API et disponibilité — avant que vos clients ne remarquent un problème.
15-day free trialNo credit card requiredNo long-term commitment
Sans verrouillage fournisseur
Données hébergées dans l'UE · Conforme RGPD
À travers l'Europe et au-delà
Le problème
Le coût moyen d'une indisponibilité IT est de 5 600 $ par minute pour les entreprises de taille moyenne. Pour un produit SaaS, ce n'est pas seulement du chiffre d'affaires perdu — ce sont des clients qui partent, des intégrations cassées et des pénalités SLA. Une seule panne prolongée peut annuler des mois d'acquisition client.
Configurer Prometheus, Grafana, Alertmanager et le stockage long terme prend des semaines. Ensuite, il faut le maintenir, le mettre à jour et écrire des règles d'alerte pour chaque service. C'est du temps d'ingénierie qui n'est pas consacré à construire votre produit.
Bleemeo vous offre un monitoring complet de l'infrastructure — serveurs, bases de données, serveurs web, caches, files de messages et disponibilité — en 10 minutes, sans aucune configuration. Soyez informé des problèmes avant que vos clients n'ouvrent un ticket support.
Que vous exécutiez un monolithe sur un seul serveur ou une architecture microservices répartie sur plusieurs clouds, Bleemeo s'adapte automatiquement à votre stack. Vous obtenez les métriques serveur, les performances de base de données, l'efficacité du cache et le monitoring de disponibilité externe — le tout depuis un seul agent et un seul tableau de bord, avec des alertes qui fonctionnent immédiatement.
Mise en place
Votre équipe d'ingénierie peut le configurer pendant une pause café.
Une commande par serveur. L'agent Glouton de Bleemeo découvre automatiquement l'ensemble de votre stack SaaS : serveur web, runtime applicatif, base de données, cache, broker de messages et moteur de recherche.
wget -qO- 'https://get.bleemeo.com?accountId=...'Exécutez cette commande sur chaque serveur de votre stack. L'agent détecte tout ce qui tourne sur la machine — aucun fichier de configuration à écrire.
Les stacks SaaS évoluent rapidement — de nouveaux services sont déployés, des conteneurs sont remplacés, les dépendances changent. Configurer manuellement le monitoring pour chaque composant prend des heures de YAML avec le risque constant d'angles morts. Bleemeo détecte chaque service sur votre machine en quelques secondes, pour que rien ne passe entre les mailles du filet — même quand votre architecture évolue.
Surveillez vos URLs les plus importantes depuis 7 emplacements mondiaux. Bleemeo vérifie la disponibilité, le temps de réponse, l'expiration des certificats SSL et la validation du contenu toutes les 60 secondes.
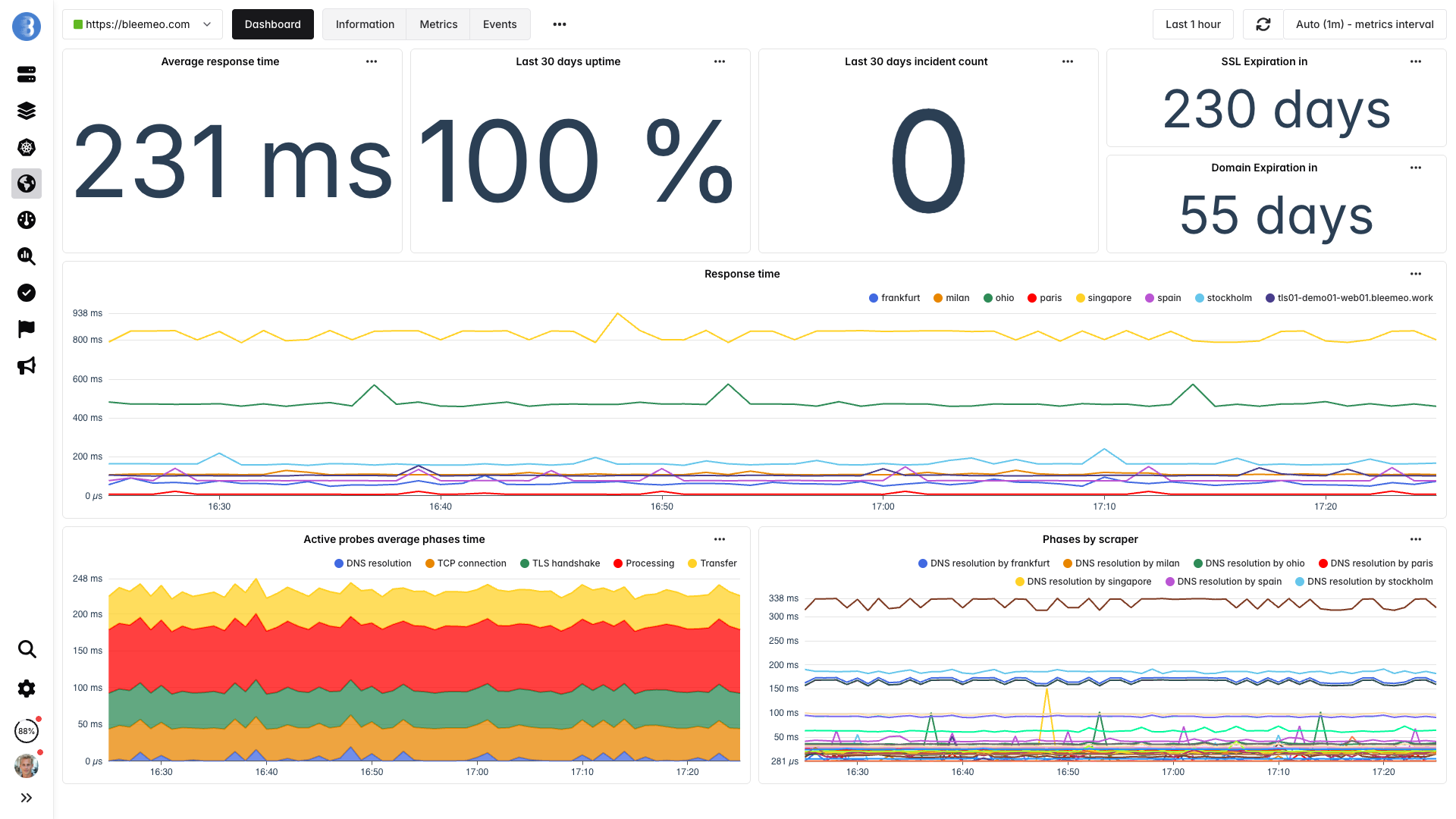
En savoir plus : Fonctionnalités de monitoring de disponibilité
Vos serveurs peuvent afficher du vert partout, mais un problème DNS, une mauvaise configuration CDN ou une expiration de certificat peut quand même empêcher vos clients d'accéder à votre produit. Le monitoring depuis 7 emplacements mondiaux voit ce que vos clients voient — et détecte les problèmes que les health checks internes ne captent pas.
Les règles d'alerte par défaut sont actives immédiatement. Envoyez les notifications là où votre équipe travaille — que ce soit à 14h ou à 2h du matin.
Écrire des règles d'alerte efficaces nécessite une connaissance approfondie des modes de défaillance de chaque service. Bleemeo est livré avec des seuils éprouvés pour chaque service auto-détecté — vous êtes protégé dès la première minute, sans passer des heures à ajuster des conditions d'alerte qui pourraient quand même manquer le vrai problème.
Votre stack
Chaque couche de votre infrastructure, couverte automatiquement.
Un produit SaaS est une chaîne — et elle n'est aussi solide que son maillon le plus faible. Une requête de base de données lente fait ramer votre API. Un disque plein fait planter vos processus worker. Un pic d'évictions de cache surcharge votre base de données lors d'un pic de trafic. Bleemeo supervise chaque couche pour que vous puissiez voir où les problèmes commencent, pas seulement où ils se manifestent.
C'est ce que vos clients expérimentent. Si votre API est lente ou votre page de connexion est en panne, vous devez le savoir immédiatement — pas via un ticket support une heure plus tard.
Votre serveur web et votre runtime applicatif traitent chaque requête. Un pool de workers mal configuré ou une fuite mémoire ici affecte chaque utilisateur de votre produit.
Impact
Pour un SaaS avec 50K$ de MRR, même 1% d'indisponibilité coûte 500 $/mois en crédits SLA directs — sans compter les clients qui partent silencieusement. Bleemeo détecte les pannes en moins de 60 secondes depuis 7 emplacements mondiaux, pour que vous puissiez corriger en minutes, pas en heures.
Les études montrent que 53% des utilisateurs abandonnent un service s'il met plus de 3 secondes à répondre. Suivez les temps de réponse sur vos endpoints API, votre application web et vos webhooks — et soyez alerté avant que la latence ne se dégrade au point où vos clients cherchent des alternatives.
Superviser 10 serveurs avec Bleemeo coûte €109,90/mois. C'est moins que le temps d'ingénierie perdu à déboguer une seule panne à l'aveugle. Essayez le calculateur de coûts.
Sans DevOps
Bleemeo est conçu pour les équipes d'ingénierie qui doivent livrer des fonctionnalités, pas maintenir une infrastructure de monitoring. Pas de Prometheus à configurer, pas de tableaux de bord Grafana à construire, pas de règles d'alerte à écrire. Votre équipe peut le configurer pendant une pause café et se remettre à construire le produit pour lequel vos clients paient.
La plupart des entreprises SaaS ont des équipes d'ingénierie réduites. Les mêmes personnes qui développent les fonctionnalités gèrent aussi l'infrastructure, les déploiements et répondent aux incidents. Bleemeo retire entièrement le monitoring de cette charge — vous obtenez une observabilité de niveau production sans embaucher un SRE dédié ni passer des semaines sur des outils qui ne sont pas votre cœur de métier.
Voir comment ça marcheIngénieurs et CTO font confiance à Bleemeo pour surveiller leur infrastructure
Nous avons besoin que nos équipes restent concentrées sur notre métier — l'affichage dynamique — plutôt que sur la surveillance d'infrastructure. Bleemeo supervise l'ensemble de notre environnement, du dédié à Azure, et libère nos équipes des alertes inutiles tout en garantissant notre qualité de service.

Bleemeo nous accompagne depuis des années : une supervision simple et fiable, essentielle pour la qualité de service que nous devons à nos clients.

On-premise ou cloud, Bleemeo supervise les clusters Kubernetes de mes clients sans complexité. Un outil que je recommande pour sa simplicité et la clarté qu'il apporte.

Client depuis le premier jour, je suis ravi de Bleemeo. C'est facile à installer, efficace, et ça ne cesse de s'améliorer !

Pendant une courte pause déjeuner, nous avons installé Bleemeo, créé une métrique personnalisée, testé les alertes et étions prêts pour la production. La rapidité de déploiement est remarquable.

Le support Bleemeo est tout simplement légendaire — rapide, compétent et toujours présent quand on en a besoin.

Le déploiement de Bleemeo a été incroyablement rapide. En environ une heure, nous l'avons déployé sur plus de 100 serveurs et avons immédiatement obtenu une visibilité complète sur notre infrastructure.

Nous avons mis en place le monitoring de tous nos serveurs en quelques heures seulement. Le tableau de bord est clair, puissant et véritablement agréable à utiliser.

Nous avons déployé Bleemeo sur l'ensemble de notre infrastructure serveur en quelques heures seulement. Le monitoring de disponibilité nous alerte désormais instantanément dès qu'un service rencontre un problème.

Obtenez un monitoring SaaS complet en 10 minutes. Soyez informé des problèmes avant vos clients.
Essai gratuit de 15 jours · Sans carte bancaire · Annulation à tout moment
La plupart des équipes passent de zéro à une supervision complète en moins de 10 minutes. Créez un compte, exécutez une commande d'installation par serveur, et les tableaux de bord et alertes s'activent automatiquement à mesure que les services sont découverts.
Non. Bleemeo crée automatiquement des tableaux de bord pour chaque service découvert — bases de données, serveurs web, caches, brokers de messages, et plus encore. Vous obtenez des tableaux de bord prêts pour la production dès la première minute sans écrire aucune configuration.
Bleemeo supervise les serveurs, conteneurs, clusters Kubernetes, bases de données (PostgreSQL, MySQL, MongoDB, Redis), serveurs web (Nginx, Apache), brokers de messages (RabbitMQ, Kafka), et plus de 100 autres services. Il fournit également la supervision de disponibilité et la gestion des logs.
Oui. Installez l'agent sur des serveurs dans n'importe quelle région ou fournisseur cloud. Toutes les données convergent vers le même tableau de bord Bleemeo, vous offrant une vue unifiée entre AWS, GCP, Azure, on-premise et environnements hybrides.
Bleemeo fournit une supervision de disponibilité depuis 7 emplacements mondiaux, des alertes en temps réel et des données historiques de disponibilité. Vous pouvez suivre les temps de réponse, définir des seuils alignés sur vos objectifs SLA et être alerté avant que les violations ne se produisent.
Oui. Glouton, l'agent de supervision de Bleemeo, est entièrement open source sous licence Apache 2.0. Vous pouvez auditer le code, contribuer et vérifier exactement quelles données sont collectées.
Bleemeo envoie des alertes par email, Slack, Microsoft Teams, PagerDuty et webhooks. Vous pouvez configurer différents canaux pour différents niveaux de sévérité, afin que les problèmes critiques atteignent immédiatement les ingénieurs d'astreinte.
Oui. Configurez des moniteurs HTTP pour n'importe quelle URL — endpoints API, health checks, webhooks. Bleemeo vérifie la disponibilité et le temps de réponse depuis plusieurs emplacements mondiaux toutes les 60 secondes et vous alerte si les performances se dégradent ou si les endpoints tombent.
Bleemeo facture par serveur par mois sans engagement long terme. À mesure que vous évoluez, ajoutez des agents sur de nouveaux serveurs avec une seule commande. Réduisez en les supprimant simplement. Vous ne payez que ce que vous supervisez activement. Voir les détails des tarifs.
Oui. Bleemeo expose une interface de requête compatible PromQL, vous permettant de conserver vos tableaux de bord Grafana existants. Il s'intègre également avec Slack, Teams, PagerDuty et fournit une API REST pour des intégrations personnalisées dans vos pipelines CI/CD.