

Construit sur Prometheus & OpenTelemetry
Sans verrouillage fournisseur
Envoyez vos métriques en 30 secondes, interrogez avec tout le PromQL
Bleemeo est un logiciel de monitoring Prometheus hébergé — un Prometheus cloud géré avec compatibilité PromQL complète, 13 mois de rétention et un SLA de 99,99 %. Pas de Thanos à opérer, pas de Cortex à maintenir, pas de Mimir à scaler. Utilisez l'outil Prometheus que vous connaissez déjà, sans gérer vous-même le stockage, le scaling ou l'infrastructure d'alerting.
Essai gratuit 15 joursSans carte bancaireSans engagement
Sans verrouillage fournisseur
Données hébergées dans l'UE · Conforme RGPD
À travers l'Europe et au-delà
Plus de 500 entreprises font confiance à Bleemeo pour surveiller leur infrastructure
Le défi
Le disque local se remplit vite avec des métriques à haute cardinalité. Les solutions externes comme Thanos, Cortex ou Mimir ajoutent une complexité opérationnelle significative et nécessitent du temps d'ingénierie dédié.
À mesure que votre infrastructure grandit, les instances Prometheus individuelles atteignent les limites de mémoire et de CPU. La fédération distribué la charge mais introduit la fragmentation des requêtes et des lacunes de données.
Exécuter deux serveurs Prometheus identiques gaspille des ressources et nécessite quand même une déduplication externe. Le clustering Alertmanager ajoute une couche supplémentaire d'infrastructure à gérer.
Prometheus nécessite des mises à jour régulières, la gestion du stockage, des procédures de sauvegarde et la planification de capacité. De nombreuses équipes consacrent 20 à 40 heures par mois aux opérations Prometheus seules.
Pourquoi Bleemeo
Un Prometheus cloud géré avec les chiffres qui comptent — vos requêtes PromQL, tableaux de bord et règles d'alerte existants fonctionnent sans modification.
Pointez Glouton vers vos endpoints /metrics, ou poussez via OTLP — c'est fait. Aucun serveur Prometheus à provisionner, aucun cluster Thanos à déployer, aucun Alertmanager à configurer. La découverte automatique reconnaît plus de 100 services dès le départ.
Métriques en pleine résolution conservées pendant 13 mois — sans downsampling, sans trous de données, sans Thanos ni Cortex à opérer. Capacity planning, post-mortems, comparaisons d'une année sur l'autre, tout reste accessible sans tier de stockage long terme séparé.
Redondance multi-zones avec basculement automatique et SLA d'uptime de 99,99 %. Quand votre cluster se dégrade ou que votre application crashe, la plateforme continue d'ingérer et d'alerter en dehors de votre infrastructure — pour que le signal critique dont vous avez besoin vous parvienne réellement.
Un Prometheus auto-hébergé consomme 20 à 40 heures-ingénieur par mois : croissance du stockage, upgrades de version, scrape configs qui dérivent, ajustement des règles d'alerte, clustering Alertmanager. Bleemeo rend ce temps à votre travail plateforme et produit.
Ce qui est inclus
Voici ce qui est livré avec le service Prometheus géré de Bleemeo — sans sharding, sans fédération, sans gestion du stockage. Que vous exécutiez une poignée de microservices ou des milliers de conteneurs sur plusieurs clusters, la plateforme scale avec vous.
Dirigez votre agent Glouton vers les endpoints Prometheus ou envoyez les métriques via OTLP (OpenTelemetry Protocol). Pas besoin de provisionner du stockage, de configurer des politiques de rétention ou de mettre en place la réplication. Les métriques arrivent dans le cloud en quelques secondes après la configuration.
Gérez des millions de séries temporelles sans sharding ou fédération manuels. Notre architecture multi-tenant distribué la charge automatiquement et scale horizontalement à mesure que votre volume de métriques augmente.
Redondance multi-zones avec basculement automatique garantissant un SLA de 99,99 % de disponibilité. Chaque point de données est répliqué sur plusieurs zones de disponibilité pour la durabilité et des performances de requête rapides. Pas besoin d'exécuter des instances Prometheus en double ou de gérer des configurations de réplication complexes.
13 mois de données métriques en pleine résolution par défaut. Pas de sous-échantillonnage, pas de lacunes de données, pas besoin de solutions de stockage externes comme Thanos ou Cortex.
Définissez des alertes avec des expressions PromQL familières. Les canaux de notification intégrés (email, SMS, Slack, PagerDuty, webhooks) remplacent le besoin d'une infrastructure Alertmanager séparée.
Des tableaux de bord pré-configurés se remplissent automatiquement lorsque des services sont détectés. Créez des tableaux de bord personnalisés avec des requêtes PromQL ou connectez votre installation Grafana existante via notre endpoint API compatible Prometheus.
Visibilité
Chaque alerte déclenchée et chaque changement d'état sont conservés pendant toute la fenêtre de rétention de 13 mois. Repérez les incidents récurrents sur la heatmap et descendez jusqu'à l'événement exact.
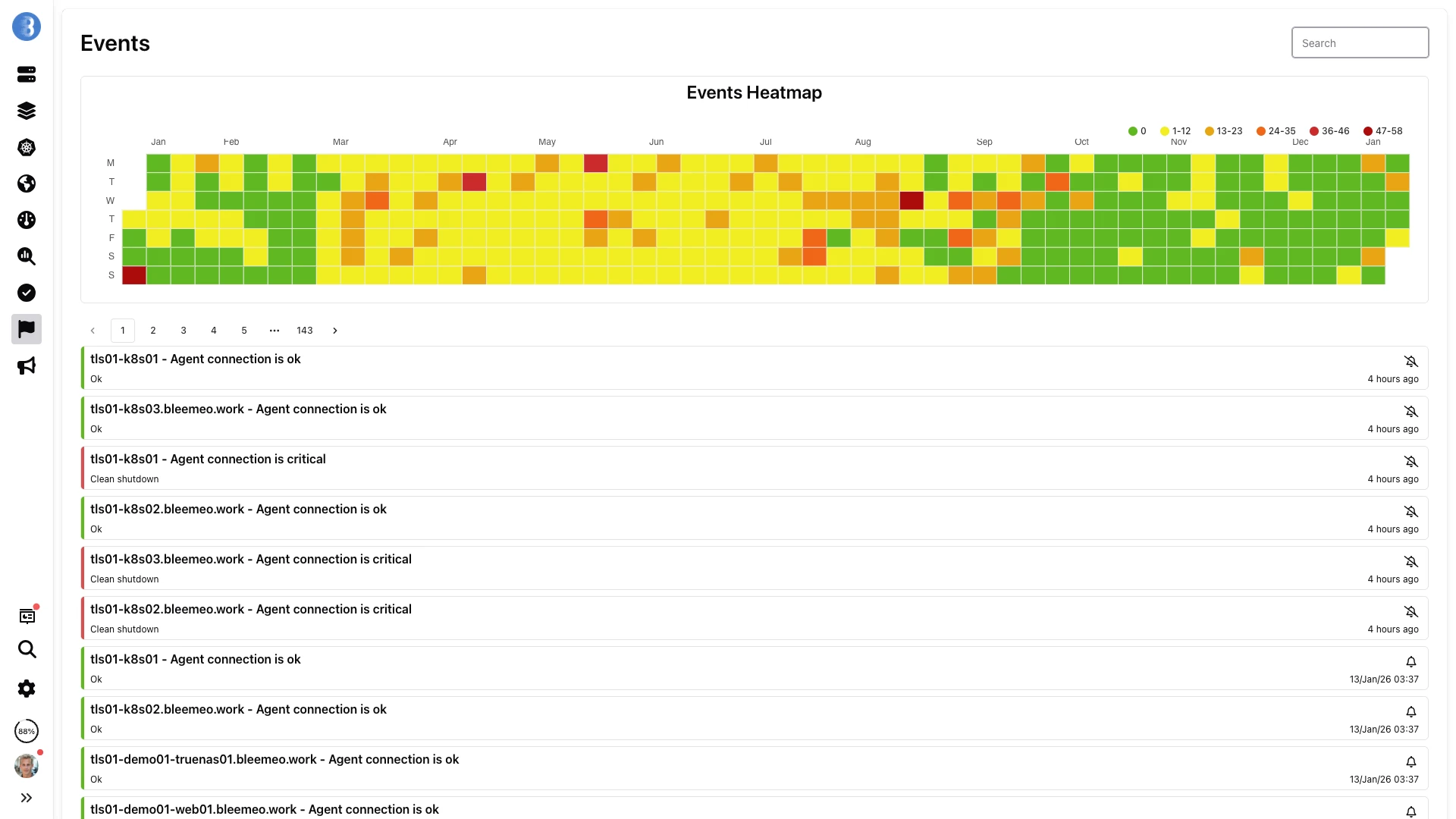
Alertes
Définissez une recording rule avec une requête PromQL brute, attachez des seuils Low/High Warning et Critical, et Bleemeo la transforme en alerte vivante — sans cluster Alertmanager, sans dérive de YAML.

Comparaison
| Fonctionnalité | Auto-Hébergé | Bleemeo Prometheus |
|---|---|---|
| Temps de Configuration | Jours à semaines | Minutes |
| Scaling | Configuration manuelle | Automatique |
| Haute Disponibilité | Configuration complexe requise | Intégrée |
| Stockage Long Terme | Solution externe nécessaire | Inclus |
| Maintenance | 20-40 heures/mois | Zéro |
| Coût Mensuel Total | 5 000-10 000 $ | 500-3 000 $ |
| Rétention des Données | 15 jours (par défaut) | 13 mois |
On-premise ou cloud, Bleemeo supervise les clusters Kubernetes de mes clients sans complexité. Un outil que je recommande pour sa simplicité et la clarté qu'il apporte.

En action
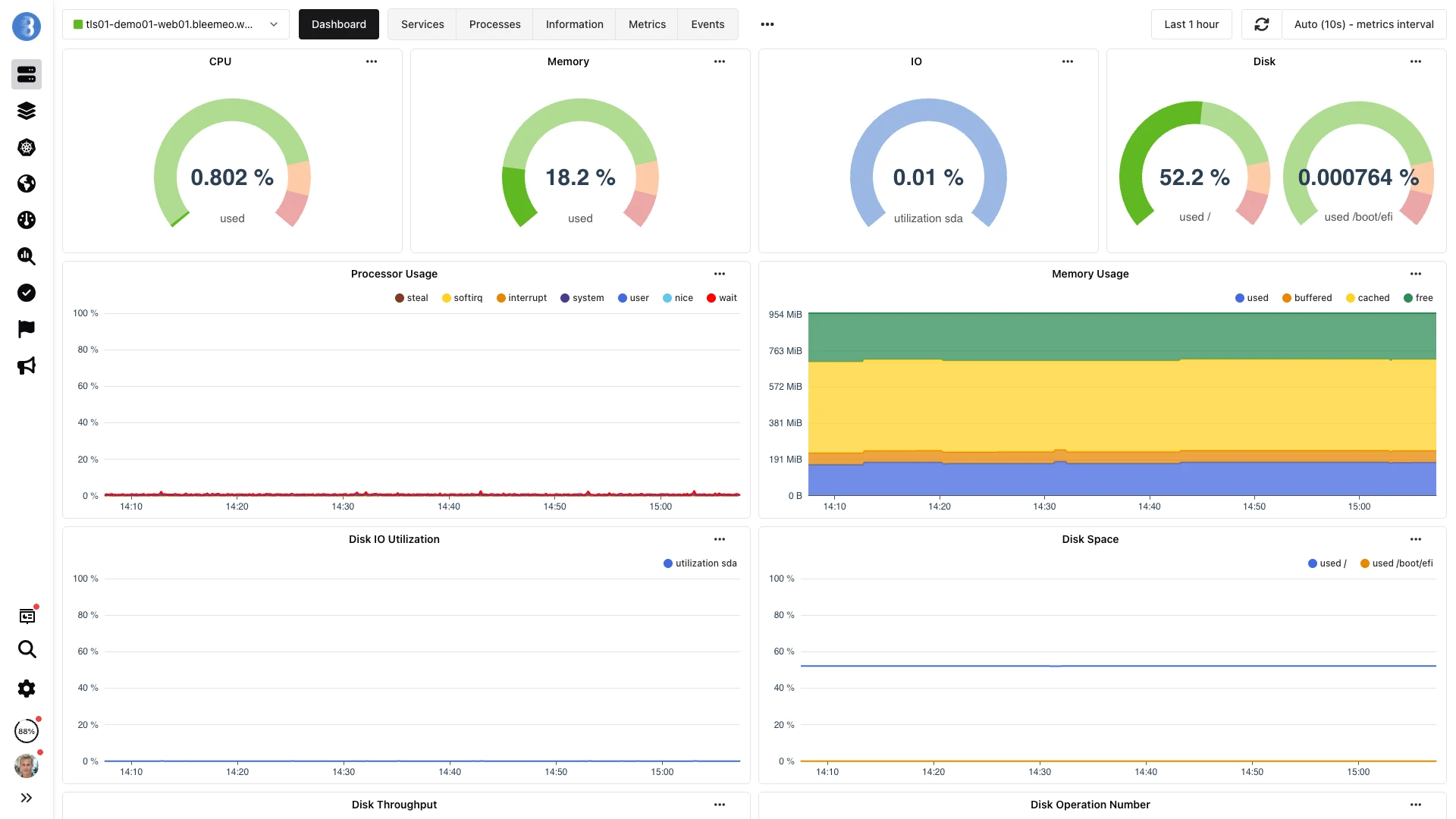
/metrics au dashboardGlouton collecte vos endpoints Prometheus et les tableaux de bord PromQL de Bleemeo se remplissent — capturé ci-dessous.

De la collecte au tableau de bord — en moins d'une minute, sans configuration.
Architecture
Faites passer vos propres métriques par ce flux — mêmes 30 secondes, même Prometheus cloud géré.
Prise en main
Ajoutez les cibles de métriques à votre configuration Glouton. Glouton collecte vos endpoints Prometheus et transmet les métriques à Bleemeo. Vous pouvez aussi envoyer des métriques via OTLP (OpenTelemetry Protocol) pour les équipes utilisant déjà l'instrumentation OpenTelemetry.
metric:
prometheus:
targets:
- url: http://localhost:9090/metricsVos métriques sont automatiquement envoyées à Bleemeo. Notre plateforme effectue la découverte automatique des services et remplit des tableaux de bord pré-configurés pour les services détectés comme PostgreSQL, Redis, NGINX et bien d'autres. Accédez à vos données via le tableau de bord Bleemeo ou connectez votre installation Grafana existante en utilisant notre endpoint API compatible Prometheus comme source de données.
Configurez les alertes via notre interface intuitive ou importez vos règles d'alertes Prometheus existantes. Définissez des règles d'alerte basées sur PromQL pour des conditions précises, créez des règles d'enregistrement pour les métriques dérivées et les agrégations fréquemment utilisées, et choisissez parmi plus de 15 intégrations de canaux de notification incluant email, SMS, Slack, PagerDuty, Microsoft Teams et webhooks.
Migration
Pas de bascule big-bang. Trois étapes incrémentales en parallèle de votre stack existante.
Déployez l'agent Glouton pour collecter les mêmes endpoints Prometheus que votre serveur actuel surveille, tout en gardant votre stockage local actif. Validez que chaque métrique apparaît correctement dans Bleemeo avant de décommissionner quoi que ce soit.
Bleemeo expose une API compatible Prometheus qui fonctionne comme source de données Grafana standard. Ajoutez Bleemeo comme seconde source, comparez les tableaux de bord côte à côte, puis basculez le défaut — dispositions de panneaux et modèles de variables restent identiques.
L'alerting intégré de Bleemeo remplace Alertmanager entièrement. Vos expressions d'alerte PromQL fonctionnent sans modification ; configurez les canaux email, SMS, Slack, PagerDuty ou webhook depuis la plateforme et retirez le cluster Alertmanager.
Cas d'usage
Surveillez les clusters Kubernetes, microservices et conteneurs avec la découverte automatique des services. Glouton se déploie comme DaemonSet et détecte automatiquement tous les services en cours d'exécution sur chaque nœud.
Commencez avec 5 serveurs et passez à 5 000 sans ré-architecturer. Pas de planification de capacité, pas de gestion du stockage, pas de complexité de fédération. Payez uniquement ce que vous utilisez.
Respectez les exigences SOC 2 avec des données chiffrées dans des centres de données européens. La rétention de 13 mois satisfait la plupart des cadres de conformité sans infrastructure de stockage supplémentaire. Le contrôle d'accès basé sur les rôles et l'intégration SSO garantissent que seuls les membres autorisés de l'équipe accèdent à vos métriques.
Éliminez 20 à 40 heures par mois d'opérations Prometheus. Concentrez le temps d'ingénierie sur le développement de fonctionnalités plutôt que sur la gestion de l'infrastructure de monitoring. Plus besoin de mettre à jour les versions de Prometheus, redimensionner les volumes de stockage ou déboguer les timeouts de requêtes — laissez Bleemeo s'occuper de tout.
Ressources
Primer sur les métriques Prometheus, PromQL, conventions de nommage et cardinalité — un contexte utile pendant que vous évaluez le Prometheus hébergé de Bleemeo.
Prometheus identifie chaque métrique par un nom et un ensemble de labels clé-valeur. Le modèle facilite le découpage, le filtrage et l'agrégation selon n'importe quelle dimension. Par exemple, http_requests_total{method="GET", endpoint="/api/users", status="200"} capture les requêtes GET vers /api/users retournant un 200 — et la même métrique supporte les requêtes par méthode, endpoint, code de statut ou toute combinaison, sans dupliquer la définition.
Prometheus définit quatre types fondamentaux. Un Counter est une valeur monotone croissante — nombre de requêtes, octets transférés. Un Gauge monte ou descend — utilisation CPU, connexions actives. Un Histogram répartit les observations en intervalles pour les distributions de latence ou de taille. Un Summary calcule des quantiles en streaming (p95, p99) pour le suivi SLA temps réel. Choisir le bon type par mesure est ce qui garde les tableaux de bord et les alertes précis.
Les noms de métriques doivent être en minuscules avec underscores et terminer par un suffixe d'unité comme _seconds, _bytes ou _total (pour les counters). Par exemple, http_request_duration_seconds indique instantanément ce qui est mesuré. Bleemeo préserve ces conventions et accepte les noms de métriques Prometheus standard tels quels — la migration des métriques existantes ne nécessite aucun renommage.
PromQL (Prometheus Query Language) découpe et agrège les séries temporelles en temps réel — taux, moyennes, percentiles, agrégations complexes sur des milliers de séries en une seule expression. Bleemeo supporte entièrement PromQL pour les tableaux de bord, règles d'alerte, recording rules et requêtes ad-hoc, de sorte que vos définitions existantes migrent sans modification.
La cardinalité est le nombre de combinaisons uniques de valeurs de labels par métrique. Une cardinalité élevée — IDs utilisateur, jetons de session, IDs de requête uniques dans les labels — fait consommer une mémoire excessive à Prometheus et dégrade les performances des requêtes. En bonne pratique, gardez la cardinalité à quelques centaines ou au maximum quelques milliers de valeurs par métrique. L'architecture gérée de Bleemeo gère une cardinalité plus élevée plus gracieusement qu'un Prometheus auto-hébergé, mais suivre ces bonnes pratiques garde les requêtes rapides et les coûts prévisibles.
Vous voulez aller plus loin ? Apprenez à configurer la collecte Prometheus, écrire des requêtes PromQL et connecter Grafana à vos métriques Bleemeo.
Lire la DocumentationTout ce que vous devez savoir sur le service Prometheus géré de Bleemeo
Vous pouvez envoyer des métriques à Bleemeo de deux manières : l'agent Glouton peut collecter les endpoints Prometheus localement et transmettre les métriques au cloud, ou vous pouvez envoyer des métriques via OTLP (OpenTelemetry Protocol). Glouton est l'approche recommandée car il ajoute le contexte d'infrastructure et nécessite une configuration minimale.
Oui, Bleemeo supporte entièrement PromQL (Prometheus Query Language). Vous pouvez utiliser PromQL pour les widgets de tableaux de bord personnalisés, les conditions d'alerte et les requêtes ad-hoc. Cela signifie que vous pouvez migrer les tableaux de bord et règles d'alerte Prometheus existants avec des modifications minimales. Notre documentation fournit des exemples et bonnes pratiques pour l'utilisation de PromQL dans Bleemeo.
Oui, Bleemeo fournit un endpoint API compatible Prometheus qui fonctionne comme source de données Grafana. Vous pouvez connecter votre installation Grafana existante à Bleemeo et utiliser vos tableaux de bord existants. Cela permet aux équipes de continuer à utiliser des outils familiers tout en bénéficiant du stockage géré et de la scalabilité de Bleemeo.
Bleemeo conserve les métriques pendant 13 mois par défaut, contre une rétention locale typique de 15 jours pour Prometheus. Ce stockage long terme permet les comparaisons d'une année sur l'autre, la planification de capacité et les exigences de conformité. Toute la rétention est automatique — pas besoin de configurer des solutions de stockage externes comme Thanos ou Cortex.
Un Prometheus auto-hébergé à grande échelle coûte typiquement $5 000-10 000/mois incluant l'infrastructure, les solutions de stockage et 20-40 heures de temps d'ingénierie. Le service géré de Bleemeo coûte $500-3 000/mois avec zéro charge opérationnelle. Utilisez notre calculateur pour comparer les coûts pour votre cas d'usage spécifique. Les économies augmentent avec l'échelle grâce à notre architecture multi-tenant efficace.
Non. Bleemeo est le Prometheus cloud géré qui remplace Thanos, Cortex et Mimir entièrement. Le stockage long terme, le scaling horizontal, la déduplication et les requêtes inter-clusters sont tous intégrés à la plateforme. Vous pointez Glouton (ou OTLP) vers vos endpoints /metrics et arrêtez d'opérer des storage backends, queriers, compactors ou store gateways. Rétention de 13 mois dès le départ avec un SLA de 99,99 %.
Bleemeo offre une haute disponibilité intégrée avec redondance multi-zones et basculement automatique. Nous garantissons un SLA de 99,99 % de disponibilité. Ceci est inclus dans le service standard — pas besoin de configurer plusieurs instances Prometheus, de mettre en place la réplication ou de gérer le basculement manuellement. Vos métriques sont toujours disponibles quand vous en avez besoin.
Oui, la migration est simple. Vous pouvez faire fonctionner Bleemeo en parallèle avec votre Prometheus existant pendant la transition. Déployez l'agent Glouton pour collecter les mêmes endpoints Prometheus, validez les données dans Bleemeo, puis décommissionnez votre installation auto-hébergée. Les règles d'alerte peuvent être migrées grâce à la compatibilité PromQL. Nous fournissons des guides de migration et du support pour les clients entreprise.
L'architecture de Bleemeo gère des millions de séries temporelles sans intervention manuelle. À mesure que votre volume de métriques augmente, notre infrastructure scale automatiquement. Vous n'avez pas besoin de redimensionner les instances, de configurer le sharding ou de mettre en place la fédération. Cela se fait de manière transparente — vous envoyez simplement les métriques et nous nous assurons qu'elles sont stockées et interrogeables quel que soit le volume.
Bleemeo inclut un système d'alerting complet compatible avec les règles d'alerte Prometheus. Vous pouvez définir des alertes avec des conditions PromQL, configurer plusieurs canaux de notification (email, SMS, Slack, PagerDuty, webhooks), mettre en place des politiques d'escalade et utiliser des fonctionnalités comme le regroupement et les fenêtrès de maintenance. Cela remplace le besoin d'une infrastructure Alertmanager séparée.
Oui, la sécurité est une priorité. Toutes les données sont chiffrées en transit (TLS) et au repos. Bleemeo est hébergé dans des centres de données européens avec conformité SOC 2. Les données de chaque client sont isolées. Nous supportons l'intégration SSO et le contrôle d'accès basé sur les rôles. Consultez notre page sécurité pour des informations détaillées sur nos pratiques de sécurité et certifications.
Environ 30 secondes de configuration réelle. Pointez l'agent Glouton vers vos endpoints /metrics existants (ou poussez via OTLP), fournissez vos identifiants de compte, et les métriques commencent à arriver dans Bleemeo en quelques secondes. La découverte automatique reconnaît plus de 100 services sans configuration manuelle ; tableaux de bord et alerting PromQL fonctionnent dès le départ. Aucun serveur Prometheus à provisionner, aucun stockage à dimensionner, aucun Alertmanager à clusteriser.