

Costruito su Prometheus e OpenTelemetry
Nessun vendor lock-in
Invia metriche in 30 secondi, interroga con tutto PromQL
Bleemeo è un software di monitoraggio Prometheus hosted — un Prometheus cloud gestito con compatibilità PromQL completa, 13 mesi di retention e uno SLA del 99,99%. Nessun Thanos da gestire, nessun Cortex da mantenere, nessun Mimir da scalare. Usa lo strumento Prometheus che già conosci, senza gestire personalmente lo storage, lo scaling o l'infrastruttura di alerting.
Prova gratuita 15 giorniSenza carta di creditoSenza impegno a lungo termine
Nessun vendor lock-in
Dati conservati nell'UE · Conforme al GDPR
In tutta Europa e oltre
Oltre 500 aziende si affidano a Bleemeo per monitorare la propria infrastruttura
La sfida
Il disco locale si riempie velocemente con metriche ad alta cardinalità. Soluzioni esterne come Thanos, Cortex o Mimir aggiungono una significativa complessità operativa e richiedono tempo ingegneristico dedicato.
Man mano che la vostra infrastruttura cresce, le singole istanze Prometheus raggiungono i limiti di memoria e CPU. La federation distribuisce il carico ma introduce frammentazione delle query e lacune nei dati.
Eseguire due server Prometheus identici spreca risorse e richiede comunque una deduplicazione esterna. Il clustering di Alertmanager aggiunge un ulteriore livello di infrastruttura da gestire.
Prometheus richiede aggiornamenti regolari, gestione dello storage, procedure di backup e pianificazione della capacità. Molti team dedicano 20-40 ore al mese alle sole operazioni Prometheus.
Perché Bleemeo
Un Prometheus cloud gestito con i numeri che contano — le tue query PromQL, dashboard e regole di alert esistenti funzionano senza modifiche.
Punta Glouton ai tuoi endpoint /metrics, o invia via OTLP — fatto. Nessun server Prometheus da provisionare, nessun cluster Thanos da distribuire, nessun Alertmanager da configurare. La scoperta automatica riconosce più di 100 servizi out of the box.
Metriche in piena risoluzione conservate per 13 mesi — senza downsampling, senza buchi di dati, senza Thanos o Cortex da gestire. Capacity planning, post-mortem, confronti year-over-year — tutto resta accessibile senza un layer separato di storage a lungo termine.
Ridondanza multi-zona con failover automatico e SLA di uptime del 99,99%. Quando il tuo cluster si degrada o la tua applicazione crasha, la piattaforma continua a ingerire e ad allertare al di fuori della tua infrastruttura — così il segnale critico di cui hai bisogno ti raggiunge davvero.
Un Prometheus self-hosted consuma 20-40 ore-ingegnere al mese: crescita dello storage, upgrade di versione, scrape config che derivano, tuning delle regole di alert, clustering di Alertmanager. Bleemeo restituisce quel tempo al tuo lavoro su piattaforma e prodotto.
Cosa è incluso
Ecco cosa viene fornito con il servizio Prometheus gestito di Bleemeo — niente sharding, niente federazione, niente gestione dello storage. Che tu esegua una manciata di microservizi o migliaia di container su più cluster, la piattaforma scala con te.
Puntate il vostro agente Glouton sugli endpoint Prometheus o inviate le metriche tramite OTLP (OpenTelemetry Protocol). Non serve provisionare storage, configurare policy di retention o impostare la replica. Le metriche fluiscono nel cloud in pochi secondi dalla configurazione.
Gestite milioni di serie temporali senza sharding o federation manuali. La nostra architettura multi-tenant distribuisce il carico automaticamente e scala orizzontalmente man mano che il vostro volume di metriche cresce.
Ridondanza multi-zona con failover automatico che garantisce un SLA del 99,99% di uptime. Ogni punto dati viene replicato su più zone di disponibilità per durabilità e prestazioni di query veloci. Non serve eseguire istanze Prometheus duplicate o gestire configurazioni di replica complesse.
13 mesi di dati metrici a piena risoluzione di default. Nessun downsampling, nessuna lacuna nei dati, nessuna necessità di soluzioni di storage esterne come Thanos o Cortex.
Definite alert usando espressioni PromQL familiari. I canali di notifica integrati (email, SMS, Slack, PagerDuty, webhooks) sostituiscono la necessità di un'infrastruttura Alertmanager separata.
Dashboard preconfigurate si popolano automaticamente quando i servizi vengono rilevati. Create dashboard personalizzate con query PromQL o collegate la vostra installazione Grafana esistente tramite il nostro endpoint API compatibile Prometheus.
Visibilità
Ogni alert attivato e ogni cambio di stato vengono conservati per tutta la finestra di retention di 13 mesi. Individua gli incidenti ricorrenti sulla heatmap e scendi fino all'evento esatto.
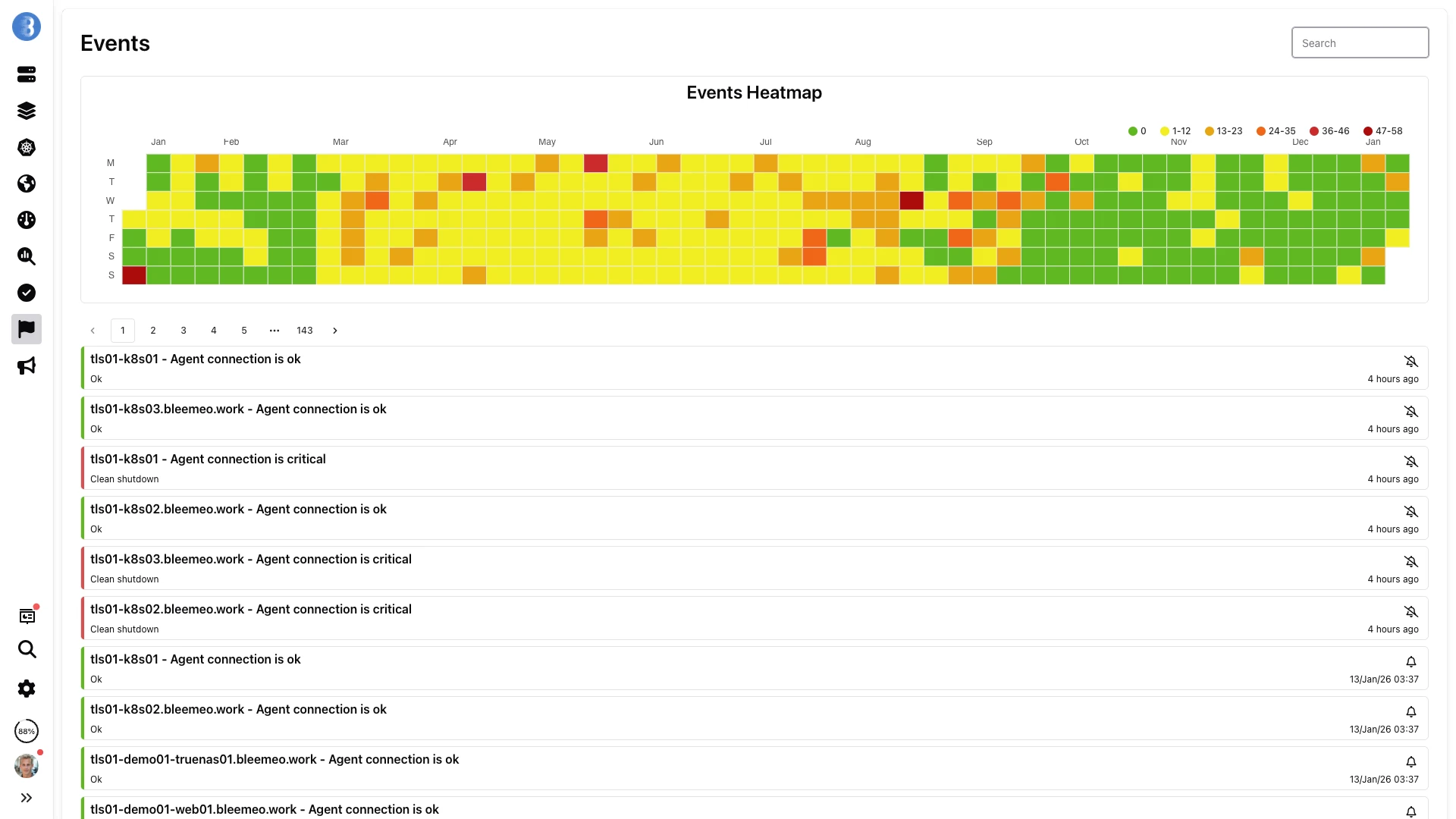
Avvisi
Definisci una recording rule con una query PromQL grezza, allega soglie Low/High Warning e Critical, e Bleemeo la trasforma in un alert vivo — senza cluster Alertmanager, senza deriva di YAML.

Confronto
| Funzionalità | Self-Hosted | Bleemeo Prometheus |
|---|---|---|
| Tempo di Setup | Giorni o settimane | Minuti |
| Scaling | Configurazione manuale | Automatico |
| Alta Disponibilità | Setup complesso richiesto | Integrata |
| Storage a Lungo Termine | Richiede soluzione esterna | Incluso |
| Manutenzione | 20-40 ore/mese | Zero |
| Costo Mensile Totale | $5.000-10.000 | $500-3.000 |
| Retention dei Dati | 15 giorni (default) | 13 mesi |
On-premise o nel cloud, Bleemeo monitora i cluster Kubernetes dei miei clienti senza complessità. Uno strumento che consiglio per la sua semplicità e la chiarezza che offre.

In azione
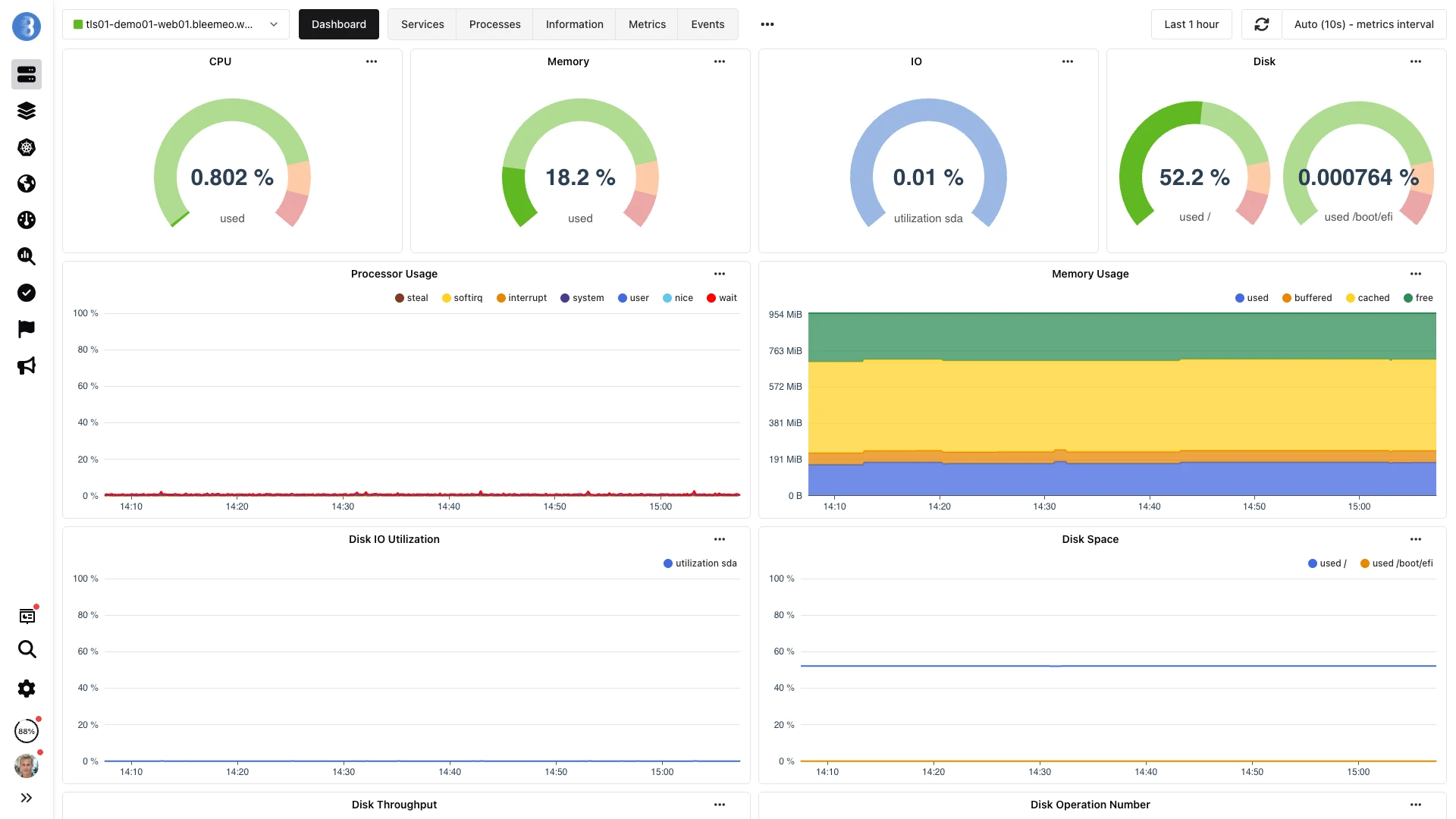
/metrics alla dashboardGlouton raccoglie i tuoi endpoint Prometheus e le dashboard PromQL di Bleemeo si riempiono — catturato qui sotto.

Dallo scrape alla dashboard — in meno di un minuto, senza configurazione.
Architettura
Fai passare le tue metriche attraverso questo flusso — stessi 30 secondi, stesso Prometheus cloud gestito.
Per iniziare
Aggiungete i target delle metriche alla vostra configurazione Glouton. Glouton raccoglie i vostri endpoint Prometheus e inoltra le metriche a Bleemeo. Potete anche inviare metriche tramite OTLP (OpenTelemetry Protocol) per i team che già usano l'instrumentazione OpenTelemetry.
metric:
prometheus:
targets:
- url: http://localhost:9090/metricsLe vostre metriche fluiscono automaticamente verso Bleemeo. La nostra piattaforma esegue il rilevamento automatico dei servizi e popola dashboard preconfigurate per i servizi rilevati come PostgreSQL, Redis, NGINX e molti altri. Accedete ai vostri dati tramite la dashboard Bleemeo o collegate la vostra installazione Grafana esistente usando il nostro endpoint API compatibile Prometheus come data source.
Configurate gli alert tramite la nostra interfaccia intuitiva o importate le vostre regole di alert Prometheus esistenti. Definite regole di alert basate su PromQL per condizioni precise, create recording rule per metriche derivate e aggregazioni frequentemente usate, e scegliete tra oltre 15 integrazioni di canali di notifica inclusi email, SMS, Slack, PagerDuty, Microsoft Teams e webhooks.
Migrazione
Nessun cambio big-bang. Tre passi incrementali in parallelo con il tuo stack esistente.
Distribuisci l'agente Glouton per raccogliere gli stessi endpoint Prometheus che il tuo server attuale monitora, mantenendo il tuo storage locale attivo. Verifica che ogni metrica appaia correttamente in Bleemeo prima di dismettere nulla.
Bleemeo espone un'API compatibile Prometheus che funziona come data source Grafana standard. Aggiungi Bleemeo come seconda data source, confronta dashboard affiancate, poi cambia il default — layout dei pannelli e template delle variabili restano invariati.
L'alerting integrato di Bleemeo sostituisce Alertmanager interamente. Le tue espressioni di alert PromQL funzionano senza modifiche; configura i canali email, SMS, Slack, PagerDuty o webhook dalla piattaforma e ritira il cluster Alertmanager.
Casi d'uso
Monitorate cluster Kubernetes, microservizi e container con il rilevamento automatico dei servizi. Glouton si distribuisce come DaemonSet e rileva automaticamente tutti i servizi in esecuzione su ogni nodo.
Iniziate con 5 server e scalate a 5.000 senza ri-architettare. Nessuna pianificazione della capacità, nessuna gestione dello storage, nessuna complessità di federation. Pagate solo per quello che usate.
Soddisfate i requisiti SOC 2 con dati crittografati in data center europei. La retention di 13 mesi soddisfa la maggior parte dei framework di compliance senza infrastruttura di storage aggiuntiva. Il controllo degli accessi basato sui ruoli e l'integrazione SSO garantiscono che solo i membri autorizzati del team accedano alle vostre metriche.
Eliminate 20-40 ore/mese di operazioni Prometheus. Concentrate il tempo ingegneristico sullo sviluppo di funzionalità anziché sulla gestione dell'infrastruttura di monitoraggio. Niente più aggiornamenti delle versioni di Prometheus, ridimensionamento dei volumi di storage o debug dei timeout delle query — lasciate che Bleemeo gestisca tutto.
Risorse
Un primer su metriche Prometheus, PromQL, convenzioni di nomenclatura e cardinalità — un contesto utile mentre valuti il Prometheus hosted di Bleemeo.
Prometheus identifica ogni metrica con un nome e un insieme di label chiave-valore. Il modello facilita il taglio, il filtraggio e l'aggregazione su qualsiasi dimensione. Ad esempio, http_requests_total{method="GET", endpoint="/api/users", status="200"} cattura le richieste GET a /api/users che hanno restituito 200 — e la stessa metrica supporta query per metodo, endpoint, codice di stato o qualsiasi combinazione, senza duplicare la definizione.
Prometheus definisce quattro tipi fondamentali. Un Counter è un valore monotonicamente crescente — conteggi di richieste, byte trasferiti. Un Gauge sale o scende — utilizzo CPU, connessioni attive. Un Histogram raggruppa osservazioni in bucket per distribuzioni di latenza o dimensioni. Un Summary calcola quantili in streaming (p95, p99) per il tracking SLA in tempo reale. Scegliere il tipo giusto per ogni misurazione è ciò che mantiene dashboard e alert accurati.
I nomi delle metriche dovrebbero essere in minuscolo con underscore e terminare con un suffisso di unità come _seconds, _bytes o _total (per i counter). Ad esempio, http_request_duration_seconds indica subito cosa viene misurato. Bleemeo preserva queste convenzioni e accetta i nomi delle metriche Prometheus standard così come sono — migrare le metriche esistenti non richiede nessuna rinomina.
PromQL (Prometheus Query Language) taglia e aggrega serie temporali in tempo reale — tassi, medie, percentili, aggregazioni complesse su migliaia di serie in una singola espressione. Bleemeo supporta completamente PromQL per dashboard, regole di alert, recording rule e query ad-hoc, quindi le tue definizioni esistenti migrano senza modifiche.
La cardinalità è il numero di combinazioni uniche di valori di label per metrica. Un'alta cardinalità — ID utente, token di sessione, ID di richiesta unici nelle label — fa consumare memoria eccessiva a Prometheus e degrada le prestazioni delle query. Come best practice, mantieni la cardinalità a centinaia o al massimo poche migliaia di valori per metrica. L'architettura gestita di Bleemeo gestisce una cardinalità più alta in modo più elegante rispetto a Prometheus self-hosted, ma seguire queste best practice mantiene le query veloci e i costi prevedibili.
Volete approfondire? Imparate come configurare la raccolta Prometheus, scrivere query PromQL e collegare Grafana alle vostre metriche Bleemeo.
Leggi la DocumentazioneTutto quello che dovete sapere sul servizio Prometheus gestito di Bleemeo
Potete inviare metriche a Bleemeo in due modi: l'agente Glouton può raccogliere gli endpoint Prometheus localmente e inoltrare le metriche al cloud, oppure potete inviare metriche tramite OTLP (OpenTelemetry Protocol). Glouton è l'approccio consigliato perché aggiunge contesto infrastrutturale e richiede una configurazione minima.
Sì, Bleemeo supporta completamente PromQL (Prometheus Query Language). Potete usare PromQL per widget di dashboard personalizzati, condizioni di alerting e query ad-hoc. Questo significa che potete migrare dashboard e regole di alert Prometheus esistenti con modifiche minime. La nostra documentazione fornisce esempi e best practice per l'uso di PromQL in Bleemeo.
Sì, Bleemeo fornisce un endpoint API compatibile Prometheus che funziona come data source Grafana. Potete collegare la vostra installazione Grafana esistente a Bleemeo e usare le vostre dashboard esistenti. Questo permette ai team di continuare a usare strumenti familiari beneficiando dello storage gestito e della scalabilità di Bleemeo.
Bleemeo conserva le metriche per 13 mesi di default, rispetto alla tipica retention locale di 15 giorni di Prometheus. Questo storage a lungo termine consente confronti anno su anno, pianificazione della capacità e requisiti di conformità. Tutta la retention è automatica — non serve configurare soluzioni di storage esterne come Thanos o Cortex.
Prometheus self-hosted su larga scala costa tipicamente $5.000-10.000/mese inclusi infrastruttura, soluzioni di storage e 20-40 ore di tempo ingegneristico. Il servizio gestito di Bleemeo costa $500-3.000/mese con zero overhead operativo. Usate il nostro calcolatore per confrontare i costi per il vostro caso d'uso specifico. I risparmi aumentano con la scala grazie alla nostra efficiente architettura multi-tenant.
No. Bleemeo è il Prometheus cloud gestito che sostituisce Thanos, Cortex e Mimir interamente. Storage a lungo termine, scaling orizzontale, deduplicazione e query inter-cluster sono tutti integrati nella piattaforma. Punti Glouton (o OTLP) ai tuoi endpoint /metrics e smetti di gestire storage backend, querier, compactor o store gateway. Retention di 13 mesi out of the box con SLA del 99,99%.
Bleemeo offre alta disponibilità integrata con ridondanza multi-zona e failover automatico. Garantiamo un SLA del 99,99% di uptime. Questo è incluso nel servizio standard — non serve configurare più istanze Prometheus, impostare la replica o gestire il failover manualmente. Le vostre metriche sono sempre disponibili quando ne avete bisogno.
Sì, la migrazione è semplice. Potete eseguire Bleemeo in parallelo con il vostro Prometheus esistente durante la transizione. Distribuite l'agente Glouton per raccogliere gli stessi endpoint Prometheus, validate i dati in Bleemeo, poi dismettete la vostra installazione self-hosted. Le regole di alert possono essere migrate grazie alla compatibilità PromQL. Forniamo guide alla migrazione e supporto per i clienti enterprise.
L'architettura di Bleemeo gestisce milioni di serie temporali senza intervento manuale. Man mano che il vostro volume di metriche cresce, la nostra infrastruttura scala automaticamente. Non dovete ridimensionare le istanze, configurare lo sharding o impostare la federation. Questo avviene in modo trasparente — inviate semplicemente le metriche e noi ci assicuriamo che siano archiviate e interrogabili indipendentemente dal volume.
Bleemeo include un sistema di alerting completo compatibile con le regole di alert Prometheus. Potete definire alert con condizioni PromQL, configurare più canali di notifica (email, SMS, Slack, PagerDuty, webhooks), impostare politiche di escalation e usare funzionalità come raggruppamento e finestre di manutenzione. Questo sostituisce la necessità di un'infrastruttura Alertmanager separata.
Sì, la sicurezza è una priorità. Tutti i dati sono crittografati in transito (TLS) e a riposo. Bleemeo è ospitato in data center europei con conformità SOC 2. I dati di ogni cliente sono isolati. Supportiamo l'integrazione SSO e il controllo degli accessi basato sui ruoli. Visitate la nostra pagina sicurezza per informazioni dettagliate sulle nostre pratiche di sicurezza e certificazioni.
Circa 30 secondi di configurazione effettiva. Punta l'agente Glouton ai tuoi endpoint /metrics esistenti (o invia via OTLP), fornisci le credenziali del tuo account, e le metriche iniziano ad arrivare in Bleemeo in pochi secondi. La scoperta automatica riconosce più di 100 servizi senza configurazione manuale; dashboard e alert PromQL funzionano out of the box. Nessun server Prometheus da provisionare, nessuno storage da dimensionare, nessun Alertmanager da clusterizzare.