

Costruito su Prometheus e OpenTelemetry
Nessun vendor lock-in
Nagios ha pionerato il monitoraggio negli anni 2000, ma la sua architettura basata su plugin e i file di configurazione manuali non hanno tenuto il passo con le infrastrutture moderne. Bleemeo ti offre discovery automatico, dashboard integrate e alerting basato su ML — nessun plugin, nessun NRPE, nessun objects.cfg.
Prova gratuita 15 giorniSenza carta di creditoSenza impegno a lungo termine
Nessun vendor lock-in
Dati conservati nell'UE · Conforme al GDPR
In tutta Europa e oltre
Più di 500 team abbandonano i deployment Nagios storici
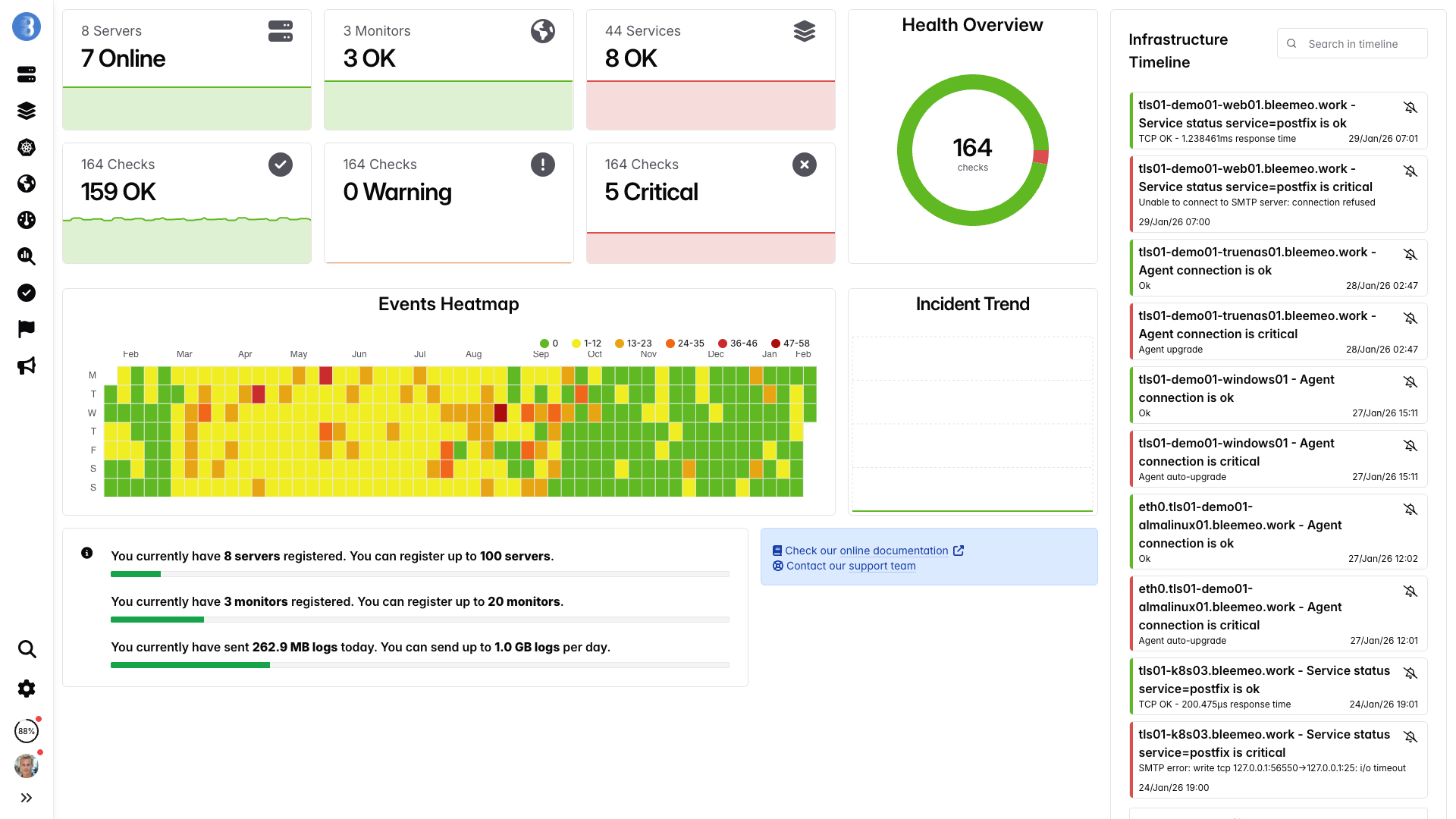
Dashboard in tempo reale, pronte in pochi minuti — nessuna configurazione necessaria
Dalla registrazione al dashboard in 30 secondi — senza file .cfg né rollout NRPE
Un comando, nessuna configurazione — metriche in flusso in meno di un minuto.
Perché cambiare
Configurare Nagios richiede la modifica di file di testo complessi come hosts.cfg, services.cfg e commands.cfg, poi il ricaricamento del daemon per ogni singola modifica. Ogni nuovo host o servizio deve essere definito manualmente con comandi di check, intervalli di check, periodi di notifica, gruppi di contatti e soglie — spesso decine di righe per oggetto. Un singolo errore di sintassi in queste definizioni può impedire al daemon Nagios di riavviarsi, lasciando il tuo monitoraggio cieco finché il problema non viene trovato e corretto. Ciò che richiede giorni o settimane con Nagios richiede pochi minuti con il discovery automatico di Bleemeo, che rileva servizi, container e componenti infrastrutturali nel momento in cui l'agente viene installato.
Eseguire Nagios significa essere responsabili del server di monitoraggio stesso: patch del sistema operativo, aggiornamenti di Apache o PHP, compatibilità dei plugin, spazio disco per la retention dei dati di performance e aggiornamenti degli agenti NRPE su ogni server della tua flotta. Ogni agente NRPE deve essere configurato individualmente con comandi di check consentiti e regole firewall, creando una superficie di manutenzione in espansione che cresce linearmente con la tua infrastruttura. La community Nagios si è frammentata in fork concorrenti come Icinga 2, Naemon e Shinken, rendendo più difficile trovare plugin aggiornati, add-on compatibili e documentazione affidabile. Bleemeo è una piattaforma SaaS completamente gestita — nessun server da patchare, nessun agente da configurare manualmente e nessun repository di plugin da verificare — così il tuo team può concentrarsi sulla risoluzione degli incidenti invece di curare lo stack di monitoraggio.
Nagios è stato progettato per data center statici on-premise dove gli host cambiano raramente e gli indirizzi IP sono fissi. Non ha supporto nativo per container, pod Kubernetes, gruppi di auto-scaling o funzioni serverless. Ogni volta che un'istanza cloud scala su o giù, la definizione host corrispondente deve essere aggiunta o rimossa manualmente — o tramite script esterni fragili — portando ad alert obsoleti, drift di configurazione e notifiche fantasma per host che non esistono più. Bleemeo è stato costruito fin dal primo giorno per ambienti cloud-native effimeri dove l'infrastruttura cambia costantemente.
L'interfaccia web predefinita di Nagios — nota come interfaccia CGI — è rimasta praticamente invariata per oltre un decennio. Offre solo tabelle di stato base per host e servizi senza dashboard in tempo reale, grafici interattivi di serie temporali o responsività mobile. La maggior parte dei team finisce per installare frontend di terze parti come Thruk, Adagios o aggiungere Grafana con PNP4Nagios solo per avere visualizzazioni utilizzabili, aggiungendo ancora più componenti da mantenere e proteggere. Bleemeo fornisce dashboard moderne e personalizzabili con streaming di metriche in tempo reale e app native iOS e Android pronte all'uso, così non hai mai bisogno di assemblare più strumenti per la visibilità di base.
On-premise o nel cloud, Bleemeo monitora i cluster Kubernetes dei miei clienti senza complessità. Uno strumento che consiglio per la sua semplicità e la chiarezza che offre.

Confronto
| Feature | Nagios | Bleemeo |
|---|---|---|
| Tempo di Setup | Giorni o settimane di definizioni manuali di host e servizi | Minuti con un singolo comando di installazione agente |
| Configurazione | Modifica manuale di objects.cfg, commands.cfg e contacts.cfg | Discovery automatico di servizi, container e infrastruttura |
| Cloud-Native | Nessun supporto container o Kubernetes; solo modello host statico | Integrazione nativa Kubernetes, Docker e provider cloud |
| App Mobile | Nessuna applicazione mobile ufficiale disponibile | App native iOS e Android con notifiche push |
| Alerting | Notifiche email e pager di base tramite script personalizzati | Routing intelligente con SMS, Slack, Teams, PagerDuty e webhook |
| Manutenzione | Server self-hosted che richiede patch OS, aggiornamenti plugin e gestione NRPE | Piattaforma SaaS completamente gestita con zero manutenzione server |
| Dashboard | UI integrata datata; richiede Thruk o Grafana per dashboard utilizzabili | Dashboard moderne e personalizzabili |
| Gestione Log | Non inclusa; richiede deploy separato di stack ELK o Graylog | Raccolta, ricerca e analisi log integrati nella stessa piattaforma |
| Rilevamento Anomalie | Solo soglie statiche; nessun machine learning o analisi dei trend | Rilevamento anomalie basato su ML con apprendimento automatico delle baseline |
| Prometheus & OpenTelemetry | Nessun supporto nativo; architettura basata su check incompatibile | Scraping nativo di exporter Prometheus e supporto collector OpenTelemetry |
| Scalabilità | Architettura a server singolo; setup distribuiti richiedono complessi add-on Mod Gearman o DNX | SaaS cloud-native che scala automaticamente da 10 a 10.000+ agenti |
| API | Interfaccia di comandi esterni limitata via command pipe; nessuna REST API in Core | REST API completa per automazione, integrazione e workflow personalizzati |
| Monitoraggio Uptime | Plugin check_http di base; nessun probing multi-location o reporting SLA | Check uptime globali da più location con dashboard SLA |
| Prezzi | Core è gratuito ma Nagios XI parte da $2.495; più infrastruttura, tempo sysadmin e strumenti di terze parti | Prezzo semplice per agente a 10.99 EUR/mese, tutte le funzionalità incluse, nessun costo nascosto |
Costi
Nagios Core può essere open source, ma il costo reale risiede nell'infrastruttura, nel tempo ingegneristico e negli strumenti di terze parti necessari per gestire uno stack di monitoraggio di livello produzione. Ecco un confronto realistico per un ambiente con 100 server su un anno.
Totale: ~$29.095/anno
Totale: ~11.869 EUR/anno
I numeri sopra assumono una stack di 100 server. Inserisci il tuo numero di host e add-on per stimare il risparmio sostituendo Nagios con Bleemeo.
Vantaggi
Installa il nostro agente leggero e scopre automaticamente servizi come MySQL, PostgreSQL, Redis, Nginx, Apache, container Docker e pod Kubernetes. Non ci sono file di configurazione da scrivere, nessun comando di check da definire e nessun ricaricamento del daemon da attivare. I nuovi servizi vengono rilevati e monitorati in pochi secondi dalla comparsa sull'host, eliminando le definizioni manuali di oggetti che consumano così tanto tempo con Nagios.
Costruita da zero per infrastrutture moderne e dinamiche. Bleemeo supporta nativamente cluster Kubernetes, runtime Docker e containerd, istanze cloud AWS, Azure e GCP. I carichi di lavoro effimeri che scalano su e giù vengono tracciati automaticamente — nessuna definizione host obsoleta, nessun alert fantasma e nessuno script di pulizia manuale necessario.
Il rilevamento anomalie basato su machine learning apprende automaticamente le baseline di comportamento normale per ogni metrica, così ricevi avvisi su problemi reali anziché su violazioni di soglie statiche. Il raggruppamento intelligente degli alert correla incidenti correlati per ridurre il rumore, e il routing flessibile delle notifiche invia gli avvisi al team giusto via Slack, Microsoft Teams, PagerDuty, SMS o webhook — prevenendo l'affaticamento da alert che affligge i deployment Nagios.
Dashboard moderne e responsive con streaming di metriche in tempo reale offrono visibilità immediata sull'intera infrastruttura. Crea viste personalizzate in minuti con widget drag-and-drop, grafici interattivi di serie temporali e mappe topologiche. A differenza di Nagios, non è necessario installare Thruk, Grafana o PNP4Nagios per avere visualizzazioni utilizzabili.
App native iOS e Android ti permettono di monitorare l'intera infrastruttura e rispondere agli incidenti da qualsiasi luogo. Ricevi notifiche push nel momento in cui viene rilevato un problema, riconosci gli alert, visualizza le dashboard e approfondisci i dettagli delle metriche — tutto dal tuo telefono o tablet, senza VPN necessaria per raggiungere un server Nagios on-premise.
Metriche, log, monitoraggio uptime e rilevamento anomalie sono unificati in un'unica piattaforma. Con Nagios, i team tipicamente assemblano strumenti separati per gestione log (ELK o Graylog), dashboard (Grafana) e check uptime (servizi esterni), creando uno stack frammentato costoso da gestire e difficile da correlare. Bleemeo riunisce tutto per permetterti di passare dall'alert alla causa radice in un'unica interfaccia.
Migrazione
Crea il tuo account Bleemeo gratuito e installa l'agente leggero su ogni server con un singolo comando. L'agente supporta Debian, Ubuntu, RHEL, CentOS, Alpine e la maggior parte delle principali distribuzioni Linux. L'installazione richiede meno di un minuto per host:
wget -qO- 'https://get.bleemeo.com?accountId=...'In pochi secondi dall'installazione, l'agente scopre automaticamente i servizi in esecuzione come MySQL, PostgreSQL, Redis, Nginx, Apache, Elasticsearch, container Docker e pod Kubernetes. Accedi alla dashboard Bleemeo per verificare che tutti i tuoi servizi critici siano rilevati e le metriche stiano fluendo. Per eventuali applicazioni personalizzate, puoi aggiungere endpoint compatibili con Prometheus o check personalizzati in pochi minuti.
Imposta i canali di notifica — Slack, Microsoft Teams, PagerDuty, SMS, email o webhook — attraverso l'interfaccia web intuitiva. Bleemeo include soglie predefinite ragionevoli per tutti i servizi scoperti, così ricevi alert significativi fin da subito. Personalizza soglie e regole di routing per adattarle alla struttura di reperibilità ed escalation del tuo team senza modificare un singolo file di configurazione.
Crea dashboard personalizzate per replicare e migliorare le viste che avevi in Nagios, Thruk o Grafana. Il builder di dashboard di Bleemeo ti permette di trascinare widget per CPU, memoria, disco, rete e metriche specifiche delle applicazioni. Condividi le dashboard con il tuo team o visualizzale su schermi a parete per la consapevolezza operativa in tempo reale.
Mantieni Nagios attivo insieme a Bleemeo per una o due settimane per validare la copertura, l'accuratezza degli alert e i workflow del team. Confronta gli alert generati da entrambi i sistemi per acquisire fiducia che Bleemeo rilevi tutto ciò che rileva Nagios — e di più, grazie al rilevamento anomalie e al raggruppamento più intelligente degli alert. Questo periodo parallelo dà anche al tuo team il tempo di familiarizzare con la nuova interfaccia e le app mobile.
Una volta che il tuo team è sicuro della copertura e degli avvisi di Bleemeo, rendilo la tua piattaforma di monitoraggio principale e dismetti Nagios. Rimuovi il server Nagios, disinstalla gli agenti NRPE dai tuoi host e ritira l'infrastruttura associata. Libererai immediatamente tempo sysadmin precedentemente speso per manutenzione plugin, gestione file di configurazione e manutenzione del server Nagios.
Ingegneri e CTO si affidano a Bleemeo per monitorare la loro infrastruttura
Abbiamo bisogno che i nostri team restino concentrati sul nostro core business — il digital signage — piuttosto che sul monitoraggio dell'infrastruttura. Bleemeo supervisiona l'intero ambiente, dal server dedicato ad Azure, e libera i nostri team dagli alert inutili garantendo al contempo la nostra qualità del servizio.

Bleemeo ci accompagna da anni: un monitoraggio semplice e affidabile, essenziale per la qualità del servizio che dobbiamo ai nostri clienti.

On-premise o nel cloud, Bleemeo monitora i cluster Kubernetes dei miei clienti senza complessità. Uno strumento che consiglio per la sua semplicità e la chiarezza che offre.
Cliente fin dal primo giorno, sono entusiasta di Bleemeo. È facile da installare, efficiente e continua a migliorare!

Durante una breve pausa pranzo abbiamo installato Bleemeo, creato una metrica personalizzata, testato gli alert ed eravamo pronti per la produzione. La velocità di deployment è notevole.

Il supporto di Bleemeo è semplicemente leggendario: rapido, competente e sempre presente quando ne abbiamo bisogno.

Il deployment di Bleemeo è stato incredibilmente veloce. In circa un'ora lo abbiamo distribuito su più di 100 server e abbiamo immediatamente ottenuto piena visibilità sulla nostra infrastruttura.

Abbiamo configurato il monitoraggio di tutti i nostri server in poche ore. La dashboard è chiara, potente e davvero piacevole da usare.

Abbiamo distribuito Bleemeo su tutta la nostra infrastruttura server in poche ore. Il monitoraggio dell'uptime ci avvisa istantaneamente ogni volta che un servizio riscontra un problema.

Guarda la demo
Guarda come i team passano dall'installazione al monitoraggio completo in meno di 5 minuti
Sì. Bleemeo monitora tutto ciò che Nagios può monitorare — server, servizi, rete — più container e Kubernetes. Grazie al discovery automatico, non è necessario scrivere plugin di check o definizioni di host.
No. L'agente di Bleemeo (Glouton) rileva e monitora automaticamente oltre 100 servizi. Nessun NRPE, nessuno script di plugin, nessun objects.cfg.
Bleemeo include soglie di alert preconfigurate per ogni servizio scoperto, più rilevamento anomalie basato su ML. Notifiche via email, Slack, PagerDuty o webhook — senza scrittura manuale di regole.
Sì. Installa l'agente Bleemeo insieme a Nagios, verifica la copertura, poi dismetti Nagios una volta che sei sicuro. La maggior parte dei team migra in meno di una settimana.
Sì. A differenza di Nagios che non ha supporto nativo per container, Bleemeo monitora Docker e Kubernetes out of the box con discovery automatico di pod e servizi.
Sì. Raccolta e ricerca centralizzata dei log inclusa a 0,50€/GiB. Non serve uno stack ELK separato accanto al tuo monitoraggio.
Sì. Monitora fino a 3 server gratuitamente, per sempre. Tutte le funzionalità incluse — nessuna distinzione community vs. enterprise come Nagios Core vs. Nagios XI.
Sì. Bleemeo monitora dispositivi di rete e supporta SNMP insieme al monitoraggio di server e applicazioni — tutto in un'unica piattaforma.
Confronta Bleemeo anche con: