

Costruito su Prometheus e OpenTelemetry
Nessun vendor lock-in
Cerchi un'alternativa a Zabbix cloud-native? Zabbix è potente ma richiede competenze significative — espressioni trigger complesse, tuning del database e gestione dei proxy assorbono tempo ingegneristico. Bleemeo è la sostituzione di Zabbix ideale: stessa copertura con discovery automatico, zero database da mantenere e una UI moderna che il tuo team apprezzerà davvero.
Prova gratuita 15 giorniSenza carta di creditoSenza impegno a lungo termine
Nessun vendor lock-in
Dati conservati nell'UE · Conforme al GDPR
In tutta Europa e oltre
Più di 500 team dismettono i deployment Zabbix complessi
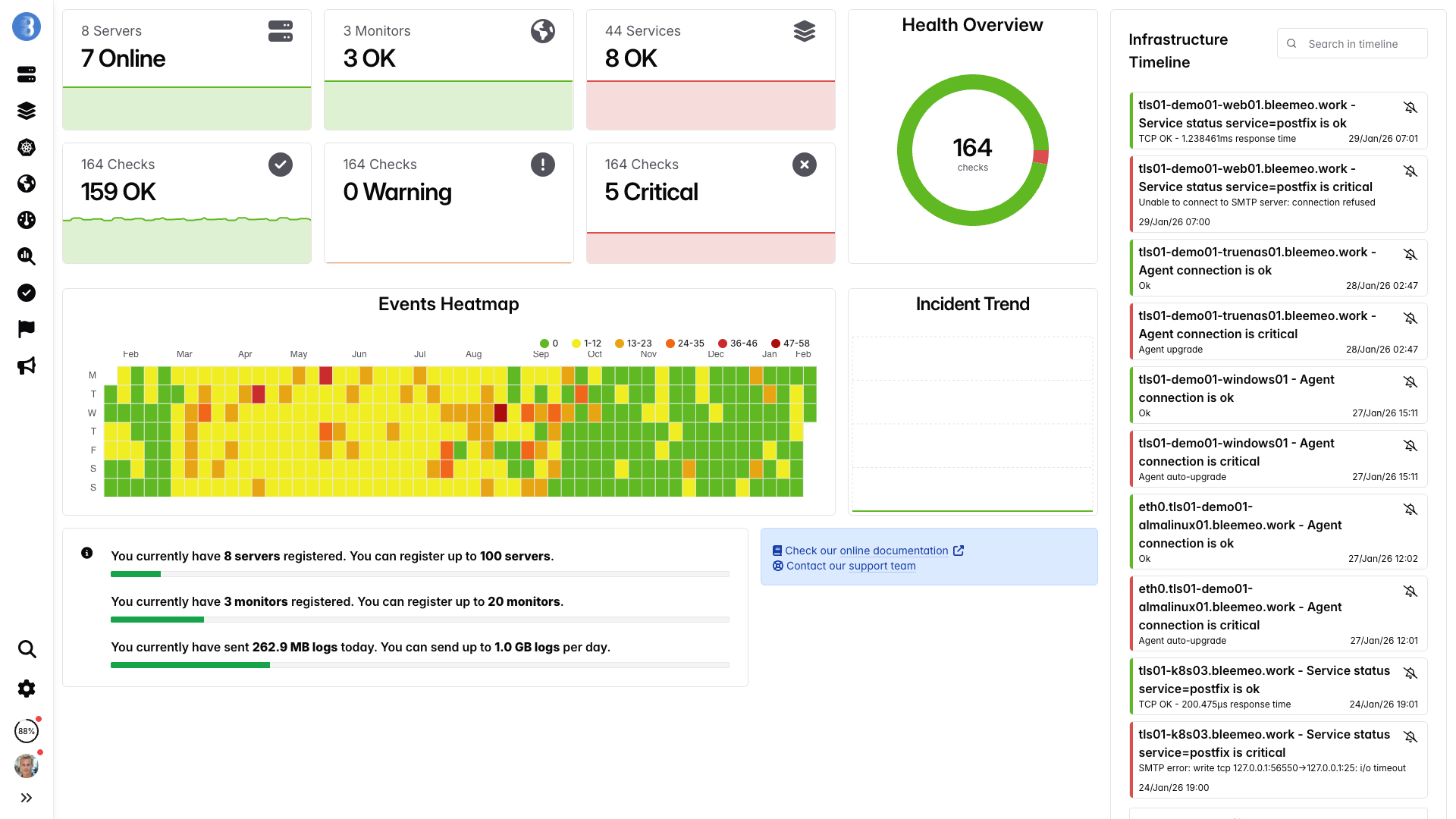
Dashboard in tempo reale, pronte in pochi minuti — nessuna configurazione necessaria
Dalla registrazione al dashboard in 30 secondi — senza tuning DB né trigger
Un comando, nessuna configurazione — metriche in flusso in meno di un minuto.
Perché cambiare
Gestire il database MySQL o PostgreSQL di Zabbix diventa un lavoro a tempo pieno su larga scala. Partizionare le tabelle di history e trend, ottimizzare query lente che paralizzano le performance delle dashboard ed eseguire routine di pulizia dell'housekeeper regolari sono sfide costanti che crescono con l'infrastruttura. Molti team scoprono troppo tardi che il loro server database necessita di un upgrade, portando a migrazioni d'emergenza e downtime imprevisti durante i periodi più intensi.
La terminologia di Zabbix — host, item, trigger, template, macro, regole di low-level discovery e calculated item — insieme a workflow complessi richiedono settimane o addirittura mesi per essere padroneggiati. Scrivere espressioni trigger corrette con funzioni come last(), avg() e nodata() richiede conoscenze specifiche che pochi ingegneri possiedono. I nuovi membri del team affrontano un processo di onboarding impegnativo prima di poter contribuire efficacemente, e corsi di formazione costosi sono spesso necessari per formare il personale.
Zabbix è stato progettato per ambienti statici on-premise dove i server hanno vita lunga e vengono provisionati manualmente. Il discovery automatico in Kubernetes e ambienti cloud dinamici richiede scripting personalizzato esteso, integrazioni esterne e aggiustamenti costanti dei template man mano che l'infrastruttura evolve. Container effimeri e gruppi di auto-scaling creano un flusso di registrazioni e deregistrazioni host che sovraccaricano il modello di gestione host di Zabbix, lasciando entry obsolete e grafici rotti.
Scalare Zabbix attraverso più data center o regioni richiede il deploy e la gestione di proxy Zabbix — ognuno un altro server da provisioning, configurare, monitorare e mantenere con il proprio database locale. L'architettura proxy introduce ulteriori punti di guasto e latenza nella raccolta delle metriche. I deployment su larga scala richiedono anche un'attenta pianificazione della capacità del database, e superare i limiti di throughput del database risulta in perdita di dati, avvisi ritardati e ingegneri frustrati che cercano di ripristinare il servizio durante incidenti critici.
Abbiamo configurato il monitoraggio di tutti i nostri server in poche ore. La dashboard è chiara, potente e davvero piacevole da usare.

Confronto
| Feature | Zabbix | Bleemeo |
|---|---|---|
| Gestione Database | Tuning MySQL/PostgreSQL richiesto | Completamente gestito, nessun DBA necessario |
| Complessità Setup | Configurazione server, database, web server | Installazione agente con una riga |
| Configurazione | Template, item, trigger, macro | Discovery automatico dei servizi |
| Scalabilità | Richiede proxy, partizionamento | Automatico, scaling illimitato |
| Supporto Kubernetes | Limitato, richiede discovery personalizzato | Integrazione nativa built-in |
| Alerting | Base, può causare tempeste di avvisi | Basato su ML con raggruppamento intelligente |
| Esperienza Mobile | UI web non ottimizzata per mobile | App native iOS e Android |
| Manutenzione | Aggiornamenti, backup, pulizia database | Zero manutenzione richiesta |
| Gestione Log | Supporto log item limitato | Aggregazione e ricerca log complete |
| Rilevamento Anomalie | Solo tuning manuale delle soglie | Rilevamento anomalie automatico basato su ML |
| Compatibilità Prometheus | Nessun supporto nativo Prometheus | Scraping nativo exporter Prometheus e PromQL |
| OpenTelemetry | Nessun supporto OpenTelemetry | Supporto completo ingestione OTLP |
| Interfaccia Utente | Funzionale ma datata | Moderna, intuitiva, responsive |
Archiviazione
Vantaggi
Costruito da zero per container, Kubernetes e infrastrutture cloud dinamiche — non adattato a posteriori come Zabbix. Il discovery automatico rileva nuovi servizi, container e pod nel momento in cui appaiono, senza template da configurare o regole di discovery da scrivere.
Nessun server Zabbix da provisioning, nessun database MySQL o PostgreSQL da ottimizzare e partizionare, nessun proxy da configurare per setup distribuiti. Basta installare l'agente leggero Bleemeo con un singolo comando e iniziare a monitorare in pochi secondi. Tutto il lavoro pesante viene gestito automaticamente nel cloud.
A differenza delle complesse espressioni trigger di Zabbix che richiedono tuning manuale delle soglie, Bleemeo utilizza il machine learning per rilevare automaticamente le anomalie basandosi sui pattern di comportamento normale della tua infrastruttura. Il routing intelligente degli alert, il raggruppamento e la deduplicazione prevengono l'affaticamento da notifiche che affligge i deployment Zabbix.
Gestisci milioni di metriche senza pianificare la capacità, configurare proxy Zabbix o partizionare tabelle database. Bleemeo scala automaticamente con la crescita della tua infrastruttura, da dieci server a diecimila, senza cliff di performance da raggiungere.
Mentre l'interfaccia web di Zabbix risulta datata e richiede navigazione in menu profondi, Bleemeo offre una dashboard pulita e moderna progettata per velocità e chiarezza. App mobile native iOS e Android permettono agli ingegneri di guardia di controllare lo stato e riconoscere gli alert da qualsiasi luogo.
Metriche, log e monitoraggio uptime tutti unificati in un'unica piattaforma — qualcosa che Zabbix non può offrire nativamente. Correla le metriche con gli eventi log in un'unica vista, riducendo il tempo medio di risoluzione ed eliminando il context-switching che rallenta la risposta agli incidenti.
Migrazione
La maggior parte dei team completa la migrazione da Zabbix a Bleemeo in una o due settimane, eseguendo entrambi i sistemi in parallelo per validare la copertura completa prima della dismissione. Il nostro team di supporto dedicato è disponibile durante l'intero processo di migrazione per rispondere alle domande, rivedere la configurazione e garantire che ogni host, servizio e regola di alert venga correttamente trasferito alla nuova piattaforma. Segui questi sei semplici passaggi per effettuare il passaggio.
Inizia documentando il tuo setup Zabbix esistente: elenca tutti gli host monitorati, item e template personalizzati, espressioni trigger e canali di notifica. Questo inventario garantisce che nulla venga tralasciato durante la transizione.
Installa l'agente leggero Bleemeo su tutti gli host monitorati usando un singolo comando. L'agente scopre automaticamente servizi in esecuzione, container e risorse di sistema — sostituendo decine di template Zabbix con zero configurazione:
wget -qO- 'https://get.bleemeo.com?accountId=...'Per qualsiasi item Zabbix personalizzato o script UserParameter, Bleemeo supporta exporter Prometheus, StatsD e un'API flessibile per metriche custom. La maggior parte dei servizi standard è già coperta dalle integrazioni built-in, quindi probabilmente scoprirai che molti item personalizzati non sono più necessari.
Configura i tuoi canali di notifica (email, Slack, PagerDuty, webhook) e imposta le soglie degli alert. Bleemeo include soglie predefinite sensate per le metriche comuni, quindi molte delle tue espressioni trigger Zabbix sono già coperte out of the box.
Esegui Bleemeo insieme a Zabbix per almeno una settimana per validare che tutti gli host, servizi e avvisi siano correttamente coperti. Confronta le dashboard fianco a fianco e verifica che le soglie degli alert corrispondano alle tue aspettative. Questa fase di esecuzione parallela è fondamentale per acquisire fiducia nella nuova piattaforma e identificare eventuali lacune nella copertura prima di impegnarti completamente nella transizione.
Una volta confermata la copertura completa, passa a Bleemeo come piattaforma di monitoraggio principale e inizia a dismettere la tua infrastruttura Zabbix. Rimuovi l'agente Zabbix da tutti gli host, spegni le istanze server e proxy Zabbix e recupera le risorse del server database. Il tuo team è finalmente libero dal partizionamento del database, dal tuning dell'housekeeper e dalla manutenzione dei proxy — e può reindirizzare quelle ore ingegneristiche verso la creazione di valore per i vostri clienti.
Costi
*Con prenotazione 1 anno. Log fatturati separatamente a 0,50€/GiB.
I numeri sopra assumono un'infrastruttura di 100 host. Inserisci il tuo numero di host e add-on per stimare il risparmio dismettendo il tuo deployment Zabbix.
Ingegneri e CTO si affidano a Bleemeo per monitorare la loro infrastruttura
Abbiamo bisogno che i nostri team restino concentrati sul nostro core business — il digital signage — piuttosto che sul monitoraggio dell'infrastruttura. Bleemeo supervisiona l'intero ambiente, dal server dedicato ad Azure, e libera i nostri team dagli alert inutili garantendo al contempo la nostra qualità del servizio.

Bleemeo ci accompagna da anni: un monitoraggio semplice e affidabile, essenziale per la qualità del servizio che dobbiamo ai nostri clienti.

On-premise o nel cloud, Bleemeo monitora i cluster Kubernetes dei miei clienti senza complessità. Uno strumento che consiglio per la sua semplicità e la chiarezza che offre.

Cliente fin dal primo giorno, sono entusiasta di Bleemeo. È facile da installare, efficiente e continua a migliorare!

Durante una breve pausa pranzo abbiamo installato Bleemeo, creato una metrica personalizzata, testato gli alert ed eravamo pronti per la produzione. La velocità di deployment è notevole.

Il supporto di Bleemeo è semplicemente leggendario: rapido, competente e sempre presente quando ne abbiamo bisogno.

Il deployment di Bleemeo è stato incredibilmente veloce. In circa un'ora lo abbiamo distribuito su più di 100 server e abbiamo immediatamente ottenuto piena visibilità sulla nostra infrastruttura.

Abbiamo configurato il monitoraggio di tutti i nostri server in poche ore. La dashboard è chiara, potente e davvero piacevole da usare.
Abbiamo distribuito Bleemeo su tutta la nostra infrastruttura server in poche ore. Il monitoraggio dell'uptime ci avvisa istantaneamente ogni volta che un servizio riscontra un problema.

Guarda la demo
Guarda come i team passano dall'installazione al monitoraggio completo in meno di 5 minuti
Sì. Bleemeo monitora server, servizi, container e Kubernetes con discovery automatico. Nessun template da importare, nessun trigger da scrivere, nessun database da mantenere.
No. Bleemeo è un SaaS completamente gestito con 13 mesi di retention delle metriche inclusi. Nessun tuning MySQL/PostgreSQL, nessun partizionamento tabelle, nessuna pianificazione dello storage.
Il discovery di Bleemeo è completamente automatico — installa l'agente e rileva i servizi in pochi secondi. Nessuna regola di low-level discovery, nessun host prototype, nessuna definizione di macro.
Sì. Ogni agente Bleemeo invia le metriche direttamente al cloud. Nessun livello proxy Zabbix necessario, nessun punto di guasto proxy, nessuna perdita di dati durante le interruzioni dei proxy.
Sì. Monitoraggio nativo Docker e Kubernetes con discovery automatico di pod e servizi. Nessun template personalizzato o regola di low-level discovery necessaria — a differenza di Zabbix dove il supporto container richiede configurazione significativa.
Sì. Raccolta e ricerca centralizzata dei log a 0,50€/GiB ingestiti. Nessuno strumento separato di gestione log necessario accanto alla piattaforma di monitoraggio.
Sì. Monitora fino a 3 server gratuitamente, per sempre. Tutte le funzionalità incluse — dashboard, avvisi, discovery dei servizi, app mobile.
Bleemeo è una piattaforma SaaS completamente gestita con ridondanza integrata. Non è necessario configurare cluster di server Zabbix o gestire il failover — l'alta disponibilità è inclusa.
Confronta Bleemeo anche con: