

Construit sur Prometheus & OpenTelemetry
Sans verrouillage fournisseur
Vous recherchez une alternative à Zabbix sans la complexité opérationnelle ? Zabbix est puissant mais exige une expertise et une maintenance significatives. Bleemeo est le remplacement de Zabbix idéal : un monitoring de classe enterprise cloud-native, sans tuning de base de données ni charge d'infrastructure à gérer.
Essai gratuit 15 joursSans carte bancaireSans engagement
Sans verrouillage fournisseur
Données hébergées dans l'UE · Conforme RGPD
À travers l'Europe et au-delà
Plus de 500 équipes retirent leurs déploiements Zabbix complexes
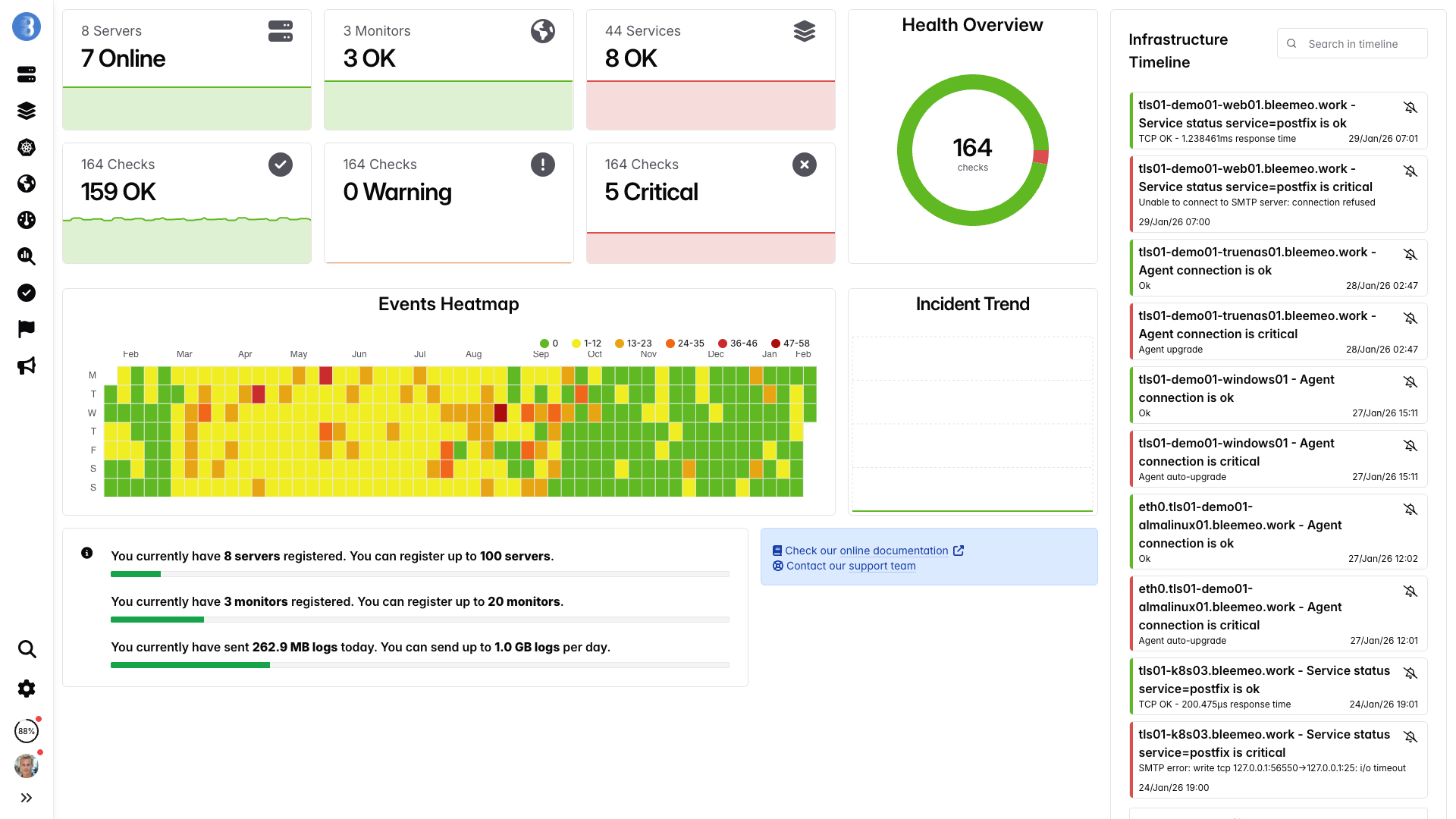
Tableaux de bord en temps réel, prêts en quelques minutes — aucune configuration nécessaire
De l'inscription au dashboard en 30 secondes — sans tuning DB ni triggers
Une commande, aucune configuration — les métriques arrivent en moins d'une minute.
Pourquoi changer
Gérer la base de données Zabbix devient un travail à temps plein à grande échelle. Le partitionnement des tables d'historique et de tendances sur plusieurs périodes de rétention, le tuning des requêtes lentes, le monitoring de l'espace disque et le nettoyage du housekeeper sont des défis constants qui nécessitent une expertise DBA dédiée. Avec Bleemeo, il n'y a aucune base de données à gérer — toutes les données sont stockées de manière transparente dans le cloud avec une rétention automatique et des performances de requête optimisées à n'importe quelle échelle.
La terminologie Zabbix — hôtes, items, triggers, modèles, macros, prototypes de découverte bas niveau — et les workflows complexes prennent des semaines à maîtriser pour les nouveaux membres de l'équipe. Écrire des expressions de triggers, concevoir des hiérarchies de modèles et comprendre le fonctionnement des macros sont autant de compétences qui doivent être acquises avant même que votre équipe puisse commencer à dépanner efficacement. L'interface intuitive de Bleemeo réduit ce temps d'intégration à un ou deux jours.
L'auto-découverte dans Kubernetes et les environnements cloud dynamiques nécessite des scripts personnalisés extensifs avec les règles LLD de Zabbix. Les conteneurs éphémères et les pods qui apparaissent et disparaissent créent des hôtes fantômes, des triggers orphelins et un bruit d'alertes qui submerge les équipes d'exploitation. Bleemeo a été construit nativement pour les environnements dynamiques, suivant automatiquement les conteneurs et pods sans aucune configuration.
L'architecture proxy de Zabbix pour le monitoring distribué ajoute de la complexité opérationnelle significative. Chaque proxy nécessite son propre serveur, sa propre base de données et sa propre maintenance, créant des points de défaillance supplémentaires et des pertes de données potentielles lors des pannes de proxy. Le scaling de Zabbix au-delà de quelques milliers d'hôtes nécessite une planification de capacité minutieuse, le partitionnement de la base de données et souvent plusieurs serveurs Zabbix avec un partage complexe. Bleemeo scale automatiquement en tant que SaaS cloud-natif, sans proxies, sans partitionnement et sans planification de capacité.
Nous avons déployé Bleemeo sur l'ensemble de notre infrastructure serveur en quelques heures seulement. Le monitoring de disponibilité nous alerte désormais instantanément dès qu'un service rencontre un problème.

Comparatif
| Feature | Zabbix | Bleemeo |
|---|---|---|
| Gestion BDD | Tuning MySQL/PostgreSQL requis | Entièrement géré, pas de DBA nécessaire |
| Complexité d'Installation | Serveur, BDD, serveur web à configurer | Installation agent en une ligne |
| Configuration | Modèles, items, triggers, macros | Découverte automatique des services |
| Scalabilité | Nécessite proxies, partitionnement | Scaling automatique et illimité |
| Support Kubernetes | Limité, nécessite découverte personnalisée | Intégration native intégrée |
| Alertes | Basiques, peuvent causer des tempêtes d'alertes | Basées sur ML avec regroupement intelligent |
| Expérience Mobile | Interface web non optimisée mobile | Apps natives iOS et Android |
| Maintenance | Mises à jour, sauvegardes, nettoyage BDD | Zéro maintenance requise |
| Gestion des Logs | Support log item limité | Agrégation et recherche de logs complètes |
| Détection d'Anomalies | Tuning de seuils manuels uniquement | Détection d'anomalies automatique basée sur ML |
| Compatibilité Prometheus | Pas de support Prometheus natif | Scraping natif des exporteurs Prometheus et PromQL |
| OpenTelemetry | Pas de support OpenTelemetry | Support complet d'ingestion OTLP |
| Interface Utilisateur | Fonctionnelle mais datée | Moderne, intuitive, responsive |
Stockage
Avantages
Construit de zéro pour les conteneurs, Kubernetes et l'infrastructure cloud dynamique — pas une adaptation comme Zabbix. L'auto-découverte détecte les nouveaux services, conteneurs et pods dès qu'ils apparaissent, sans modèles à configurer ni règles de découverte à écrire.
Pas de serveur Zabbix à provisionner, pas de base de données MySQL ou PostgreSQL à tuner et partitionner, pas de proxies à configurer pour les déploiements distribués. Installez simplement l'agent léger Bleemeo avec une seule commande et commencez à surveiller en quelques secondes. Tout le travail lourd est géré automatiquement dans le cloud.
Contrairement aux expressions de triggers complexes de Zabbix qui nécessitent un tuning manuel des seuils, Bleemeo utilise le machine learning pour détecter automatiquement les anomalies basées sur les patterns de comportement normaux de votre infrastructure. Le routage intelligent, le regroupement et la déduplication des alertes préviennent la fatigue de notification qui affecte les déploiements Zabbix.
Gérez des millions de métriques sans planifier la capacité, configurer des proxies Zabbix ou partitionner des tables de base de données. Bleemeo scale automatiquement au fur et à mesure que votre infrastructure grandit, de dix serveurs à dix mille, sans palier de performance à atteindre.
Alors que l'interface web de Zabbix semble datée et nécessite une navigation profonde dans les menus, Bleemeo offre un tableau de bord propre et moderne conçu pour la rapidité et la clarté. Les applications mobiles natives iOS et Android permettent aux ingénieurs d'astreinte de vérifier le statut et d'acquitter les alertes de n'importe où.
Métriques, logs et monitoring de disponibilité unifiés dans une seule plateforme — quelque chose que Zabbix ne peut pas offrir nativement. Corrélez les métriques avec les événements de logs dans une seule vue, réduisant le temps moyen de résolution et éliminant les changements de contexte qui ralentissent la réponse aux incidents.
Migration
La plupart des équipes complètent leur migration de Zabbix vers Bleemeo en une à deux semaines, en faisant fonctionner les deux systèmes en parallèle pour valider la couverture complète avant la désactivation. Notre équipe de support dédiée est disponible tout au long du processus de migration pour répondre aux questions, revoir votre configuration et s'assurer que chaque hôte, service et règle d'alerte est correctement transitionné vers la nouvelle plateforme. Suivez ces six étapes simples pour effectuer la bascule.
Commencez par documenter votre configuration Zabbix existante : listez tous les hôtes surveillés, les items et modèles personnalisés, les expressions de triggers et les canaux de notification. Cet inventaire assure que rien ne soit oublié pendant la transition.
Installez l'agent léger Bleemeo sur tous les hôtes surveillés avec une seule commande. L'agent découvre automatiquement les services en cours d'exécution, les conteneurs et les ressources système — remplaçant des dizaines de modèles Zabbix sans aucune configuration :
wget -qO- 'https://get.bleemeo.com?accountId=...'Pour les items Zabbix personnalisés ou les scripts UserParameter, Bleemeo supporte les exporteurs Prometheus, StatsD et une API de métriques personnalisées flexible. La plupart des services standards sont déjà couverts par les intégrations intégrées, vous constaterez donc probablement que de nombreux items personnalisés ne sont plus nécessaires.
Configurez vos canaux de notification (email, Slack, PagerDuty, webhooks) et définissez les seuils d'alerte. Bleemeo est livré avec des seuils par défaut pertinents pour les métriques courantes, donc beaucoup de vos expressions de triggers Zabbix sont déjà couvertes nativement.
Faites fonctionner Bleemeo à côté de Zabbix pendant au moins une semaine pour valider que tous les hôtes, services et alertes sont correctement couverts. Comparez les tableaux de bord côte à côte et vérifiez que les seuils d'alerte correspondent à vos attentes. Cette phase d'exécution parallèle est essentielle pour construire la confiance dans la nouvelle plateforme et identifier les éventuels écarts de couverture avant de vous engager pleinement dans la transition.
Une fois la couverture complète confirmée, passez à Bleemeo comme plateforme de monitoring principale et commencez à désactiver votre infrastructure Zabbix. Supprimez l'agent Zabbix de tous les hôtes, arrêtez les instances serveur et proxy Zabbix, et récupérez les ressources du serveur de base de données. Votre équipe est enfin libérée du partitionnement de base de données, du tuning du housekeeper et de la maintenance des proxies — et peut rediriger ces heures d'ingénierie vers la création de valeur pour vos clients.
Coûts
*Avec réservation 1 an. Logs facturés séparément à 0,50€/Gio.
Les chiffres ci-dessus reposent sur une infrastructure de 100 hôtes. Saisissez votre propre nombre d'hôtes et add-ons pour estimer vos économies en retirant votre déploiement Zabbix.
Ingénieurs et CTO font confiance à Bleemeo pour surveiller leur infrastructure
Nous avons besoin que nos équipes restent concentrées sur notre métier — l'affichage dynamique — plutôt que sur la surveillance d'infrastructure. Bleemeo supervise l'ensemble de notre environnement, du dédié à Azure, et libère nos équipes des alertes inutiles tout en garantissant notre qualité de service.

Bleemeo nous accompagne depuis des années : une supervision simple et fiable, essentielle pour la qualité de service que nous devons à nos clients.

On-premise ou cloud, Bleemeo supervise les clusters Kubernetes de mes clients sans complexité. Un outil que je recommande pour sa simplicité et la clarté qu'il apporte.

Client depuis le premier jour, je suis ravi de Bleemeo. C'est facile à installer, efficace, et ça ne cesse de s'améliorer !

Pendant une courte pause déjeuner, nous avons installé Bleemeo, créé une métrique personnalisée, testé les alertes et étions prêts pour la production. La rapidité de déploiement est remarquable.

Le support Bleemeo est tout simplement légendaire — rapide, compétent et toujours présent quand on en a besoin.

Le déploiement de Bleemeo a été incroyablement rapide. En environ une heure, nous l'avons déployé sur plus de 100 serveurs et avons immédiatement obtenu une visibilité complète sur notre infrastructure.

Nous avons mis en place le monitoring de tous nos serveurs en quelques heures seulement. Le tableau de bord est clair, puissant et véritablement agréable à utiliser.

Nous avons déployé Bleemeo sur l'ensemble de notre infrastructure serveur en quelques heures seulement. Le monitoring de disponibilité nous alerte désormais instantanément dès qu'un service rencontre un problème.
Démo
Découvrez comment les équipes passent de l'installation au monitoring complet en moins de 5 minutes
Oui. Bleemeo surveille les serveurs, services, conteneurs et Kubernetes avec la découverte automatique. Pas de modèles à importer, pas de triggers à écrire, pas de base de données à maintenir.
Non. Bleemeo est un SaaS entièrement géré avec 13 mois de rétention de métriques inclus. Pas de tuning MySQL/PostgreSQL, pas de partitionnement de tables, pas de planification de stockage.
La découverte de Bleemeo est entièrement automatique — installez l'agent et il détecte les services en quelques secondes. Pas de règles de découverte bas niveau, pas de prototypes d'hôtes, pas de définitions de macros.
Oui. Chaque agent Bleemeo envoie les métriques directement dans le cloud. Pas de couche proxy Zabbix nécessaire, pas de points de défaillance proxy, pas de perte de données lors des pannes de proxy.
Oui. Monitoring natif Docker et Kubernetes avec découverte automatique des pods et services. Pas de modèles personnalisés ni de règles de découverte bas niveau nécessaires — contrairement à Zabbix où le support des conteneurs nécessite une configuration significative.
Oui. Collecte et recherche centralisée des logs à 0,50€/Gio ingéré. Pas besoin d'un outil de gestion des logs séparé à côté de votre plateforme de monitoring.
Oui. Surveillez jusqu'à 3 serveurs gratuitement, sans limité de durée. Toutes les fonctionnalités incluses — tableaux de bord, alertes, découverte de services, applications mobiles.
Bleemeo est une plateforme SaaS entièrement gérée avec redondance intégrée. Pas besoin de configurer des clusters de serveurs Zabbix ou de gérer le failover — la haute disponibilité est incluse.
Comparez également Bleemeo à :