

Auf Prometheus und OpenTelemetry aufgebaut
Kein Vendor Lock-in
Auf der Suche nach einem Zabbix-Ersatz ohne Datenbank-Overhead? Zabbix ist leistungsstark, erfordert aber erhebliche Expertise -- komplexe Trigger-Ausdrücke, Datenbank-Tuning und Proxy-Verwaltung verbrauchen Engineering-Zeit. Bleemeo ist die Zabbix Alternative, die gleiche Abdeckung mit automatischer Erkennung, null Datenbank zu warten und einer modernen UI liefert, die Ihr Team tatsächlich gerne nutzen wird.
15 Tage kostenlos testenKeine Kreditkarte nötigKeine langfristige Bindung
Kein Vendor Lock-in
Daten bleiben in der EU · DSGVO-konform
In Europa und darüber hinaus
Über 500 Teams schalten komplexe Zabbix-Deployments ab
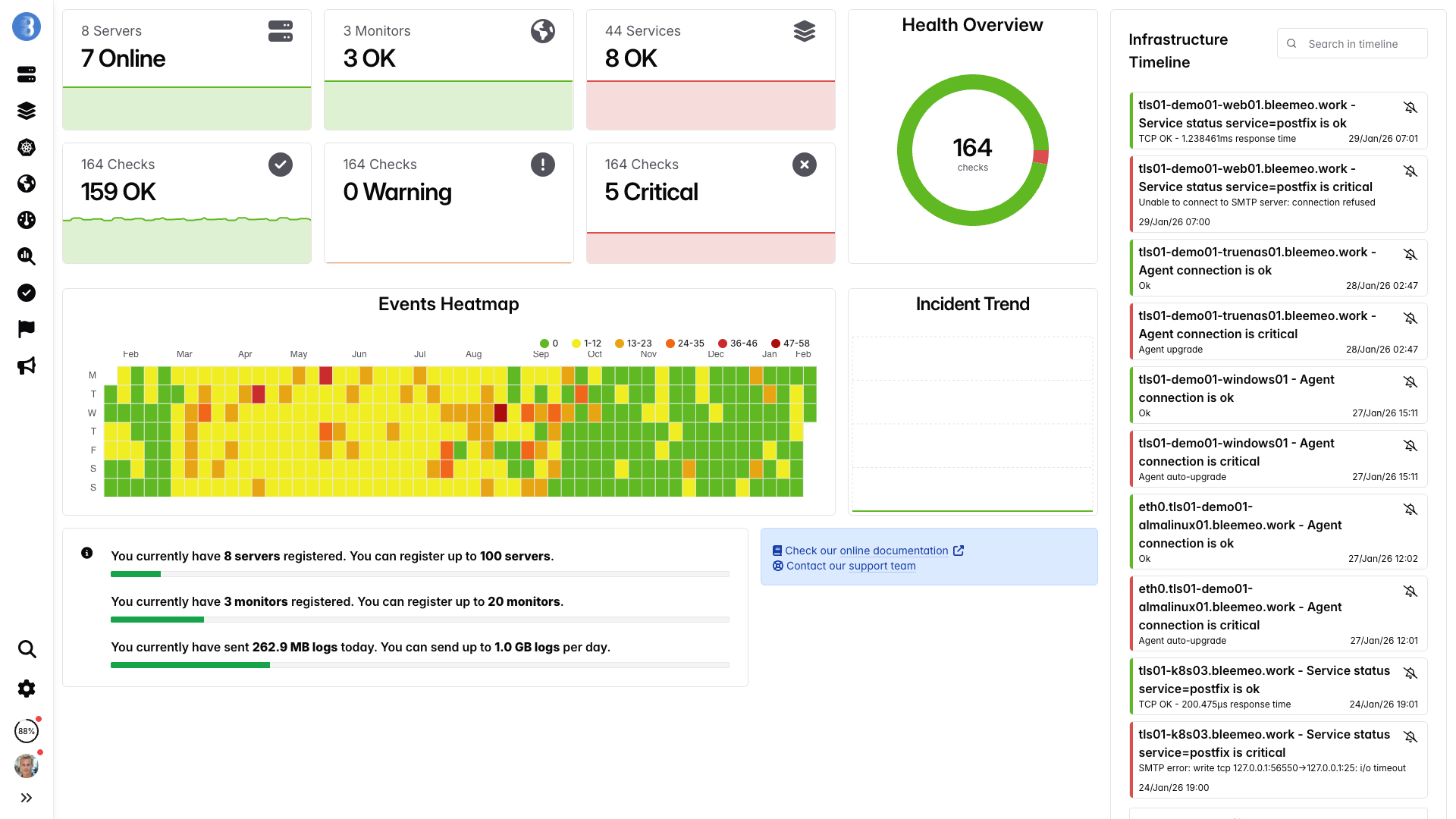
Echtzeit-Dashboards, in Minuten einsatzbereit -- keine Konfiguration nötig
Von der Anmeldung zum Dashboard in 30 Sekunden — ohne DB-Tuning und Trigger
Ein Befehl, keine Konfiguration — Metriken fließen in unter einer Minute.
Warum wechseln
Die Verwaltung von Zabbix' MySQL- oder PostgreSQL-Datenbank wird im großen Massstab zum Vollzeit-Job. Partitionierung von History- und Trend-Tabellen, Tuning langsamer Abfragen, die die Dashboard-Performance lahmlegen, und regelmäßige Housekeeper-Bereinigungsroutinen sind ständige Herausforderungen, die mit Ihrer Infrastruktur wachsen. Viele Teams stellen zu spaet fest, dass ihr Datenbankserver ein Upgrade benötigt, was zu Notfall-Migrationen und unerwarteten Ausfallzeiten führt.
Zabbix-Terminologie -- Hosts, Items, Trigger, Templates, Makros, Low-Level-Discovery-Regeln und berechnete Items -- zusammen mit komplexen Workflows benötigen Wochen oder sogar Monate zur Beherrschung. Das Schreiben korrekter Trigger-Ausdrücke mit Funktionen wie last(), avg() und nodata() erfordert tiefes Fachwissen. Neue Teammitglieder stehen vor einem einschüchternden Einarbeitungsprozess, und kostspielige Schulungskurse sind oft notwendig.
Zabbix wurde für statische, lokale Umgebungen entwickelt, in denen Server langlebig und manuell bereitgestellt sind. Auto-Discovery in Kubernetes und dynamischen Cloud-Umgebungen erfordert umfangreiches benutzerdefiniertes Scripting, externe Integrationen und ständige Template-Anpassungen. Ephemere Container und Auto-Scaling-Gruppen erzeugen eine Flut von Host-Registrierungen und -Abmeldungen, die Zabbix' Host-Verwaltungsmodell überfordern.
Die Skalierung von Zabbix über mehrere Rechenzentren oder Regionen erfordert die Bereitstellung und Verwaltung von Zabbix-Proxies -- jeder davon ein weiterer Server zum Provisionieren, Konfigurieren, Ueberwachen und Warten mit eigener lokaler Datenbank. Die Proxy-Architektur führt zusätzliche Ausfallpunkte und Latenz bei der Metrik-Erfassung ein. Große Bereitstellungen erfordern zudem sorgfältige Datenbank-Kapazitätsplanung.
Wir haben das Monitoring für alle unsere Server in nur wenigen Stunden eingerichtet. Das Dashboard ist übersichtlich, leistungsstark und macht wirklich Freude in der Nutzung.

Direkter Vergleich
| Feature | Zabbix | Bleemeo |
|---|---|---|
| Datenbank-Management | MySQL/PostgreSQL-Tuning erforderlich | Vollständig verwaltet, kein DBA benötigt |
| Einrichtungskomplexität | Server-, Datenbank-, Webserver-Konfiguration | Einzeilen-Agent-Installation |
| Konfiguration | Templates, Items, Trigger, Makros | Automatische Dienst-Erkennung |
| Skalierbarkeit | Erfordert Proxies, Partitionierung | Automatische, unbegrenzte Skalierung |
| Kubernetes-Unterstützung | Eingeschränkt, erfordert benutzerdefinierte Erkennung | Native Integration integriert |
| Alarmierung | Einfach, kann Alarm-Stürme verursachen | ML-basiert mit intelligenter Gruppierung |
| Mobile Erfahrung | Web-UI nicht mobil-optimiert | Native iOS- & Android-Apps |
| Wartung | Updates, Backups, Datenbank-Bereinigung | Null Wartung erforderlich |
| Log-Management | Eingeschränkte Log-Item-Unterstützung | Vollständige Log-Aggregation & -Suche |
| Anomalieerkennung | Nur manuelle Schwellenwert-Anpassung | ML-basierte automatische Anomalieerkennung |
| Prometheus-Kompatibilität | Keine native Prometheus-Unterstützung | Natives Prometheus-Exporter-Scraping und PromQL |
| OpenTelemetry | Keine OpenTelemetry-Unterstützung | Volle OTLP-Aufnahme-Unterstützung |
| Benutzeroberfläche | Funktional, aber veraltet | Modern, intuitiv, responsiv |
Speicher
Vorteile
Von Grund auf für Container, Kubernetes und dynamische Cloud-Infrastruktur entwickelt -- nicht nachgerüstet wie Zabbix. Auto-Discovery erkennt neue Dienste, Container und Pods in dem Moment, in dem sie erscheinen, ohne Templates zu konfigurieren oder Discovery-Regeln zu schreiben.
Kein Zabbix-Server zu provisionieren, keine MySQL- oder PostgreSQL-Datenbank zu tunen und zu partitionieren, keine Proxies für verteilte Setups zu konfigurieren. Installieren Sie einfach den leichtgewichtigen Bleemeo-Agent mit einem einzigen Befehl und beginnen Sie innerhalb von Sekunden mit dem Monitoring. Die gesamte Schwerstarbeit wird automatisch in der Cloud erledigt.
Anders als Zabbix' komplexe Trigger-Ausdrücke, die manuelle Schwellenwert-Anpassung erfordern, nutzt Bleemeo maschinelles Lernen, um Anomalien automatisch auf Basis der normalen Verhaltensmuster Ihrer Infrastruktur zu erkennen. Intelligentes Alarm-Routing, Gruppierung und Deduplizierung verhindern die Benachrichtigungs-Müdigkeit, die Zabbix-Bereitstellungen plagt.
Verarbeiten Sie Millionen von Metriken ohne Kapazitätsplanung, Konfiguration von Zabbix-Proxies oder Partitionierung von Datenbanktabellen. Bleemeo skaliert automatisch mit Ihrer wachsenden Infrastruktur, von zehn Servern bis zehntausend, ohne Performance-Klippe.
Während Zabbix' Web-Oberfläche veraltet wirkt und tiefe Menu-Navigation erfordert, bietet Bleemeo ein sauberes, modernes Dashboard, das auf Geschwindigkeit und Klarheit ausgelegt ist. Native iOS- und Android-Mobile-Apps lassen Bereitschafts-Ingenieure von überall Status prüfen und Alarme bestätigen.
Metriken, Logs und Verfügbarkeits-Monitoring in einer einzigen Plattform vereint -- etwas, das Zabbix nativ nicht bieten kann. Korrelieren Sie Metriken mit Log-Ereignissen in einer Ansicht, reduzieren Sie die mittlere Wiederherstellungszeit und eliminieren Sie den Kontextwechsel, der die Vorfallreaktion verlangsamt.
Migration
Die meisten Teams schließen ihre Migration von Zabbix zu Bleemeo innerhalb von ein bis zwei Wochen ab und betreiben beide Systeme parallel, um die vollständige Abdeckung vor der Dekommissionierung zu validieren. Unser Support-Team steht während des gesamten Migrationsprozesses zur Verfügung. Folgen Sie diesen sechs einfachen Schritten.
Beginnen Sie mit der Dokumentation Ihrer bestehenden Zabbix-Einrichtung: listen Sie alle überwachten Hosts, benutzerdefinierten Items und Templates, Trigger-Ausdrücke und Benachrichtigungskanäle auf. Dieses Inventar stellt sicher, dass beim Uebergang nichts verloren geht.
Installieren Sie den leichtgewichtigen Bleemeo-Agent auf allen überwachten Hosts mit einem einzigen Befehl. Der Agent erkennt automatisch laufende Dienste, Container und Systemressourcen -- und ersetzt Dutzende von Zabbix-Templates ohne Konfiguration:
wget -qO- 'https://get.bleemeo.com?accountId=...'Für benutzerdefinierte Zabbix-Items oder UserParameter-Skripte unterstützt Bleemeo Prometheus-Exporter, StatsD und eine flexible API für benutzerdefinierte Metriken. Die meisten Standarddienste werden bereits durch integrierte Integrationen abgedeckt, sodass Sie feststellen werden, dass viele benutzerdefinierte Items nicht mehr benötigt werden.
Konfigurieren Sie Ihre Benachrichtigungskanäle (E-Mail, Slack, PagerDuty, Webhooks) und richten Sie Alarm-Schwellenwerte ein. Bleemeo kommt mit sinnvollen Standard-Schwellenwerten für gängige Metriken, sodass viele Ihrer Zabbix-Trigger-Ausdrücke bereits sofort abgedeckt sind.
Betreiben Sie Bleemeo mindestens eine Woche lang neben Zabbix, um zu validieren, dass alle Hosts, Dienste und Alarme ordnungsgemäß abgedeckt sind. Vergleichen Sie Dashboards nebeneinander und überprüfen Sie, dass Alarm-Schwellenwerte Ihren Erwartungen entsprechen. Diese Parallelbetriebsphase ist entscheidend für den Aufbau von Vertrauen in die neue Plattform.
Sobald Sie die volle Abdeckung bestätigt haben, wechseln Sie zu Bleemeo als primäres Monitoring und beginnen Sie mit der Dekommissionierung Ihrer Zabbix-Infrastruktur. Entfernen Sie den Zabbix-Agent von allen Hosts, fahren Sie den Zabbix-Server und die Proxy-Instanzen herunter und geben Sie die Datenbankserver-Ressourcen frei. Ihr Team ist endlich frei von Datenbank-Partitionierung, Housekeeper-Tuning und Proxy-Wartung.
Kosten
*Mit 1-Jahres-Reservierung. Logs separat berechnet: 0,50 EUR/GiB.
Die Zahlen oben gehen von einer 100-Host-Infrastruktur aus. Geben Sie Ihre eigene Host-Anzahl und Add-ons ein, um Ihre Einsparungen beim Abschalten Ihres Zabbix-Deployments zu schätzen.
Ingenieure und CTOs vertrauen auf Bleemeo für ihr Infrastruktur-Monitoring
Unsere Teams müssen sich auf unser Kerngeschäft konzentrieren können — Digital Signage — statt auf die Infrastrukturüberwachung. Bleemeo überwacht unsere gesamte Umgebung, vom dedizierten Server bis Azure, und befreit unsere Teams von unnötigen Alerts, während es gleichzeitig unsere Servicequalität sicherstellt.

Bleemeo begleitet uns seit Jahren: eine einfache und zuverlässige Überwachung, die für die Servicequalität, die wir unseren Kunden schulden, unverzichtbar ist.

On-Premise oder in der Cloud — Bleemeo überwacht die Kubernetes-Cluster meiner Kunden ganz ohne Komplexität. Ein Tool, das ich für seine Einfachheit und die gebotene Übersichtlichkeit empfehle.

Kunde seit dem ersten Tag — ich bin begeistert von Bleemeo. Es ist einfach zu installieren, effizient und wird ständig besser!

Während einer kurzen Mittagspause haben wir Bleemeo installiert, eine benutzerdefinierte Metrik erstellt, Alerts getestet und waren produktionsbereit. Die Geschwindigkeit der Bereitstellung ist bemerkenswert.

Der Bleemeo-Support ist schlicht legendär — schnell, kompetent und immer da, wenn wir ihn brauchen.

Bleemeo war unglaublich schnell einzurichten. In etwa einer Stunde haben wir es auf über 100 Servern ausgerollt und sofort volle Sicht auf unsere Infrastruktur erhalten.

Wir haben das Monitoring für alle unsere Server in nur wenigen Stunden eingerichtet. Das Dashboard ist übersichtlich, leistungsstark und macht wirklich Freude in der Nutzung.
Wir haben Bleemeo in nur wenigen Stunden auf unserer gesamten Server-Infrastruktur ausgerollt. Das Uptime-Monitoring benachrichtigt uns jetzt sofort, wenn ein Dienst ein Problem hat.

Live ansehen
Sehen Sie, wie Teams in unter 5 Minuten von der Installation zum vollständigen Monitoring gelangen
Ja. Bleemeo überwacht Server, Dienste, Container und Kubernetes mit automatischer Erkennung. Keine Templates zu importieren, keine Trigger zu schreiben, keine Datenbank zu warten.
Nein. Bleemeo ist vollständig verwaltetes SaaS mit 13 Monate Metrik-Aufbewahrung inklusive. Kein MySQL/PostgreSQL-Tuning, keine Tabellenpartitionierung, keine Speicherplanung.
Bleemeos Erkennung ist vollautomatisch -- installieren Sie den Agent und er erkennt Dienste innerhalb von Sekunden. Keine Low-Level-Discovery-Regeln, keine Host-Prototypen, keine Makro-Definitionen.
Ja. Jeder Bleemeo-Agent sendet Metriken direkt in die Cloud. Keine Zabbix-Proxy-Schicht nötig, keine Proxy-Ausfallpunkte, kein Datenverlust bei Proxy-Ausfällen.
Ja. Natives Docker- und Kubernetes-Monitoring mit automatischer Pod- und Dienst-Erkennung. Keine benutzerdefinierten Templates oder Low-Level-Discovery-Regeln nötig -- im Gegensatz zu Zabbix, wo die Container-Unterstützung erhebliche Konfiguration erfordert.
Ja. Zentralisierte Log-Sammlung und -Suche für 0,50 EUR/GiB. Kein separates Log-Management-Tool neben Ihrer Monitoring-Plattform nötig.
Ja. Ueberwachen Sie bis zu 3 Server kostenlos, für immer. Alle Funktionen inklusive -- Dashboards, Alarme, Diensterkennung, Mobile Apps.
Bleemeo ist eine vollständig verwaltete SaaS-Plattform mit integrierter Redundanz. Kein Aufsetzen von Zabbix-Server-Clustern oder Verwalten von Failover nötig -- Hochverfügbarkeit ist inklusive.
Vergleichen Sie Bleemeo auch mit: