

Auf Prometheus und OpenTelemetry aufgebaut
Kein Vendor Lock-in
UptimeRobot macht eine Sache: URLs aus dem öffentlichen Internet anzupingen und einen Alarm zu senden, wenn einer fehlschlägt. Sobald Sie wissen wollen, warum ein Check fehlgeschlagen ist — langsame Datenbank, überlasteter Server, fehlgeschlagenes Deployment — beginnen Sie einen zweiten Monitoring-Stack zusammenzustellen. Bleemeo bündelt Uptime-Monitoring mit Server-, Container- und Anwendungs-Monitoring, privaten Sonden und automatischen öffentlichen Statusseiten. Ein Agent. Eine Plattform. Eine Rechnung.
15 Tage kostenlos testenKeine Kreditkarte nötigKeine langfristige Bindung
Kein Vendor Lock-in
Daten bleiben in der EU · DSGVO-konform
In Europa und darüber hinaus
Über 500 Teams konsolidieren Uptime- und Infrastruktur-Monitoring
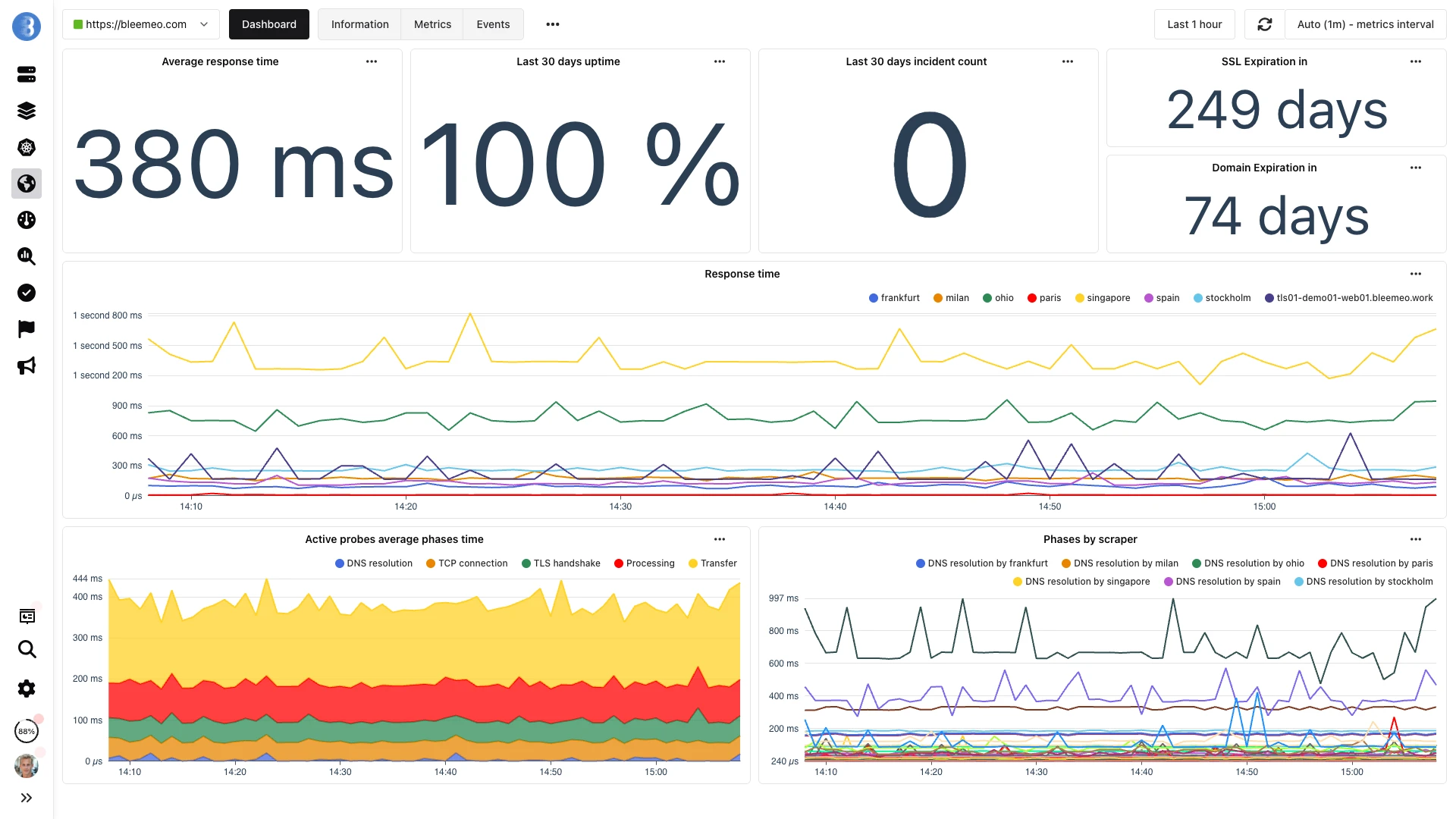
Uptime, Latenz und Zertifikatsgesundheit — alles im selben Dashboard wie Ihre Infrastrukturmetriken
Von der Anmeldung zum Dashboard in 30 Sekunden — Uptime, Infra und Logs an einem Ort
Ein Befehl, keine Konfiguration — Metriken fließen in unter einer Minute.
Warum wechseln
Die Sonden von UptimeRobot leben im öffentlichen Internet, was perfekt ist, um die Startseite Ihrer Marketing-Website zu prüfen, aber nutzlos für alles hinter einer VPN oder Firewall. Interne APIs, Staging-Umgebungen, Admin-Dashboards und private Kubernetes-Dienste bleiben ein blinder Fleck, es sei denn, Sie riskieren, sie öffentlich verfügbar zu machen, nur damit UptimeRobot sie erreichen kann. Teams enden damit, ein zweites Monitoring-Tool für ihre interne Oberfläche zu pflegen — genau die Art von Wildwuchs, die ein dediziertes Uptime-Tool eigentlich verhindern sollte.
Ein UptimeRobot-Alarm sagt Ihnen, dass eine URL nicht mehr antwortet, aber nicht warum. War die Datenbank langsam? Wurde ein Container OOM-killed? Hat ein kürzliches Deployment eine Regression eingeführt? Sie beantworten diese Fragen per SSH auf Server oder indem Sie zu einem zweiten Monitoring-Tool wechseln — was den Sinn des Uptime-Alarms selbst aushebelt. Das erste Signal kommt ohne den umliegenden Kontext, der den Vorfall handlungsfähig machen würde.
Jeder neue Dienst bedeutet eine weitere URL, die von Hand registriert werden muss. Wenn Sie drei Microservices zu einem Kubernetes-Deployment hinzufügen, ahnt UptimeRobot nichts davon — Sie müssen die UI öffnen, jede URL einfügen, ein Check-Intervall wählen und daran denken, aufzuräumen, wenn ein Dienst außer Betrieb geht. In einer schnelllebigen Umgebung türmt sich dieser Verwaltungsaufwand so weit auf, dass das Tool sich mit der Realität desynchronisiert und tote URLs still aus der Abdeckung fallen oder Zombie-Monitore Fehlalarme auslösen.
UptimeRobot ist absichtlich eng — es pingt Endpoints, Punkt. Es sieht weder den Host, der Ihren Dienst ausführt, noch den Container, der Ihre App hostet, noch die Datenbank, die Ihre API speist, noch die Logs, die Ihre Anwendung beim Crash ausgibt. Jedes zusätzliche Signal erfordert ein weiteres Tool, einen weiteren Anbieter, ein weiteres Dashboard, das man im Blick behalten muss. Was auf dem Papier günstig aussieht, wird zu einem fragmentierten Stack, in dem kein einzelnes Tool genug Informationen hat, um einen Vorfall End-to-End zu debuggen.
Während einer kurzen Mittagspause haben wir Bleemeo installiert, eine benutzerdefinierte Metrik erstellt, Alerts getestet und waren produktionsbereit. Die Geschwindigkeit der Bereitstellung ist bemerkenswert.

Direkter Vergleich
| Feature | UptimeRobot | Bleemeo |
|---|---|---|
| Check-Typen | HTTP, HTTPS, Keyword-Match, Port (TCP), Ping — fünf Typen in den kostenpflichtigen Tarifen | HTTP, HTTPS, TCP, ICMP (Ping), SSL-TCP — mit erwarteten Statuscodes, Body-Matching und benutzerdefinierten Headern |
| Private Sonden | Eingeschränkt — erfordert einen kostenpflichtigen Tarif und eine separate Agent-Bereitstellung | Unbegrenzt — jeder bereitgestellte Glouton-Agent ist automatisch eine private Sonde ohne Zusatzkosten |
| Öffentliche Sonden | Mehrere Regionen weltweit | Frankfurt, Mailand, Paris, Ohio und Singapur |
| SSL-Zertifikats-Ablauf | Verfügbar, pro Monitor verfolgt | Automatisch bei jedem HTTPS-Monitor: Warnung 20 Tage, kritisch 10 Tage vorher |
| Domain-Ablauf | Verfügbar als separater Monitor-Typ | Automatisch über WHOIS, gleiche Schwellwerte wie SSL (20 / 10 Tage) |
| Öffentliche Statusseite | Verfügbar, volles Branding höheren Tarifen vorbehalten | Gebrandete Seite unter status.bleemeo.com/<slug>/, automatisch aus Anwendungen gespeist, in jedem kostenpflichtigen Plan enthalten |
| Automatische Diensterkennung | Jede URL muss manuell hinzugefügt werden | Glouton erkennt über 100 Dienste (Datenbanken, Webserver, Queues) und überwacht sie automatisch ohne Konfiguration |
| Anwendungs-Gruppierung | Jeder Monitor ist unabhängig — kein Konzept einer Anwendung, die mehrere Checks zusammenfasst | Dienste und Monitore als Anwendung taggen; die Gesundheit wird zu einem einzigen Indikator und Alarm verdichtet |
| Server-Monitoring | Nicht enthalten — erfordert ein separates Tool | CPU, Speicher, Disk, Netzwerk, Prozesse auf jedem Agent, im selben Dashboard wie Uptime |
| Container / Kubernetes | Nicht unterstützt | Docker, containerd und Kubernetes nativ unterstützt, mit automatischer Erkennung von Pods und Services |
| Log-Management | Nicht enthalten | Integrierte Log-Erfassung zu 0,50€/GiB aufgenommen, korreliert mit Uptime- und Infrastruktursignalen |
| Prometheus-Kompatibilität | Nicht zutreffend — keine Metrikaufnahme | Native PromQL-Abfragen, Scraping jedes /metrics-Endpoints, Recording- und Alerting-Regeln |
| Mobile Apps | iOS & Android | iOS & Android mit Push-Benachrichtigungen |
| Datenstandort | In den USA gehostete Infrastruktur | In der EU gehostet mit integrierter DSGVO-Konformität |
Private Sonden, automatisch erkannte Dienste und eine öffentliche Statusseite — alles in einer 15-tägigen kostenlosen Testversion. Keine Kreditkarte.
Vorteile
Jeder Glouton-Agent, den Sie für das Infrastruktur-Monitoring bereitstellen, dient gleichzeitig als Uptime-Sonde. Richten Sie ihn auf eine interne URL — eine Staging-API, ein Admin-Dashboard, einen internen Kubernetes-Dienst — und die Verfügbarkeitsmetrik fließt in dieselbe Bleemeo-Plattform wie Ihre öffentlichen Checks. Keine VPN-Tunnel, keine zusätzlichen Firewall-Regeln, kein öffentliches Exponieren interner Endpoints, nur um ein Monitoring-Tool zufriedenzustellen. Unbegrenzte private Sonden sind in jedem kostenpflichtigen Plan enthalten — die größte Lücke in der Abdeckung von UptimeRobot für Teams mit ernsthaften privaten Netzwerken.
Glouton inspiziert laufende Container und Prozesse und erkennt automatisch mehr als 100 Dienste — PostgreSQL, Redis, NGINX, RabbitMQ, Kafka, MinIO und viele weitere. Einmal erkannt, erhält jeder Dienst seine spezifischen Metriken und trägt zur Gesundheit seiner übergeordneten Anwendung bei. Sie müssen nicht jeden Dienst als separaten Monitor registrieren, wie Sie es in UptimeRobot tun würden — Änderungen in der Infrastruktur werden automatisch reflektiert, sodass die Abdeckung im Einklang mit der Realität bleibt.
Eine Anwendung in Bleemeo ist einfach ein Tag. Gruppieren Sie die Dienste und Monitore, die ein Produkt tragen, unter demselben Tag, klicken Sie auf „Veröffentlichen", und eine gebrandete öffentliche Statusseite erscheint unter status.bleemeo.com/<slug>/. Die Seite spiegelt die Echtzeit-Verfügbarkeit wider, berechnet aus exakt denselben Daten, die Ihr Bereitschaftsteam intern nutzt — kein separates Statusseiten-Tool, keine Duplizierung, keine Abweichung zwischen dem, was Sie sehen, und dem, was Kunden sehen. In jedem kostenpflichtigen Plan ohne Zusatzkosten enthalten.
Jeder HTTPS-Monitor verfolgt automatisch den Ablauf des SSL-Zertifikats und das WHOIS-Ablaufdatum der Domain. Ein Warn-Alarm wird 20 Tage vor Ablauf ausgelöst, ein kritischer Alarm 10 Tage vorher. Kein separater Monitor zu konfigurieren, kein Drittanbieter-Zertifikats-Tracking-Tool, kein Lesen von Cron-Job-Ausgaben — der Alarm trifft im selben Kanal ein wie der Rest Ihres Monitorings, mit genug Vorlauf zum Rotieren oder Erneuern.
Glouton ist Ihre Uptime-Sonde, Ihr Server-Metrik-Agent, Ihr Container-Metrik-Agent, Ihr Prometheus-Scraper und Ihr Log-Versender — alles in einem Binary. Wenn ein HTTP-Monitor fehlschlägt, haben Sie die Host-Metriken, die Container-Neustart-Historie, die Anwendungslogs und die Prometheus-Metriken der unterliegenden Dienste alle auf derselben Plattform, auf derselben Zeitachse. Die Ursachenanalyse wird zur Frage des Scrollens, nicht des Hin- und Herspringens zwischen fünf Tools, in der Hoffnung, dass deren Uhren übereinstimmen.
Die Bleemeo-Infrastruktur ist in der Europäischen Union gehostet. Alle Uptime-Metriken, Logs und Monitoring-Daten bleiben in EU-Rechenzentren, mit integrierter DSGVO-Konformität im Produkt. Für Organisationen mit Anforderungen an europäische Datensouveränität oder branchenspezifischen Regularien (Banken, Gesundheitswesen, öffentliche Dienste) entfällt damit die Reibung durch transatlantische Datenflüsse, die in den USA gehostete Monitoring-Anbieter nicht vollständig vermeiden können.
Statusseiten
Gruppieren Sie Dienste und Monitore unter einem Anwendungs-Tag, klicken Sie auf Veröffentlichen, und Ihre öffentliche Statusseite geht live unter status.bleemeo.com/<slug>/ — ohne separates Statusseiten-Tool, ohne zusätzliche Konfiguration.

Funktionen
CPU, Speicher, Disk, Netzwerkdurchsatz und Sichtbarkeit auf Prozessebene auf jedem Host, auf dem Glouton läuft. Korrelieren Sie einen fehlschlagenden Uptime-Check in Sekunden mit einer vollen Disk, einem ausufernden Prozess oder einem OOM-gekillten Container — ohne sich auf die Maschine einloggen zu müssen.
Natives Monitoring von Docker, containerd und Kubernetes mit CPU, Speicher, I/O und HEALTHCHECK-Status pro Container. Die Service-Erkennung reflektiert Pod-Lifecycle-Events in Echtzeit.
Gruppieren Sie Dienste und Uptime-Monitore per Tag in Anwendungen. Die Gesundheit wird auf einen einzigen Indikator verdichtet; ein einziger Alarm deckt die gesamte Abhängigkeitskette ab.
Zentralisierte Logs mit stdout- und stderr-Erfassung aus jedem Container, durchsuchbar auf derselben Zeitleiste wie Metriken und Uptime-Events. Pauschale 0,50€/GiB Aufnahme, keine Indexierungs-Zuschläge.
Native PromQL-Abfragen und Prometheus-kompatibler Speicher. Glouton scrapt jeden /metrics-Endpoint, auf den Sie es richten, sodass Sie Ihre bestehenden Recording- und Alerting-Regeln unverändert übernehmen können.
ML-basierte Anomalieerkennung reduziert Fehlalarme; Alarme verteilen sich auf E-Mail, Slack, Microsoft Teams, PagerDuty, Webhooks und iOS / Android Push — alle Kanäle inklusive.
Migration
Die meisten Teams schließen eine UptimeRobot-Migration an einem Nachmittag ab. Die Monitorliste ist klein genug, um sie per Hand (oder über die API) neu anzulegen, und da Bleemeo seine Sonden auf paralleler Infrastruktur betreibt, können Sie UptimeRobot aktiv lassen, bis Sie sich bei der Abdeckung sicher sind. Unser Engineering- Team unterstützt größere Migrationen ohne Zusatzkosten.
Holen Sie die Liste der aktiven Monitore aus dem UptimeRobot-Dashboard oder der API. Für die meisten Teams ist das eine kurze Tabelle mit URL, Check-Typ, erwartetem Status und Benachrichtigungsregeln. Gruppieren Sie die Monitore nach der Anwendung, zu der sie gehören — Sie werden diese Gruppierung in Bleemeo wiederverwenden.
Öffnen Sie im Bleemeo-Panel den Bereich Monitors und legen Sie HTTP-/HTTPS-/TCP-/ICMP-/SSL-TCP-Monitore passend zu Ihrer Liste an. Wählen Sie die gewünschten öffentlichen Sonden (Frankfurt, Mailand, Paris, Ohio, Singapur) und fügen Sie private Sonden hinzu, die auf bereits bereitgestellte Glouton-Agenten zeigen.
Für URLs, die aus dem öffentlichen Internet nicht erreichbar sind — Staging-Umgebungen, Admin-Oberflächen, interne APIs — installieren Sie Glouton auf einem Host innerhalb des relevanten Netzwerks. Der Agent erscheint automatisch als verfügbare Sonde in der Monitor-UI und beginnt, Latenz und Verfügbarkeit aus dieser privaten Position zu melden.
wget -qO- 'https://get.bleemeo.com?accountId=...'Taggen Sie jeden Monitor mit der Anwendung, zu der er gehört (checkout, billing, marketing-site). Bleemeo gruppiert die getaggten Monitore automatisch — zusammen mit allen erkannten Diensten, die denselben Tag tragen — in einer einzigen Anwendungsansicht mit einem konsolidierten Gesundheitsindikator.
Wählen Sie im Bereich Anwendungen die Anwendungen aus, die Kunden sehen sollen, geben Sie der Seite einen Slug und klicken Sie auf Veröffentlichen. Die Seite geht sofort unter status.bleemeo.com/<slug>/ online und aktualisiert sich in Echtzeit aus denselben Uptime-Daten, auf die sich Ihr Bereitschaftsteam verlässt.
Betreiben Sie UptimeRobot und Bleemeo eine Woche lang parallel. Vergleichen Sie Alarm-Zeitpunkte, Antwortzeit-Diagramme und Statusseiten-Ausgaben. Sobald die Alarme übereinstimmen und das Team sich wohlfühlt, deaktivieren Sie die UptimeRobot-Monitore und aktualisieren Sie die Benachrichtigungs-Integrationen.
Ingenieure und CTOs vertrauen auf Bleemeo für ihr Infrastruktur-Monitoring
Unsere Teams müssen sich auf unser Kerngeschäft konzentrieren können — Digital Signage — statt auf die Infrastrukturüberwachung. Bleemeo überwacht unsere gesamte Umgebung, vom dedizierten Server bis Azure, und befreit unsere Teams von unnötigen Alerts, während es gleichzeitig unsere Servicequalität sicherstellt.

Bleemeo begleitet uns seit Jahren: eine einfache und zuverlässige Überwachung, die für die Servicequalität, die wir unseren Kunden schulden, unverzichtbar ist.

On-Premise oder in der Cloud — Bleemeo überwacht die Kubernetes-Cluster meiner Kunden ganz ohne Komplexität. Ein Tool, das ich für seine Einfachheit und die gebotene Übersichtlichkeit empfehle.

Kunde seit dem ersten Tag — ich bin begeistert von Bleemeo. Es ist einfach zu installieren, effizient und wird ständig besser!

Während einer kurzen Mittagspause haben wir Bleemeo installiert, eine benutzerdefinierte Metrik erstellt, Alerts getestet und waren produktionsbereit. Die Geschwindigkeit der Bereitstellung ist bemerkenswert.
Der Bleemeo-Support ist schlicht legendär — schnell, kompetent und immer da, wenn wir ihn brauchen.

Bleemeo war unglaublich schnell einzurichten. In etwa einer Stunde haben wir es auf über 100 Servern ausgerollt und sofort volle Sicht auf unsere Infrastruktur erhalten.

Wir haben das Monitoring für alle unsere Server in nur wenigen Stunden eingerichtet. Das Dashboard ist übersichtlich, leistungsstark und macht wirklich Freude in der Nutzung.

Wir haben Bleemeo in nur wenigen Stunden auf unserer gesamten Server-Infrastruktur ausgerollt. Das Uptime-Monitoring benachrichtigt uns jetzt sofort, wenn ein Dienst ein Problem hat.

Live ansehen
Sehen Sie, wie Teams in unter 5 Minuten von der Installation zum vollständigen Monitoring kommen
UptimeRobot ist ein dediziertes Uptime-Monitoring-Tool — es pingt URLs an und sendet Alarme. Bleemeo ist eine vollständige Monitoring-Plattform, die Uptime-Checks sowie Server-, Container-, Anwendungs- und Log-Monitoring umfasst. Ein einziger Agent deckt externes Uptime, interne Dienste und den Host selbst ab, mit über alle Schichten hinweg korrelierten Metriken.
Ja. Bleemeo unterstützt HTTP-, HTTPS-, TCP-, ICMP-Ping- und SSL-TCP-Monitore von fünf öffentlichen Sonden aus (Frankfurt, Mailand, Paris, Ohio, Singapur), mit konfigurierbaren Intervallen, erwarteten Response-Codes, Body-Matching und benutzerdefinierten Headern. Prüfungen des SSL-Zertifikats und der Domain-Ablaufzeit sind bei jedem HTTPS-Monitor automatisch.
Eine private Sonde ist ein Glouton-Agent, der in Ihrem Netzwerk läuft und Uptime-Checks gegen nur intern erreichbare URLs durchführt — Staging-Umgebungen, Admin-Oberflächen, interne APIs hinter einer VPN. UptimeRobot kann diese Endpoints nicht erreichen, ohne sie öffentlich im Internet freizugeben. Bei Bleemeo wird jeder bereitgestellte Agent automatisch zu einer privaten Sonde, ohne Zusatzkosten.
Ja. Bleemeo veröffentlicht gebrandete öffentliche Statusseiten unter status.bleemeo.com/<slug>/ ohne Authentifizierung. Die Seiten werden von Anwendungen gespeist — Gruppen aus getaggten Diensten und Uptime-Monitoren — sodass ein Klick Ihre bestehenden Monitoring-Daten in eine kundenseitige Verfügbarkeitsansicht verwandelt. In jedem zahlungspflichtigen Plan enthalten, ohne Zusatzmodul.
Ja. Der kostenlose Plan von Bleemeo umfasst Uptime-Monitoring mit 5-Minuten-Intervallen — dieselbe Frequenz wie der kostenlose Tarif von UptimeRobot. Was der kostenlose Plan zusätzlich bietet, ist Server-, Container- und Log-Monitoring im selben Agenten, was UptimeRobot in keinem Tarif anbietet. Wechseln Sie zu Starter oder Professional für Ein-Minuten-Intervalle.
HTTP, HTTPS, TCP, ICMP (Ping) und SSL-TCP — fünf Monitor-Typen. Jeder Monitor unterstützt erwartete HTTP-Statuscodes, Body-Matching (erforderlicher oder verbotener Text), benutzerdefinierte Request-Header und automatische Verfolgung von SSL-Zertifikats- und Domain-Ablaufzeit für HTTPS-Monitore.
Ja. Glouton erkennt über 100 Dienste — Datenbanken, Webserver, Message Queues, Caches — durch Inspektion von Container-Images und Prozesssignaturen. Jeder erkannte Dienst erhält seine spezifischen Metriken und kann zusammen mit seinen Uptime-Monitoren in einer Anwendung gruppiert werden, sodass ein einziger Alarm die ganze Abhängigkeitskette abdeckt statt eines Monitors pro URL.
Ja. Jeder HTTPS-Monitor verfolgt automatisch die SSL-Zertifikats-Ablaufzeit: Ein Warn-Alarm löst 20 Tage vor Ablauf aus, ein kritischer Alarm 10 Tage vor Ablauf. Der Domain-Ablauf wird auf dieselbe Weise über WHOIS verfolgt. Beides ist ohne Zusatzkosten enthalten.
Es gibt keine harte Obergrenze für die Anzahl der Monitore. Der Preis skaliert mit den Agenten (Servern) statt mit der Anzahl der überprüften URLs, also ist das Hinzufügen von Uptime-Checks kostenlos, wenn Sie bereits Agenten für das Server-Monitoring bereitgestellt haben. Private Sonden sind unbegrenzt — fügen Sie eine pro Host hinzu, auf dem Glouton läuft.
Die meisten Teams sind an einem Nachmittag fertig. Exportieren Sie Ihre UptimeRobot-Monitorliste, erstellen Sie entsprechende Monitore in Bleemeo (HTTP/HTTPS/TCP/ICMP/SSL), hängen Sie sie an Anwendungen für die automatische Statusseiten-Gruppierung an, lassen Sie beide Tools eine Woche parallel zur Validierung laufen und wechseln Sie dann. Unser Team unterstützt große Migrationen ohne Zusatzkosten.