

Auf Prometheus und OpenTelemetry aufgebaut
Kein Vendor Lock-in
Metriken in 30 Sekunden senden, mit vollem PromQL abfragen
Bleemeo ist eine hosted Prometheus-Monitoring-Software — eine Managed Prometheus Cloud mit voller PromQL-Kompatibilität, 13 Monate Retention und einem SLA von 99,99 %. Kein Thanos zu betreiben, kein Cortex zu warten, kein Mimir zu skalieren. Nutzen Sie das Prometheus-Tool, das Sie bereits kennen, ohne Storage, Skalierung oder Alerting-Infrastruktur selbst zu betreiben.
15 Tage kostenlos testenKeine Kreditkarte nötigKeine langfristige Bindung
Kein Vendor Lock-in
Daten bleiben in der EU · DSGVO-konform
In Europa und darüber hinaus
Über 500 Unternehmen vertrauen Bleemeo für ihr Infrastruktur-Monitoring
Die Herausforderung
Die lokale Festplatte füllt sich schnell mit hochkardinalitätsreichen Metriken. Externe Lösungen wie Thanos, Cortex oder Mimir fügen erhebliche betriebliche Komplexität hinzu und erfordern dedizierte Ingenieurzeit.
Wenn Ihre Infrastruktur wächst, stoßen einzelne Prometheus-Instanzen an Speicher- und CPU-Grenzen. Federation verteilt die Last, führt aber zu Abfragefragmentierung und Datenlücken.
Das Betreiben zweier identischer Prometheus-Server verschwendet Ressourcen und erfordert dennoch eine externe Deduplizierung. Alertmanager-Clustering fügt eine weitere Infrastrukturebene hinzu, die verwaltet werden muss.
Prometheus erfordert regelmäßige Updates, Speicherverwaltung, Backup-Verfahren und Kapazitätsplanung. Viele Teams verbringen 20-40 Stunden pro Monat allein mit Prometheus-Operationen.
Warum Bleemeo
Eine Managed Prometheus Cloud mit den Zahlen, die zählen — Ihre bestehenden PromQL-Queries, Dashboards und Alert-Regeln funktionieren unverändert.
Richten Sie Glouton auf Ihre /metrics-Endpoints aus, oder pushen Sie via OTLP — fertig. Keine Prometheus-Server bereitzustellen, kein Thanos-Cluster auszurollen, kein Alertmanager zu konfigurieren. Auto-Discovery erkennt 100+ Services out of the box.
Volle Auflösung der Metriken über 13 Monate — kein Downsampling, keine Datenlücken, kein Thanos oder Cortex zu betreiben. Capacity Planning, Post-Mortems, Year-over-Year-Vergleiche — alles bleibt zugänglich, ohne separate Langzeit-Storage-Schicht.
Multi-Zone-Redundanz mit automatischem Failover und 99,99 % Uptime-SLA. Wenn Ihr Cluster degradiert oder Ihre Anwendung abstürzt, ingestet und alertet die Plattform weiter — von außerhalb Ihrer Infrastruktur, damit das kritische Signal Sie tatsächlich erreicht.
Selbstgehostetes Prometheus frisst 20-40 Engineering-Stunden pro Monat: Storage-Wachstum, Versions-Upgrades, Scrape-Config-Drift, Alert-Tuning, Alertmanager-Clustering. Bleemeo gibt diese Zeit Ihrer Plattform- und Produktarbeit zurück.
Was enthalten ist
Hier ist, was mit Bleemeos Managed Prometheus Service mitkommt — kein Sharding, keine Federation, keine Storage-Verwaltung. Ob Sie eine Handvoll Microservices oder Tausende von Containern über mehrere Cluster betreiben, die Plattform skaliert mit Ihnen.
Richten Sie Ihren Glouton-Agent auf Prometheus-Endpunkte oder senden Sie Metriken über OTLP (OpenTelemetry Protocol). Kein Speicher zu provisionieren, keine Aufbewahrungsrichtlinien zu konfigurieren, keine Replikation einzurichten. Metriken fließen innerhalb von Sekunden nach der Konfiguration in die Cloud.
Verarbeiten Sie Millionen von Zeitreihen ohne manuelles Sharding oder Federation. Unsere Multi-Tenant-Architektur verteilt die Last automatisch und skaliert horizontal, wenn Ihr Metrikvolumen wächst.
Multi-Zonen-Redundanz mit automatischem Failover gewährleistet ein SLA von 99,99% Verfügbarkeit. Jeder Datenpunkt wird über mehrere Verfügbarkeitszonen repliziert für Langlebigkeit und schnelle Abfrageleistung. Kein Betrieb doppelter Prometheus-Instanzen oder Verwaltung komplexer Replikationssetups nötig.
13 Monate Metrikdaten in voller Auflösung standardmäßig. Kein Downsampling, keine Datenlücken, keine externen Speicherlösungen wie Thanos oder Cortex erforderlich.
Definieren Sie Alarme mit vertrauten PromQL-Ausdrücken. Integrierte Benachrichtigungskanäle (E-Mail, SMS, Slack, PagerDuty, Webhooks) ersetzen den Bedarf an separater Alertmanager-Infrastruktur.
Vorgefertigte Dashboards füllen sich automatisch, wenn Dienste erkannt werden. Erstellen Sie benutzerdefinierte Dashboards mit PromQL-Abfragen oder verbinden Sie Ihre bestehende Grafana-Installation über unseren Prometheus-kompatiblen API-Endpunkt.
Transparenz
Jeder ausgelöste Alarm und jeder Statuswechsel bleiben für das gesamte Retention-Fenster von 13 Monate erhalten. Erkennen Sie wiederkehrende Vorfälle auf der Heatmap und steigen Sie bis zum genauen Ereignis hinab.
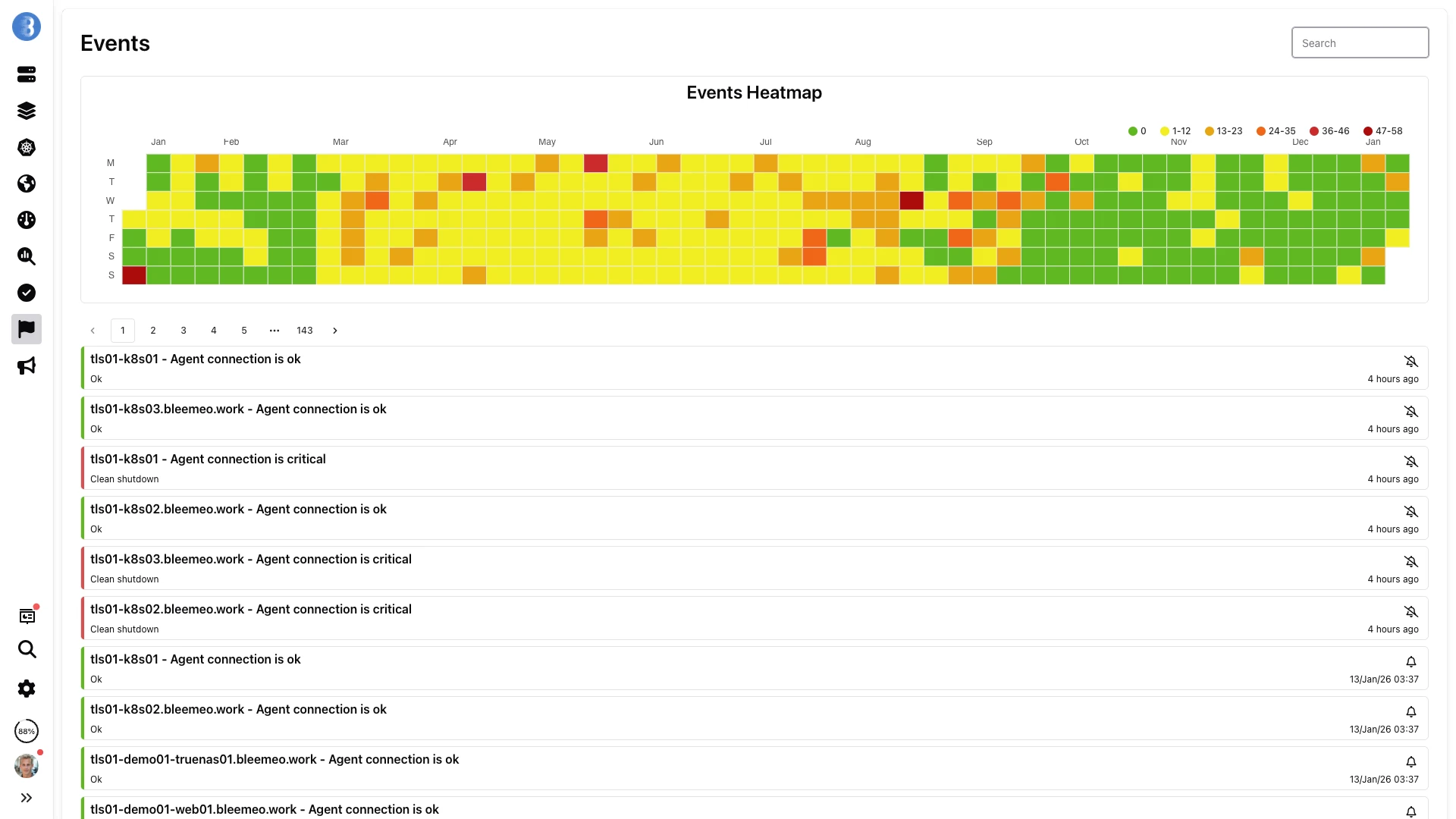
Alarmierung
Definieren Sie eine Recording Rule mit einer reinen PromQL-Abfrage, hängen Sie Low/High Warning und Critical Thresholds an, und Bleemeo macht daraus einen Live-Alarm — ohne Alertmanager-Cluster, ohne YAML-Drift.

Vergleich
| Funktion | Self-Hosted | Bleemeo Prometheus |
|---|---|---|
| Einrichtungszeit | Tage bis Wochen | Minuten |
| Skalierung | Manuelle Konfiguration | Automatisch |
| Hochverfügbarkeit | Komplexes Setup nötig | Eingebaut |
| Langzeit-Storage | Externe Lösung erforderlich | Enthalten |
| Wartung | 20-40 Stunden/Monat | Null |
| Monatliche Gesamtkosten | 5.000-10.000 $ | 500-3.000 $ |
| Daten-Retention | 15 Tage (Standard) | 13 Monate |
On-Premise oder in der Cloud — Bleemeo überwacht die Kubernetes-Cluster meiner Kunden ganz ohne Komplexität. Ein Tool, das ich für seine Einfachheit und die gebotene Übersichtlichkeit empfehle.

In Aktion
/metrics zum DashboardGlouton scrapt Ihre Prometheus-Endpoints und die PromQL-Dashboards von Bleemeo füllen sich — unten festgehalten.

Vom Scrape zum Dashboard — in unter einer Minute, ohne Konfiguration.
Architektur
Lassen Sie Ihre eigenen Metriken durch diesen Flow laufen — dieselben 30 Sekunden, dieselbe Managed Prometheus Cloud.
Erste Schritte
Fügen Sie die Metrik-Ziele zu Ihrer Glouton-Konfiguration hinzu. Glouton fragt Ihre Prometheus-Endpunkte ab und leitet die Metriken an Bleemeo weiter. Sie können auch Metriken über OTLP (OpenTelemetry Protocol) senden, wenn Ihr Team bereits OpenTelemetry-Instrumentierung verwendet.
metric:
prometheus:
targets:
- url: http://localhost:9090/metricsIhre Metriken fließen automatisch zu Bleemeo. Unsere Plattform führt eine automatische Diensterkennung durch und füllt vorgefertigte Dashboards für erkannte Dienste wie PostgreSQL, Redis, NGINX und viele mehr. Greifen Sie auf Ihre Daten über das Bleemeo-Dashboard zu oder verbinden Sie Ihre bestehende Grafana-Installation über unseren Prometheus-kompatiblen API-Endpunkt als Datenquelle.
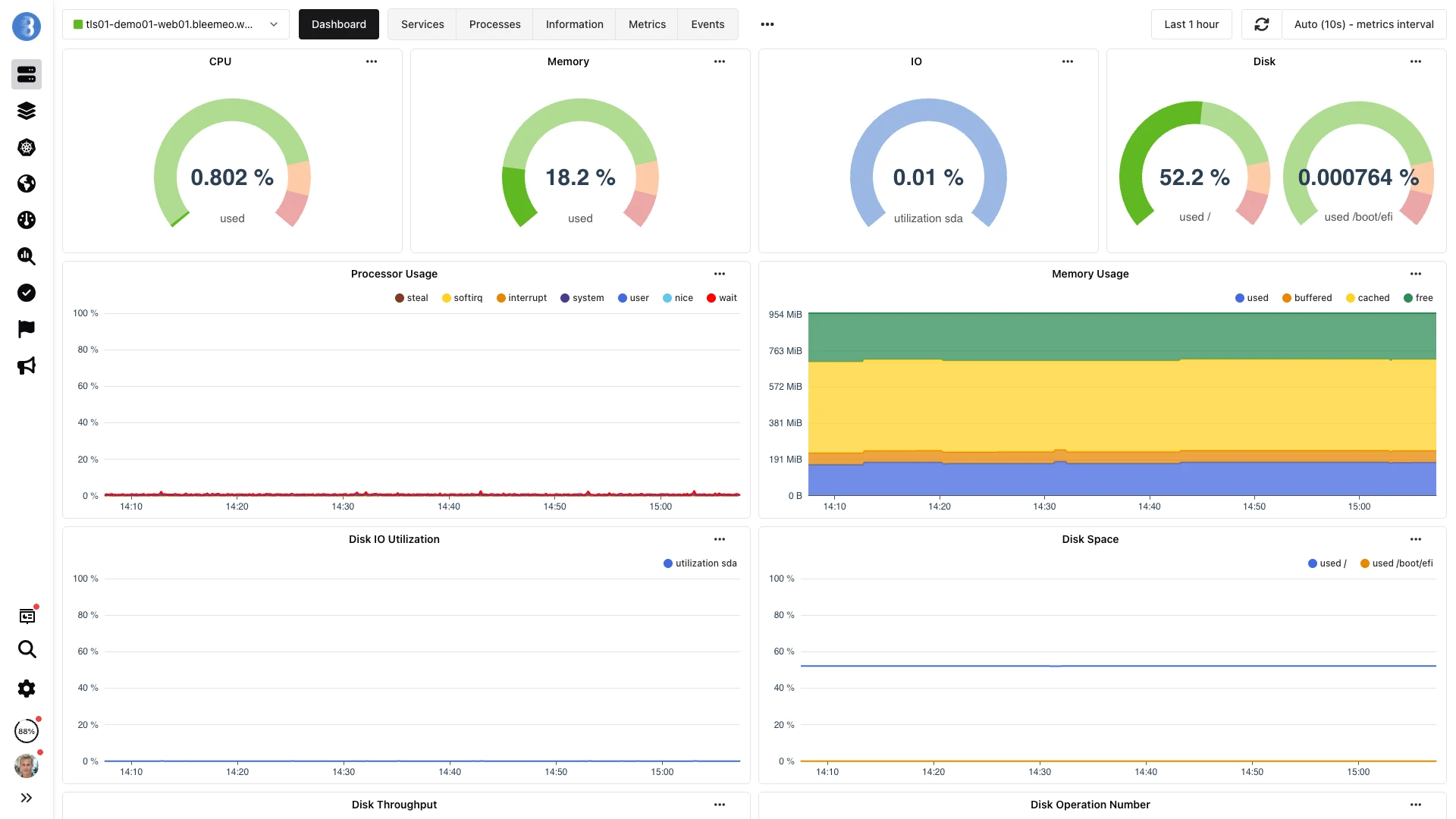
Konfigurieren Sie Alarme über unsere intuitive Oberfläche oder importieren Sie bestehende Prometheus-Alarmregeln. Definieren Sie PromQL-basierte Alarmregeln für präzise Bedingungen, erstellen Sie Recording Rules für abgeleitete Metriken und häufig verwendete Aggregationen, und wählen Sie aus über 15 Benachrichtigungskanal-Integrationen einschließlich E-Mail, SMS, Slack, PagerDuty, Microsoft Teams und Webhooks.
Migration
Kein Big-Bang-Wechsel. Drei inkrementelle Schritte parallel zu Ihrem bestehenden Stack.
Setzen Sie den Glouton-Agent ein, um dieselben Prometheus-Endpoints zu scrapen, die Ihr aktueller Server überwacht, und halten Sie Ihren lokalen Storage aktiv. Validieren Sie, dass jede Metrik korrekt in Bleemeo erscheint, bevor Sie etwas außer Betrieb nehmen.
Bleemeo stellt eine Prometheus-kompatible API bereit, die als Standard-Grafana-Datenquelle funktioniert. Fügen Sie Bleemeo als zweite Datenquelle hinzu, vergleichen Sie Dashboards nebeneinander und schalten Sie dann den Default um — Panel-Layouts und Variablen-Vorlagen bleiben gleich.
Das integrierte Alerting von Bleemeo ersetzt Alertmanager vollständig. Ihre bestehenden PromQL-Alert-Ausdrücke funktionieren unverändert; konfigurieren Sie E-Mail-, SMS-, Slack-, PagerDuty- oder Webhook-Kanäle über die Plattform und mustern Sie den Alertmanager-Cluster aus.
Anwendungsfälle
Überwachen Sie Kubernetes-Cluster, Microservices und Container mit automatischer Diensterkennung. Glouton wird als DaemonSet bereitgestellt und erkennt automatisch alle laufenden Dienste auf jedem Knoten.
Starten Sie mit 5 Servern und skalieren Sie auf 5.000, ohne die Architektur zu ändern. Keine Kapazitätsplanung, keine Speicherverwaltung, keine Federation-Komplexität. Bezahlen Sie nur, was Sie nutzen.
Erfüllen Sie SOC 2-Anforderungen mit verschlüsselten Daten in europäischen Rechenzentren. Die 13-monatige Aufbewahrung erfüllt die meisten Compliance-Frameworks ohne zusätzliche Speicherinfrastruktur. Rollenbasierte Zugriffskontrolle und SSO-Integration stellen sicher, dass nur autorisierte Teammitglieder auf Ihre Metriken zugreifen.
Eliminieren Sie 20-40 Stunden/Monat an Prometheus-Operationen. Setzen Sie Ingenieurzeit für die Feature-Entwicklung ein, anstatt die Monitoring-Infrastruktur zu verwalten. Kein Upgrade von Prometheus-Versionen, keine Größenänderung von Speichervolumes, kein Debugging von Abfrage-Timeouts mehr — überlassen Sie alles Bleemeo.
Ressourcen
Ein Primer zu Prometheus-Metriken, PromQL, Namenskonventionen und Cardinality — nützlicher Kontext, während Sie das hosted Prometheus von Bleemeo evaluieren.
Prometheus identifiziert jede Metrik durch einen Namen plus Schlüssel-Wert-Labels. Das Modell erleichtert das Aufschlüsseln, Filtern und Aggregieren über jede Dimension. Beispielsweise erfasst http_requests_total{method="GET", endpoint="/api/users", status="200"} GET-Anfragen an /api/users, die einen 200-Status zurückgegeben haben — und dieselbe Metrik unterstützt Abfragen nach Methode, Endpoint, Statuscode oder beliebiger Kombination, ohne die Definition zu duplizieren.
Prometheus definiert vier grundlegende Typen. Ein Counter ist ein monoton steigender Wert — Anfragezähler, übertragene Bytes. Ein Gauge steigt oder fällt — CPU-Auslastung, aktive Verbindungen. Ein Histogram ordnet Beobachtungen in Buckets für Latenz- oder Größenverteilungen. Ein Summary berechnet Streaming-Quantile (p95, p99) für Echtzeit-SLA-Tracking. Den richtigen Typ pro Messung zu wählen ist das, was Dashboards und Alerts genau hält.
Metriknamen sollten Kleinbuchstaben mit Unterstrichen sein und auf einen Einheitssuffix wie _seconds, _bytes oder _total (für Counter) enden. Beispielsweise zeigt http_request_duration_seconds sofort, was gemessen wird. Bleemeo bewahrt diese Konventionen und akzeptiert Standard-Prometheus-Metriknamen unverändert — die Migration bestehender Metriken erfordert keine Umbenennung.
PromQL (Prometheus Query Language) schlüsselt Zeitreihen in Echtzeit auf und aggregiert sie — Raten, Durchschnitte, Perzentile, komplexe Aggregationen über Tausende von Serien in einem einzigen Ausdruck. Bleemeo unterstützt PromQL vollständig für Dashboards, Alert-Regeln, Recording Rules und Ad-hoc-Abfragen, sodass Ihre bestehenden Definitionen ohne Änderung migrieren.
Cardinality ist die Anzahl eindeutiger Label-Wert-Kombinationen pro Metrik. Hohe Cardinality — Benutzer-IDs, Session-Tokens, eindeutige Request-IDs in Labels — lässt Prometheus übermäßig Speicher verbrauchen und verschlechtert die Abfrageleistung. Als Best Practice halten Sie die Cardinality auf hunderten oder höchstens einigen tausend Werten pro Metrik. Bleemeos Managed-Architektur bewältigt höhere Cardinality eleganter als selbst gehostetes Prometheus, aber die Einhaltung dieser Best Practices hält Abfragen schnell und Kosten vorhersehbar.
Möchten Sie mehr erfahren? Lernen Sie, wie Sie Prometheus-Abfragen konfigurieren, PromQL-Abfragen schreiben und Grafana mit Ihren Bleemeo-Metriken verbinden.
Dokumentation lesenAlles, was Sie über den verwalteten Prometheus-Dienst von Bleemeo wissen müssen
Sie können Metriken auf zwei Wegen an Bleemeo senden: Der Glouton-Agent kann Prometheus-Endpunkte lokal abfragen und die Metriken in die Cloud weiterleiten, oder Sie können Metriken über OTLP (OpenTelemetry Protocol) senden. Glouton ist der empfohlene Ansatz, da er Infrastrukturkontext hinzufügt und minimale Konfiguration erfordert.
Ja, Bleemeo unterstützt PromQL (Prometheus Query Language) vollständig. Sie können PromQL für benutzerdefinierte Dashboard-Widgets, Alarmierungsbedingungen und Ad-hoc-Abfragen verwenden. Das bedeutet, dass Sie bestehende Prometheus-Dashboards und Alarmregeln mit minimalen Änderungen migrieren können. Unsere Dokumentation bietet Beispiele und Best Practices für die Verwendung von PromQL in Bleemeo.
Ja, Bleemeo bietet einen Prometheus-kompatiblen API-Endpunkt, der als Grafana-Datenquelle funktioniert. Sie können Ihre bestehende Grafana-Installation mit Bleemeo verbinden und Ihre vorhandenen Dashboards nutzen. Dies ermöglicht Teams, vertraute Tools weiterhin zu verwenden und gleichzeitig von Bleemeos verwalteter Speicherung und Skalierbarkeit zu profitieren.
Bleemeo bewahrt Metriken standardmäßig 13 Monate auf, im Vergleich zur typischen 15-tägigen lokalen Aufbewahrung von Prometheus. Diese Langzeitspeicherung ermöglicht Jahresvergleiche, Kapazitätsplanung und die Erfüllung von Compliance-Anforderungen. Die gesamte Aufbewahrung erfolgt automatisch — keine Konfiguration externer Speicherlösungen wie Thanos oder Cortex erforderlich.
Selbst gehostetes Prometheus im großen Maßstab kostet typischerweise $5.000-10.000/Monat einschließlich Infrastruktur, Speicherlösungen und 20-40 Stunden Ingenieurzeit. Der verwaltete Dienst von Bleemeo kostet $500-3.000/Monat ohne betrieblichen Aufwand. Nutzen Sie unseren Rechner, um die Kosten für Ihren spezifischen Anwendungsfall zu vergleichen. Die Einsparungen wachsen mit der Skalierung dank unserer effizienten Multi-Tenant-Architektur.
Nein. Bleemeo ist die Managed Prometheus Cloud, die Thanos, Cortex und Mimir vollständig ersetzt. Langzeit-Storage, horizontale Skalierung, Deduplikation und Cluster-übergreifende Queries sind alle in die Plattform integriert. Sie richten Glouton (oder OTLP) auf Ihre /metrics-Endpoints aus und hören auf, Storage-Backends, Querier, Compactor oder Store-Gateways zu betreiben. Retention von 13 Monate out of the box mit 99,99 % SLA.
Bleemeo bietet integrierte Hochverfügbarkeit mit Multi-Zonen-Redundanz und automatischem Failover. Wir erreichen ein SLA von 99,99% Verfügbarkeit. Dies ist im Standarddienst enthalten — kein Konfigurieren mehrerer Prometheus-Instanzen, kein Einrichten der Replikation, kein manuelles Verwalten des Failovers. Ihre Metriken sind immer verfügbar, wenn Sie sie brauchen.
Ja, die Migration ist unkompliziert. Sie können Bleemeo parallel zu Ihrem bestehenden Prometheus während der Übergangsphase betreiben. Setzen Sie den Glouton-Agent ein, um dieselben Prometheus-Endpunkte abzufragen, validieren Sie die Daten in Bleemeo und deaktivieren Sie dann Ihre selbst gehostete Installation. Alarmregeln können dank PromQL-Kompatibilität migriert werden. Wir bieten Migrationsanleitungen und Support für Enterprise-Kunden.
Bleemeos Architektur verarbeitet Millionen von Zeitreihen ohne manuelles Eingreifen. Wenn Ihr Metrikvolumen wächst, skaliert unsere Infrastruktur automatisch. Sie müssen keine Instanzen vergrößern, kein Sharding konfigurieren oder Federation einrichten. Dies geschieht transparent — Sie senden einfach Metriken, und wir stellen sicher, dass sie gespeichert und abfragbar sind, unabhängig vom Volumen.
Bleemeo enthält ein vollständiges Alarmierungssystem, das mit Prometheus-Alarmregeln kompatibel ist. Sie können Alarme mit PromQL-Bedingungen definieren, mehrere Benachrichtigungskanäle (E-Mail, SMS, Slack, PagerDuty, Webhooks) konfigurieren, Eskalationsrichtlinien einrichten und Funktionen wie Gruppierung und Wartungsfenster nutzen. Dies ersetzt den Bedarf an separater Alertmanager-Infrastruktur.
Ja, Sicherheit hat Priorität. Alle Daten werden bei der Übertragung (TLS) und im Ruhezustand verschlüsselt. Bleemeo wird in europäischen Rechenzentren mit SOC 2-Konformität gehostet. Die Daten jedes Kunden sind isoliert. Wir unterstützen SSO-Integration und rollenbasierte Zugriffskontrolle. Besuchen Sie unsere Sicherheitsseite für detaillierte Informationen über unsere Sicherheitspraktiken und Zertifizierungen.
Etwa 30 Sekunden tatsächliche Konfiguration. Richten Sie den Glouton-Agent auf Ihre bestehenden /metrics-Endpoints aus (oder pushen Sie via OTLP), geben Sie Ihre Account-Credentials an, und Metriken erreichen Bleemeo innerhalb von Sekunden. Auto-Discovery erkennt 100+ Services ohne manuelle Konfiguration; vorgefertigte Dashboards und PromQL-Alerting funktionieren out of the box. Keine Prometheus-Server zu provisionieren, kein Storage zu dimensionieren, kein Alertmanager zu clustern.