

Construido sobre Prometheus y OpenTelemetry
Sin dependencia del proveedor
Envía métricas en 30 segundos, consulta con todo PromQL
Bleemeo es un software de monitoreo Prometheus hospedado — un Prometheus cloud gestionado con compatibilidad PromQL completa, 13 meses de retención y un SLA del 99,99 %. Sin Thanos que operar, sin Cortex que mantener, sin Mimir que escalar. Usa la herramienta Prometheus que ya conoces, sin gestionar tú mismo el almacenamiento, el escalado o la infraestructura de alertas.
Prueba gratuita 15 díasSin tarjeta de créditoSin compromiso a largo plazo
Sin dependencia del proveedor
Datos almacenados en la UE · Cumple con el RGPD
En toda Europa y más allá
Más de 500 empresas confían en Bleemeo para monitorear su infraestructura
El desafío
El disco local se llena rápidamente con métricas de alta cardinalidad. Las soluciones externas como Thanos, Cortex o Mimir añaden una complejidad operativa significativa y requieren tiempo de ingeniería dedicado.
A medida que tu infraestructura crece, las instancias individuales de Prometheus alcanzan los límites de memoria y CPU. La federación distribuye la carga pero introduce fragmentación de consultas y lagunas de datos.
Ejecutar dos servidores Prometheus idénticos desperdicia recursos y aún requiere deduplicación externa. El clustering de Alertmanager añade otra capa de infraestructura que gestionar.
Prometheus necesita actualizaciones regulares, gestión de almacenamiento, procedimientos de backup y planificación de capacidad. Muchos equipos dedican 20-40 horas al mes solo en operaciones de Prometheus.
Por qué Bleemeo
Un Prometheus cloud gestionado con los números que importan — tus consultas PromQL, dashboards y reglas de alerta existentes funcionan sin modificación.
Apunta Glouton a tus endpoints /metrics, o envía vía OTLP — listo. Ningún servidor Prometheus que aprovisionar, ningún clúster Thanos que desplegar, ningún Alertmanager que configurar. El descubrimiento automático reconoce más de 100 servicios de fábrica.
Métricas en resolución completa conservadas durante 13 meses — sin downsampling, sin huecos de datos, sin Thanos ni Cortex que operar. Planificación de capacidad, post-mortems, comparaciones interanuales — todo accesible sin un nivel separado de almacenamiento a largo plazo.
Redundancia multi-zona con failover automático y SLA de uptime del 99,99 %. Cuando tu clúster se degrada o tu aplicación falla, la plataforma sigue ingiriendo y alertando desde fuera de tu infraestructura — para que la señal crítica que necesitas te llegue de verdad.
Un Prometheus auto-hospedado consume 20-40 horas-ingeniero al mes: crecimiento del almacenamiento, upgrades de versión, scrape configs que derivan, ajuste de reglas de alerta, clustering de Alertmanager. Bleemeo devuelve ese tiempo a tu trabajo de plataforma y producto.
Lo que incluye
Esto es lo que viene con el servicio Prometheus gestionado de Bleemeo — sin sharding, sin federación, sin gestión del almacenamiento. Ya ejecutes un puñado de microservicios o miles de contenedores en múltiples clústeres, la plataforma escala contigo.
Apunta tu agente Glouton a los endpoints Prometheus o envía métricas via OTLP (OpenTelemetry Protocol). Sin necesidad de aprovisionar almacenamiento, configurar políticas de retención ni establecer replicación. Las métricas fluyen a la nube en segundos tras la configuración.
Gestiona millones de series temporales sin sharding manual ni federación. Nuestra arquitectura multi-tenant distribuye la carga automáticamente y escala horizontalmente a medida que crece tu volumen de métricas.
Redundancia multi-zona con failover automático que garantiza un SLA de 99.99% de uptime. Cada punto de datos se replica en múltiples zonas de disponibilidad para durabilidad y rendimiento rápido de consultas. Sin necesidad de ejecutar instancias Prometheus duplicadas ni gestionar configuraciones de replicación complejas.
13 meses de datos de métricas en resolución completa por defecto. Sin downsampling, sin lagunas de datos, sin necesidad de soluciones de almacenamiento externo como Thanos o Cortex.
Define alertas usando expresiones PromQL familiares. Canales de notificación integrados (email, SMS, Slack, PagerDuty, webhooks) que reemplazan la necesidad de una infraestructura separada de Alertmanager.
Dashboards preconstruidos que se rellenan automáticamente cuando se detectan servicios. Crea dashboards personalizados con consultas PromQL o conecta tu instalación existente de Grafana a través de nuestro endpoint de API compatible con Prometheus.
Visibilidad
Cada alerta disparada y cada cambio de estado se conservan durante toda la ventana de retención de 13 meses. Detecta incidentes recurrentes en el heatmap y profundiza hasta el evento exacto.
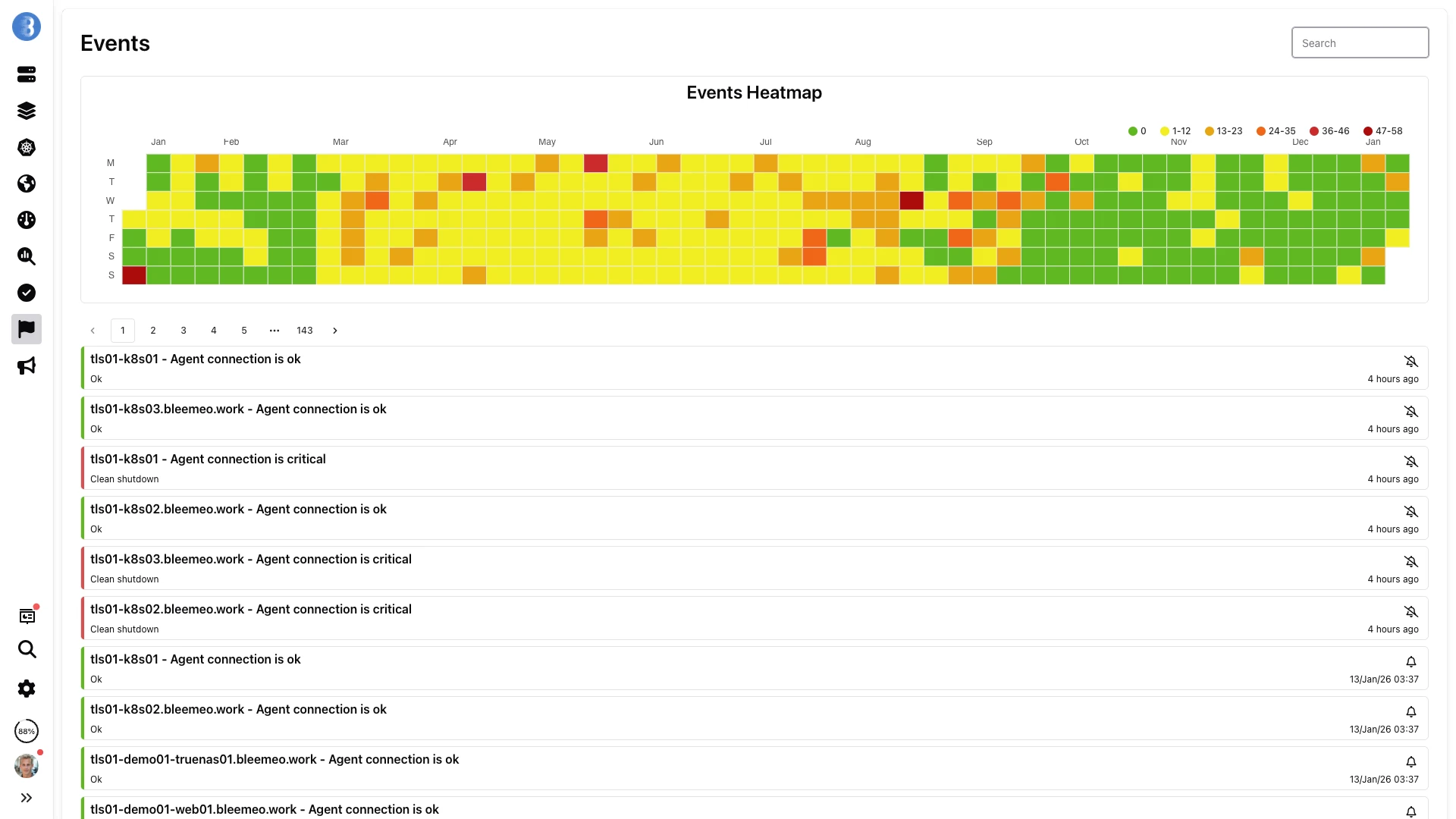
Alertas
Define una recording rule con una consulta PromQL en bruto, adjunta umbrales Low/High Warning y Critical, y Bleemeo la convierte en una alerta viva — sin cluster Alertmanager, sin deriva de YAML.

Comparativa
| Característica | Auto-alojado | Bleemeo Prometheus |
|---|---|---|
| Tiempo de Configuración | Días a semanas | Minutos |
| Escalado | Configuración manual | Automático |
| Alta Disponibilidad | Configuración compleja requerida | Integrada |
| Almacenamiento a Largo Plazo | Requiere solución externa | Incluido |
| Mantenimiento | 20-40 horas/mes | Cero |
| Coste Mensual Total | $5.000-10.000 | $500-3.000 |
| Retención de Datos | 15 días (por defecto) | 13 meses |
On-premise o en la nube, Bleemeo supervisa los clústeres Kubernetes de mis clientes sin complejidad. Una herramienta que recomiendo por su simplicidad y la claridad que aporta.

En acción
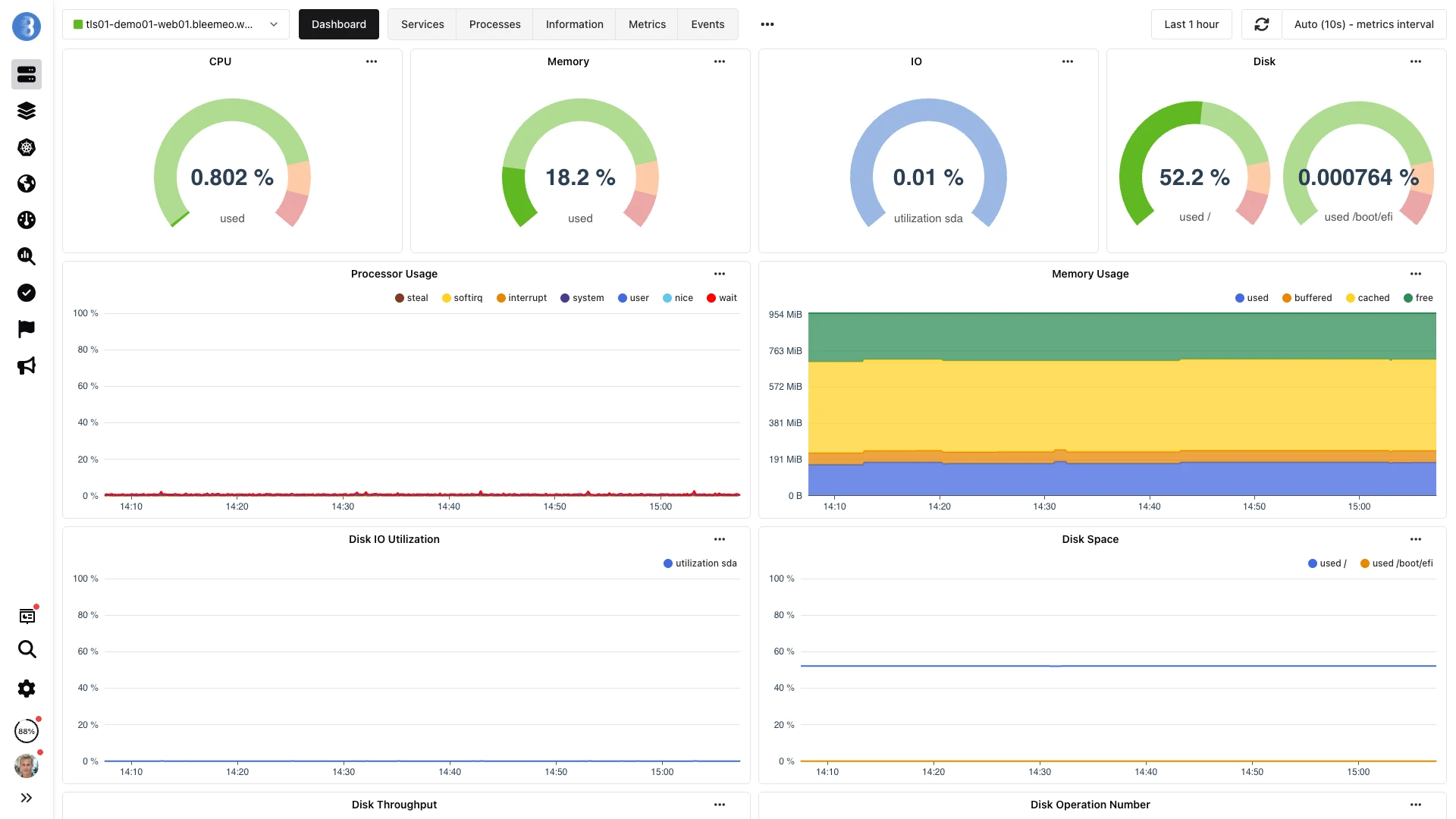
/metrics al dashboardGlouton recopila tus endpoints Prometheus y los dashboards PromQL de Bleemeo se llenan — capturado abajo.

De la recopilación al dashboard — en menos de un minuto, sin configuración.
Arquitectura
Haz pasar tus propias métricas por este flujo — los mismos 30 segundos, el mismo Prometheus cloud gestionado.
Primeros pasos
Añade los objetivos de métricas a tu configuración de Glouton. Glouton recopila tus endpoints Prometheus y reenvía las métricas a Bleemeo. También puedes enviar métricas via OTLP (OpenTelemetry Protocol) para equipos que ya usan instrumentación OpenTelemetry.
metric:
prometheus:
targets:
- url: http://localhost:9090/metricsTus métricas fluyen automáticamente a Bleemeo. Nuestra plataforma realiza descubrimiento automático de servicios y rellena dashboards preconstruidos para servicios detectados como PostgreSQL, Redis, NGINX y muchos más. Accede a tus datos a través del dashboard de Bleemeo o conecta tu instalación existente de Grafana usando nuestro endpoint de API compatible con Prometheus como fuente de datos.
Configura alertas usando nuestra interfaz intuitiva o importa reglas de alerta existentes de Prometheus. Define reglas de alerta basadas en PromQL para condiciones precisas, crea recording rules para métricas derivadas y agregaciones frecuentes, y elige entre más de 15 integraciones de canales de notificación incluyendo email, SMS, Slack, PagerDuty, Microsoft Teams y webhooks.
Migración
Sin cambio big-bang. Tres pasos incrementales en paralelo con tu stack actual.
Despliega el agente Glouton para recopilar los mismos endpoints Prometheus que tu servidor actual monitorea, manteniendo activo tu almacenamiento local. Valida que cada métrica aparezca correctamente en Bleemeo antes de descomisionar nada.
Bleemeo expone una API compatible con Prometheus que funciona como fuente de datos Grafana estándar. Añade Bleemeo como segunda fuente, compara dashboards lado a lado, luego cambia el predeterminado — los diseños de paneles y plantillas de variables se mantienen iguales.
El alerting integrado de Bleemeo reemplaza Alertmanager por completo. Tus expresiones de alerta PromQL funcionan sin modificación; configura canales de email, SMS, Slack, PagerDuty o webhook desde la plataforma y retira el clúster Alertmanager.
Casos de uso
Monitorea clústeres Kubernetes, microservicios y contenedores con descubrimiento automático de servicios. Glouton se despliega como DaemonSet y detecta automáticamente todos los servicios en ejecución en cada nodo.
Comienza con 5 servidores y escala a 5,000 sin rediseñar la arquitectura. Sin planificación de capacidad, sin gestión de almacenamiento, sin complejidad de federación. Paga solo por lo que usas.
Cumple los requisitos SOC 2 con datos cifrados en centros de datos europeos. La retención de 13 meses satisface la mayoría de los marcos de cumplimiento sin infraestructura de almacenamiento adicional. El control de acceso basado en roles y la integración SSO aseguran que solo los miembros autorizados del equipo accedan a tus métricas.
Elimina 20-40 horas/mes de operaciones de Prometheus. Dedica el tiempo de ingeniería al desarrollo de funcionalidades en lugar de gestionar la infraestructura de monitoreo. No más actualizar versiones de Prometheus, redimensionar volúmenes de almacenamiento ni depurar timeouts de consultas — deja que Bleemeo se encargue de todo.
Recursos
Primer sobre métricas Prometheus, PromQL, convenciones de nombrado y cardinalidad — un contexto útil mientras evalúas el Prometheus hospedado de Bleemeo.
Prometheus identifica cada métrica por un nombre y un conjunto de labels clave-valor. El modelo facilita segmentar, filtrar y agregar según cualquier dimensión. Por ejemplo, http_requests_total{method="GET", endpoint="/api/users", status="200"} captura las solicitudes GET a /api/users que devolvieron un 200 — y la misma métrica soporta consultas por método, endpoint, código de estado o cualquier combinación, sin duplicar la definición.
Prometheus define cuatro tipos fundamentales. Un Counter es un valor monotónicamente creciente — recuentos de solicitudes, bytes transferidos. Un Gauge sube o baja — uso de CPU, conexiones activas. Un Histogram reparte observaciones en buckets para distribuciones de latencia o tamaño. Un Summary calcula cuantiles en streaming (p95, p99) para seguimiento de SLA en tiempo real. Elegir el tipo correcto por medición es lo que mantiene dashboards y alertas precisos.
Los nombres de métricas deben estar en minúsculas con guiones bajos y terminar en un sufijo de unidad como _seconds, _bytes o _total (para counters). Por ejemplo, http_request_duration_seconds indica al instante qué se mide. Bleemeo preserva estas convenciones y acepta los nombres de métricas Prometheus estándar tal cual — migrar métricas existentes no requiere renombrar nada.
PromQL (Prometheus Query Language) segmenta y agrega series temporales en tiempo real — tasas, promedios, percentiles, agregaciones complejas sobre miles de series en una sola expresión. Bleemeo soporta completamente PromQL para dashboards, reglas de alerta, recording rules y consultas ad-hoc, de modo que tus definiciones existentes migran sin modificación.
La cardinalidad es el número de combinaciones únicas de valores de labels por métrica. Una cardinalidad alta — IDs de usuario, tokens de sesión, IDs de solicitud únicos en labels — hace que Prometheus consuma memoria excesiva y degrada el rendimiento de las consultas. Como buena práctica, mantén la cardinalidad en cientos o como máximo unos pocos miles de valores por métrica. La arquitectura gestionada de Bleemeo maneja mayor cardinalidad con más elegancia que un Prometheus auto-alojado, pero seguir estas buenas prácticas mantiene las consultas rápidas y los costes predecibles.
¿Quieres ir más allá? Aprende a configurar la recopilación de Prometheus, escribir consultas PromQL y conectar Grafana a tus métricas de Bleemeo.
Leer la DocumentaciónTodo lo que necesitas saber sobre el servicio gestionado de Prometheus de Bleemeo
Puedes enviar métricas a Bleemeo de dos formas: el agente Glouton puede recopilar endpoints Prometheus localmente y reenviar las métricas a la nube, o puedes enviar métricas via OTLP (OpenTelemetry Protocol). Glouton es el enfoque recomendado ya que añade contexto de infraestructura y requiere una configuración mínima.
Sí, Bleemeo soporta completamente PromQL (Prometheus Query Language). Puedes usar PromQL para widgets de dashboards personalizados, condiciones de alertas y consultas ad-hoc. Esto significa que puedes migrar dashboards y reglas de alerta existentes de Prometheus con cambios mínimos. Nuestra documentación proporciona ejemplos y buenas prácticas para el uso de PromQL en Bleemeo.
Sí, Bleemeo proporciona un endpoint de API compatible con Prometheus que funciona como fuente de datos de Grafana. Puedes conectar tu instalación existente de Grafana a Bleemeo y usar tus dashboards existentes. Esto permite a los equipos seguir usando herramientas familiares mientras se benefician del almacenamiento gestionado y la escalabilidad de Bleemeo.
Bleemeo retiene las métricas durante 13 meses por defecto, en comparación con la retención local típica de 15 días de Prometheus. Este almacenamiento a largo plazo permite comparaciones interanuales, planificación de capacidad y requisitos de cumplimiento. Toda la retención es automática — sin necesidad de configurar soluciones de almacenamiento externo como Thanos o Cortex.
Prometheus auto-alojado a escala típicamente cuesta $5,000-10,000/mes incluyendo infraestructura, soluciones de almacenamiento y 20-40 horas de tiempo de ingeniería. El servicio gestionado de Bleemeo cuesta $500-3,000/mes con cero carga operativa. Usa nuestra calculadora para comparar costos para tu caso de uso específico. Los ahorros aumentan con la escala gracias a nuestra eficiente arquitectura multi-tenant.
No. Bleemeo es el Prometheus cloud gestionado que reemplaza Thanos, Cortex y Mimir por completo. El almacenamiento a largo plazo, el escalado horizontal, la deduplicación y las consultas inter-clúster están todos integrados en la plataforma. Apuntas Glouton (u OTLP) a tus endpoints /metrics y dejas de gestionar storage backends, queriers, compactors o store gateways. Retención de 13 meses de fábrica con un SLA de 99,99 %.
Bleemeo proporciona alta disponibilidad integrada con redundancia multi-zona y failover automático. Alcanzamos un SLA de 99.99% de uptime. Esto está incluido en el servicio estándar — sin necesidad de configurar múltiples instancias de Prometheus, establecer replicación ni gestionar el failover manualmente. Tus métricas siempre están disponibles cuando las necesitas.
Sí, la migración es sencilla. Puedes ejecutar Bleemeo junto a tu Prometheus existente durante la transición. Despliega el agente Glouton para recopilar los mismos endpoints Prometheus, valida los datos en Bleemeo y luego descomisiona tu infraestructura auto-alojada. Las reglas de alerta pueden migrarse gracias a la compatibilidad con PromQL. Proporcionamos guías de migración y soporte para clientes empresariales.
La arquitectura de Bleemeo gestiona millones de series temporales sin intervención manual. A medida que crece tu volumen de métricas, nuestra infraestructura escala automáticamente. No necesitas redimensionar instancias, configurar sharding ni establecer federación. Esto se gestiona de forma transparente — simplemente envías métricas y nosotros nos aseguramos de que se almacenen y sean consultables independientemente del volumen.
Bleemeo incluye un sistema de alertas completo compatible con las reglas de alerta de Prometheus. Puedes definir alertas usando condiciones PromQL, configurar múltiples canales de notificación (email, SMS, Slack, PagerDuty, webhooks), establecer políticas de escalado y usar funcionalidades como agrupación y ventanas de mantenimiento. Esto reemplaza la necesidad de una infraestructura separada de Alertmanager.
Sí, la seguridad es una prioridad. Todos los datos están cifrados en tránsito (TLS) y en reposo. Bleemeo está alojado en centros de datos europeos con cumplimiento SOC 2. Los datos de cada cliente están aislados. Soportamos integración SSO y control de acceso basado en roles. Consulta nuestra página de seguridad para información detallada sobre nuestras prácticas y certificaciones de seguridad.
Unos 30 segundos de configuración real. Apunta el agente Glouton a tus endpoints /metrics existentes (o envía vía OTLP), proporciona tus credenciales de cuenta y las métricas empiezan a llegar a Bleemeo en segundos. El descubrimiento automático reconoce más de 100 servicios sin configuración manual; dashboards y alertas PromQL funcionan de fábrica. Ningún servidor Prometheus que aprovisionar, ningún almacenamiento que dimensionar, ningún Alertmanager que clusterizar.