

Construido sobre Prometheus y OpenTelemetry
Sin dependencia del proveedor
Monitoreo de Clústeres Kubernetes para Nodos, Pods y Contenedores
Un chart de Helm, ningún Prometheus que operar, ningún Grafana que mantener, ningún almacenamiento que gestionar. Bleemeo te da visibilidad completa sobre clúster, nodos, pods y contenedores — con alertas que funcionan desde el primer día.
Prueba gratuita 15 díasSin tarjeta de créditoSin compromiso a largo plazo
Sin dependencia del proveedor
Datos almacenados en la UE · Cumple con el RGPD
En toda Europa y más allá
Más de 500 empresas confían en Bleemeo para monitorear su infraestructura
El problema
Construir el monitoreo Kubernetes internamente con el ecosistema open source parece gratis — hasta que cuentas el tiempo de ingeniería. Cuatro costes que solo aparecen después del despliegue:
Prometheus, Grafana, Alertmanager, exporters, un backend de almacenamiento — cada pieza es a su vez una aplicación Kubernetes que desplegar, actualizar, asegurar y parchear. La pila de monitoreo que montaste para mantener tu plataforma sana acaba siendo una de sus principales fuentes de incidentes.
Las etiquetas de los pods se convierten en explosiones de cardinalidad. Las instancias únicas de Prometheus se quedan sin RAM y sin disco a medida que el clúster crece. Ir más lejos significa comprometerse con Thanos, Cortex o Mimir — otro sistema distribuido con su propio object storage, queriers, compactors y store gateways que operar.
Las reglas de alerta Kubernetes listas para usar cubren lo básico, pero afinarlas a tus cargas de trabajo — eliminar falsos positivos en los rolling updates, deduplicar el ruido entre réplicas, ajustar el on-call — lleva meses de iteración. La mayoría de equipos opera con alertas en las que no pueden confiar plenamente.
Cuando tu pila de monitoreo vive dentro del clúster que se supone debe vigilar, un incidente del control plane se lleva las alertas con él. Suma el tiempo recurrente dedicado a mantener Prometheus, Grafana y el almacenamiento, y tu equipo DevOps termina monitoreando su propio monitoreo en lugar del producto.
Por qué Bleemeo
Monitoreo de clúster Kubernetes de nivel producción, entregado como servicio gestionado. Ninguna plataforma que operar, ningún almacenamiento que escalar, ninguna pila de alertas que cuidar.
Un helm upgrade --install, un DaemonSet, tres variables de entorno — listo. Ningún PVC que aprovisionar, ningún scrape config que escribir, ningún dashboard que importar, ninguna regla de alerta que escribir. El descubrimiento automático reconoce más de 100 servicios sin configuración.
Métricas de alta resolución conservadas durante 13 meses sin desplegar Thanos, Cortex o Mimir. Planificación de capacidad, post-mortems, tendencias estacionales — todo accesible sin un nivel separado de almacenamiento a largo plazo.
Bleemeo se ejecuta fuera de tu clúster, en una plataforma totalmente gestionada con un SLA de uptime del 99,99 %. Cuando etcd colapsa o los nodos pasan a NotReady, las alertas siguen llegándote. El único sistema de monitoreo que no puedes derribar con tus propios incidentes.
Un monitoreo Kubernetes auto-hospedado consume 20-40 horas-ingeniero al mes: crecimiento del almacenamiento, reinicios de Prometheus, scrape configs que derivan, ajuste de alertas, actualizaciones de Grafana. Bleemeo devuelve ese tiempo a tu trabajo de plataforma y producto.
Bleemeo no es un reemplazo de Prometheus — es el servicio gestionado que elimina la carga operativa. Consultas PromQL, recording rules, ingestión por scraping: todo soportado. Glouton recopila tus endpoints /metrics existentes, Bleemeo los almacena y los consulta, y dejas de operar almacenamiento. Nada que desplegar, nada que mantener. Si tu clúster está en apuros, la plataforma sigue funcionando fuera de él — para que la alerta crítica que necesitas recibir llegue de verdad.
On-premise o en la nube, Bleemeo supervisa los clústeres Kubernetes de mis clientes sin complejidad. Una herramienta que recomiendo por su simplicidad y la claridad que aporta.

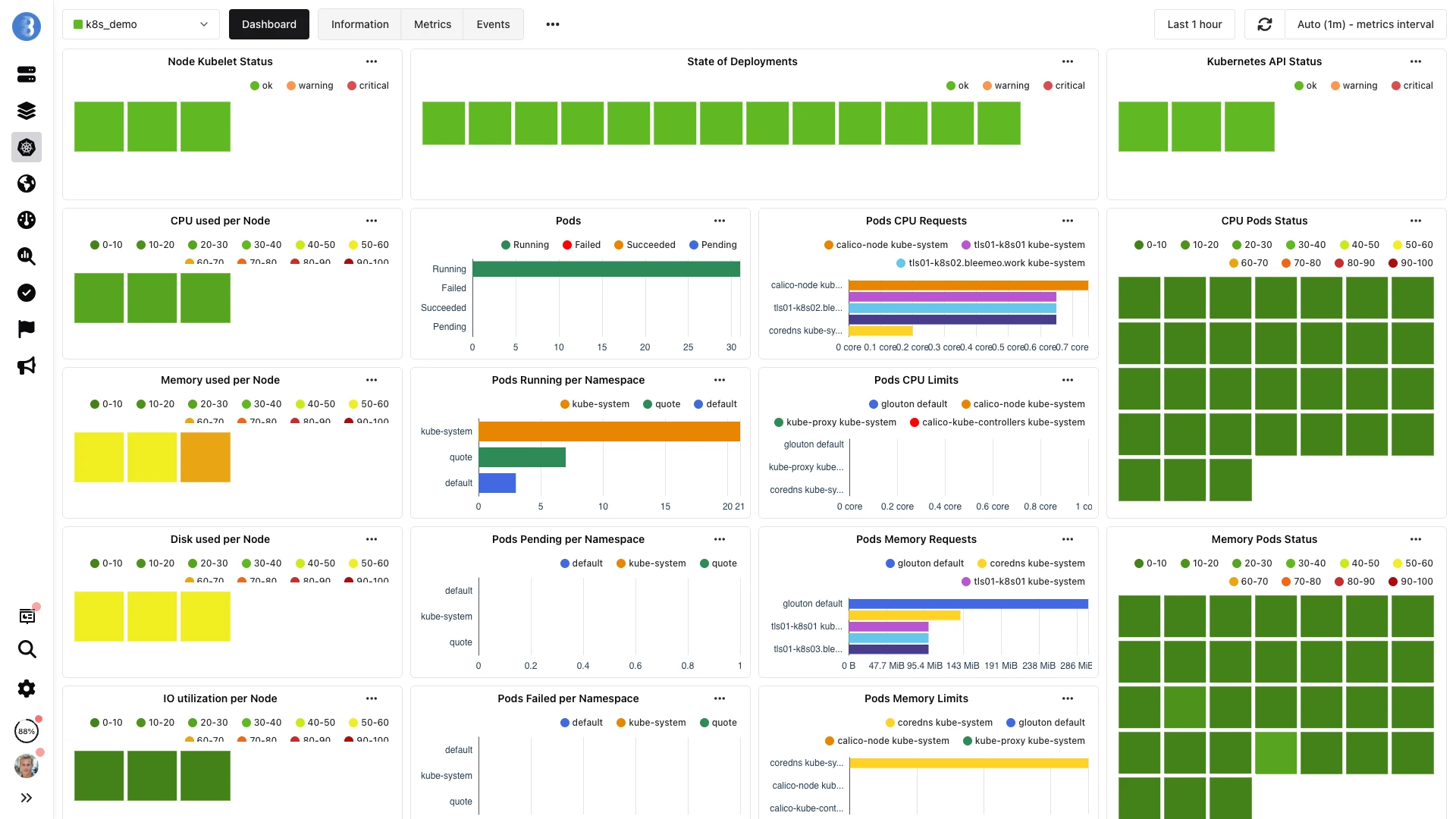
helm install al dashboardGlouton aterriza en un clúster nuevo y el dashboard se llena — capturado abajo.

30 segundos del despliegue al dashboard.
Ejecuta el mismo flujo en tu propio clúster — los mismos 30 segundos.
Cada capa
Desde la salud del cluster hasta las métricas de contenedores individuales, nuestro servidor de métricas kubernetes te ofrece visibilidad completa de tu entorno Kubernetes.
Salud del plano de control, latencia del API Server, rendimiento de etcd, métricas del scheduler
CPU, memoria, disco, red, estado de kubelet, condiciones del nodo
Ciclo de vida de pods, conteo de reinicios, resource requests vs limits, readiness
Throttling de CPU, uso de memoria, eventos OOM, estados de contenedores
Endpoints de servicios, tráfico de ingress, resolución DNS, network policies
Uso de PersistentVolume, estado de claims, capacidad de storage class, salud de montajes
Métricas de contenedores
Monitorea el corazón de tu cluster Kubernetes para confiabilidad y rendimiento.
Rastrea la salud de los nodos y el rendimiento de kubelet en todo tu cluster.
Visibilidad profunda del rendimiento de cargas de trabajo y consumo de recursos.
Monitorea endpoints de servicios y conectividad de red.
Rastrea Deployments, StatefulSets, DaemonSets y Jobs.
Monitorea PersistentVolumes y rendimiento de almacenamiento.
Nativo
Descubre y monitorea automáticamente pods, servicios y endpoints. Sin configuración manual necesaria mientras las cargas de trabajo escalan.
Soporte nativo de PromQL. Recolecta endpoints Prometheus existentes. Usa tus recording rules y alertas existentes.
Filtra y agrega por labels y annotations de Kubernetes. Agrupa métricas por namespace, deployment o labels personalizados.
Dimensiona correctamente los resource requests y limits basándote en el uso real. Identifica cargas de trabajo sobre-aprovisionadas y sub-aprovisionadas.
Alertas preconfiguradas para problemas comunes de K8s: CrashLoopBackOff, pods pendientes, nodo NotReady, expiración de certificados.
Monitorea múltiples clusters Kubernetes desde un único dashboard. Compara el rendimiento entre entornos.
Despliega el agente Bleemeo con un único Helm chart. Listo para GitOps con opciones de personalización completas.
Ingesta métricas y logs vía OpenTelemetry. Correlaciona métricas de infraestructura con datos de aplicación.
Instalación
Añade el repositorio oficial de Helm charts de Bleemeo a tu instalación de Helm.
helm repo add bleemeo-agent https://packages.bleemeo.com/bleemeo-agent/helm-charts
helm repo updateDespliega el agente Glouton como DaemonSet con las credenciales de tu cuenta.
helm upgrade --install glouton bleemeo-agent/glouton \
--set account_id="your_account_id" \
--set registration_key="your_registration_key" \
--set config.kubernetes.clustername="my_k8s_cluster_name" \
--set namespace="default"Los nodos, pods y servicios aparecen automáticamente en tu dashboard de Bleemeo en segundos.
Despliegue
Glouton se despliega como DaemonSet, colocando automáticamente un pod de agente en cada nodo de tu cluster, incluidos los nodos añadidos por autoscalers.
Arquitectura
Un pod Glouton por nodo garantiza cobertura completa del cluster, desde la salud del plano de control hasta métricas individuales de contenedores.
Glouton se despliega como un DaemonSet vía Helm, colocando exactamente un pod de agente en cada nodo de tu cluster. El Helm chart incluye tolerations para todos los tipos de nodos estándar: nodos GPU, nodos de sistema y nodos gestionados por autoscaler reciben un agente automáticamente. Solo se requieren tres variables de entorno: GLOUTON_ACCOUNT_ID, GLOUTON_REGISTRATION_KEY y GLOUTON_KUBERNETES_CLUSTERNAME. El pod del agente solicita recursos mínimos (menos de 100 MB de memoria) y no competirá con tus cargas de trabajo de producción.
Las annotations de Kubernetes en tus pods controlan cómo Glouton interactúa con cada carga de trabajo. Establece glouton.enable: "false" para excluir un pod del monitoreo por completo. Usa glouton.check.ignore.port.* para omitir health checks en puertos específicos (útil para contenedores sidecar o puertos de depuración). Añade annotations estándar de Prometheus (prometheus.io/scrape: "true", prometheus.io/port, prometheus.io/path) para exponer métricas específicas de aplicación que Glouton recolectará y enviará a Bleemeo Cloud junto con las métricas de infraestructura.
Más allá de los conteos básicos de pods y nodos, Glouton recopila métricas profundas de Kubernetes: conteos de pods por estado (Running, Pending, Failed, Succeeded), conteos de reinicios por contenedor, uso de CPU y memoria comparado con requests y limits, conteos de nodos y namespaces, fechas de expiración de certificados para CA y certificados de nodo, e indicadores de salud del API Server y kubelet. Todas las métricas están etiquetadas con namespace, tipo de propietario (Deployment, DaemonSet, StatefulSet) y nombre del propietario para un filtrado y agregación potentes en los dashboards.
Sobreescribe los valores predeterminados de Glouton por cluster usando un Kubernetes ConfigMap. Excluye namespaces completos del monitoreo (por ejemplo, kube-system o namespaces de CI runners), ajusta los intervalos de recolección de métricas, añade labels personalizados a todas las métricas de un cluster específico, o configura targets de Prometheus adicionales. El enfoque de ConfigMap se integra naturalmente con flujos de trabajo GitOps: almacena tu configuración de monitoreo junto a los manifiestos de tu aplicación y deja que ArgoCD o Flux lo gestionen de forma declarativa.
Alertas
Recibe notificaciones sobre problemas comunes de Kubernetes antes de que impacten a tus usuarios.
Ecosistema
Beneficios
Ve la creación de pods, eventos de escalado y fallos a medida que ocurren. Sin demora en la recolección de métricas.
Identifica desperdicio de recursos y dimensiona correctamente tus cargas de trabajo. Reduce el gasto en la nube sin impactar el rendimiento.
Glouton usa recursos mínimos. Menos de 100MB de memoria por nodo. No competirá con tus cargas de trabajo.
El monitoreo de Kubernetes es la práctica de recopilar, analizar y alertar sobre métricas de cada capa de un entorno Kubernetes, desde el plano de control del cluster hasta los procesos individuales de contenedores. A diferencia del monitoreo de servidores tradicional, Kubernetes introduce desafíos únicos: las cargas de trabajo son efímeras, los pods se crean y destruyen constantemente, y una sola aplicación puede abarcar docenas de réplicas en múltiples nodos.
Un monitoreo efectivo de Kubernetes requiere visibilidad en cuatro capas distintas. La capa de cluster rastrea la salud del plano de control, la latencia del API Server, el rendimiento de etcd y la expiración de certificados. La capa de nodos monitorea CPU, memoria, disco y estado de kubelet en cada nodo worker. La capa de cargas de trabajo rastrea réplicas de Deployment, ordenamiento de StatefulSet, cobertura de DaemonSet y completación de Jobs. Finalmente, la capa de pods y contenedores proporciona uso de recursos, conteos de reinicios, eventos OOM y throttling de CPU por contenedor.
Sin monitoreo multicapa, los operadores de Kubernetes se ven obligados a usar comandos kubectl e inspección manual de logs para diagnosticar problemas, un enfoque reactivo que no escala. Una solución de monitoreo adecuada como Bleemeo recopila métricas de las cuatro capas automáticamente mediante despliegue DaemonSet, correlaciona datos entre capas y proporciona alertas predefinidas para modos de fallo comunes como CrashLoopBackOff, pods pendientes y expiración de certificados.
Métricas
Rastrea conteos de pods por estado (Running, Pending, Failed, Succeeded), conteos de reinicios por contenedor, uso de CPU y memoria versus requests y limits, y antigüedad del pod. Los labels incluyen namespace, tipo de propietario (Deployment, DaemonSet, StatefulSet) y nombre del propietario para agregación y filtrado fáciles.
Compara lo que los pods solicitaron (requests de CPU y memoria) con lo que realmente consumen. Identifica cargas de trabajo sobre-aprovisionadas desperdiciando recursos y las sub-aprovisionadas en riesgo de throttling de CPU u OOMKill. Estos datos son esenciales para dimensionar correctamente las definiciones de recursos en tus manifiestos de deployment.
Monitorea el conteo total de nodos, nodos Ready vs NotReady, conteo de namespaces y estado general del cluster. Rastrea la disponibilidad del API Server, la latencia de etcd y la profundidad de cola del scheduler. Estas métricas te ayudan a evaluar la salud general y capacidad de tu infraestructura Kubernetes.
Rastrea las fechas de expiración de certificados CA y certificados de nodo usados para la comunicación interna de Kubernetes. Recibe alertas antes de que los certificados expiren, una causa común de fallos repentinos del cluster que es completamente prevenible con monitoreo automatizado.
Monitorea el estado de salud de kubelet en cada nodo, condiciones del nodo (Ready, DiskPressure, MemoryPressure, PIDPressure) y salud del runtime de contenedores. Detecta nodos degradados antes de que comiencen a expulsar pods o se vuelvan NotReady.
Rastrea bytes de red recibidos y transmitidos por pod, paquetes descartados y conteos de errores. Monitorea tasas de solicitudes del controlador de Ingress, latencias de respuesta y ratios de errores HTTP. Correlaciona métricas de red con reinicios de pods o degradación de servicios para identificar problemas de conectividad, fallos de resolución DNS o network policies mal configuradas.
Casos de uso
Cuando un pod entra en CrashLoopBackOff, necesitas saber por qué inmediatamente. Bleemeo muestra el conteo de reinicios, el último código de salida, logs del contenedor y métricas correlacionadas a nivel de nodo. Determina si el crash es causado por errores de aplicación, OOM kills o presión de recursos del nodo subyacente, todo desde un único dashboard.
Los resource requests sobre-aprovisionados desperdician capacidad del cluster y aumentan los costos en la nube. Los requests sub-aprovisionados causan throttling y OOM kills. Usa las métricas de resource requests vs uso real de Bleemeo a lo largo del tiempo para identificar los requests óptimos de CPU y memoria para cada carga de trabajo, reduciendo el desperdicio mientras previenes la contención de recursos.
Rastrea las tendencias de utilización de recursos del cluster a lo largo de semanas y meses. Identifica cuándo los nodos se acercan a los límites de capacidad y planifica eventos de escalado antes de que los pods queden pendientes por recursos insuficientes. Usa 13 meses de datos históricos para prever patrones estacionales y presupuestar el crecimiento de infraestructura.
Monitorea clusters de desarrollo, staging y producción desde un único dashboard. Compara la utilización de recursos entre entornos, detecta desviaciones de configuración entre clusters y asegúrate de que los clusters de staging reflejen el dimensionamiento de producción. Cada cluster se identifica por su nombre configurado para filtrado fácil.
Después de un despliegue de Flux o ArgoCD, monitorea el rollout en tiempo real. Rastrea la creación de nuevos pods, la terminación de pods antiguos y la disponibilidad de réplicas durante rolling updates. Detecta despliegues fallidos (rollouts atascados, crash loops en nuevas versiones) y correlaciona el timing del despliegue con cambios en métricas para validar que los releases funcionan como se espera.
Analiza el consumo de recursos por namespace para asignar costos de infraestructura a equipos o proyectos. Identifica namespaces con utilización consistentemente baja de CPU y memoria que están sobre-aprovisionados. Usa datos históricos de uso para dimensionar correctamente los node pools del cluster, cambiar a instancias spot o preemptibles para cargas de trabajo tolerantes, y reducir el gasto general en infraestructura Kubernetes.
Buenas prácticas
Ejecuta el agente de monitoreo como DaemonSet para que cada nodo reciba automáticamente un pod de agente, incluidos los nodos añadidos por autoscalers. Esto garantiza cobertura completa del cluster sin intervención manual. El Helm chart de Bleemeo lo maneja por defecto, incluyendo tolerations y resource limits adecuados.
Añade prometheus.io/scrape: "true" a las annotations de tus pods para exponer métricas específicas de aplicación mediante el formato Prometheus. El agente de Bleemeo descubre estos endpoints automáticamente y envía las métricas a la nube. Este es el enfoque estándar nativo de Kubernetes para métricas personalizadas de aplicación sin requerir configuración adicional.
Los pods sin resource requests no pueden dimensionarse correctamente porque no hay una línea base con la cual comparar. Siempre establece requests de CPU y memoria en tus manifiestos de deployment. Bleemeo luego compara el uso real con los recursos solicitados, permitiendo decisiones de dimensionamiento basadas en datos que reducen el desperdicio y previenen la contención de recursos.
Kubernetes usa certificados TLS para la comunicación interna entre el API Server, kubelet y etcd. Los certificados expirados causan fallos repentinos y totales del cluster. Bleemeo rastrea las fechas de expiración de certificados y te alerta antes de que expiren, dándote tiempo para rotar certificados proactivamente en lugar de descubrir el problema durante una caída.
Un conteo de reinicios de pod en aumento te dice que algo está mal. Los logs del contenedor te dicen exactamente qué. Habilita la recolección de logs junto con las métricas para el análisis de causa raíz más rápido. El agente de Bleemeo recopila ambos desde el mismo DaemonSet, y la plataforma cloud los muestra juntos, vinculados por nombre de pod y timestamp.
¿Quieres ir más allá?
Leer la DocumentaciónTodo lo que necesitas saber sobre el monitoreo de Kubernetes de Bleemeo
Bleemeo se despliega mediante Helm chart como un DaemonSet, colocando un agente Glouton en cada nodo. Simplemente añade el repositorio Helm de Bleemeo, luego ejecuta helm upgrade --install con las credenciales de tu cuenta y nombre de cluster. El agente descubre automáticamente todos los pods y servicios. También puedes desplegar usando kubectl plano con nuestros manifiestos proporcionados. Herramientas GitOps como ArgoCD y Flux son totalmente compatibles.
Bleemeo recopila métricas completas incluyendo: Métricas de pods (conteo por estado, conteo de reinicios, uso de CPU/memoria vs requests/limits), Métricas de nodos (CPU, memoria, disco, red, estado de kubelet), Métricas de cluster (conteo de nodos, conteo de namespaces, estado de API) y Expiración de certificados (CA y certificados de nodo). Las métricas se etiquetan por namespace, tipo de propietario (Deployment, DaemonSet) y nombre del propietario para filtrado fácil.
Sí, el auto-descubrimiento de servicios es una característica central. El agente de Bleemeo detecta todos los servicios ejecutándose en tus pods (bases de datos, servidores web, colas de mensajes, etc.) y comienza a monitorearlos sin configuración manual. Reconoce más de 100 servicios de serie. A medida que los pods escalan arriba o abajo, el monitoreo sigue automáticamente; no se necesita reconfiguración para cargas de trabajo efímeras.
Sí, Bleemeo soporta recolección estilo Prometheus mediante anotaciones de pods. Añade prometheus.io/scrape: "true" a tus pods, y opcionalmente especifica prometheus.io/path y prometheus.io/port para endpoints de métricas personalizados. El agente descubre y recolecta automáticamente estos endpoints. También puedes usar PromQL para consultar métricas en tus dashboards.
El agente Glouton está diseñado para ser ligero. Típicamente usa menos de 100MB de memoria y CPU mínimo por nodo. El agente no competirá con tus cargas de trabajo de producción por recursos. Los resource requests y limits pueden personalizarse en los valores de Helm si es necesario. El agente está optimizado para entornos de alta densidad con muchos pods por nodo.
Bleemeo no es un reemplazo de Prometheus — es el servicio gestionado que elimina la carga operativa. PromQL, recording rules e ingestión por scraping: todo soportado. Glouton recopila tus endpoints /metrics existentes, la plataforma los almacena y los consulta, y dejas de operar almacenamiento. Ningún servidor Prometheus que escalar, ningún clúster Thanos o Mimir que operar, ningún Grafana que actualizar. Bleemeo también funciona fuera de tu clúster sobre una plataforma con SLA 99,99 %, para que las alertas te lleguen incluso cuando tu infraestructura tiene problemas.
Bleemeo funciona con todas las principales distribuciones de Kubernetes: Servicios gestionados (EKS, GKE, AKS, DigitalOcean Kubernetes), Auto-gestionados (kubeadm, k3s, k0s, microk8s) y Distribuciones enterprise (OpenShift, Rancher, Tanzu). Soportamos Kubernetes 1.19+. El agente se adapta a diferentes runtimes de contenedores incluyendo containerd, CRI-O y Docker.
Sí, Bleemeo soporta monitoreo multi-cluster. Cada cluster aparece como una entidad separada en tu dashboard con su propio nombre (configurado mediante config.kubernetes.clustername). Puedes ver todos los clusters en un dashboard unificado, comparar métricas entre clusters y profundizar en detalles de clusters individuales. Esto es ideal para gestionar entornos de desarrollo, staging y producción.
Bleemeo incluye alertas preconstruidas para problemas comunes de Kubernetes: Problemas de pods (CrashLoopBackOff, pods pendientes, alto conteo de reinicios, OOMKilled), Problemas de nodos (NotReady, presión de disco/memoria), Problemas de cluster (errores del API Server, certificado por expirar) y Problemas de cargas de trabajo (réplicas de deployment no disponibles, jobs fallidos). Puedes personalizar umbrales o crear alertas adicionales.
Bleemeo recopila tanto los resource requests/limits como el uso real de CPU y memoria. Los dashboards muestran la comparación entre lo que los pods solicitaron y lo que realmente están usando, ayudándote a identificar cargas de trabajo sobre-aprovisionadas (desperdiciando recursos) y sub-aprovisionadas (en riesgo de throttling o OOM). Esto permite el dimensionamiento correcto efectivo de tus cargas de trabajo.
Sí, con la recolección de logs habilitada, Glouton captura automáticamente logs de todos los contenedores en tu cluster de Kubernetes. Los logs se recopilan de stdout/stderr de contenedores sin configuración adicional. Puedes aplicar parsers y filtros personalizados usando anotaciones de pods (glouton.log_format, glouton.log_filter). Los logs pueden correlacionarse con métricas para una solución de problemas completa.
Unos 30 segundos de instalación real. Un helm upgrade --install con tres variables de entorno (account ID, registration key, nombre del clúster) despliega Glouton como DaemonSet en todo tu clúster. El descubrimiento automático reconoce más de 100 servicios sin configuración; los dashboards y reglas de alerta Kubernetes vienen listos para usar. Ningún PVC que aprovisionar, ningún scrape config que escribir, ningún dashboard que importar, ninguna regla de alerta que escribir.