

Construit sur Prometheus & OpenTelemetry
Sans verrouillage fournisseur
Prometheus est le standard pour les métriques, mais l'exploiter en production implique de gérer Alertmanager, Grafana, le stockage à long terme et la planification de capacité. Bleemeo vous offre la même visibilité avec zéro serveur à provisionner et zéro alerte nocturne concernant votre stack de monitoring.
Essai gratuit 15 joursSans carte bancaireSans engagement
Sans verrouillage fournisseur
Données hébergées dans l'UE · Conforme RGPD
À travers l'Europe et au-delà
Plus de 500 équipes utilisent Prometheus sans la charge d'exploitation
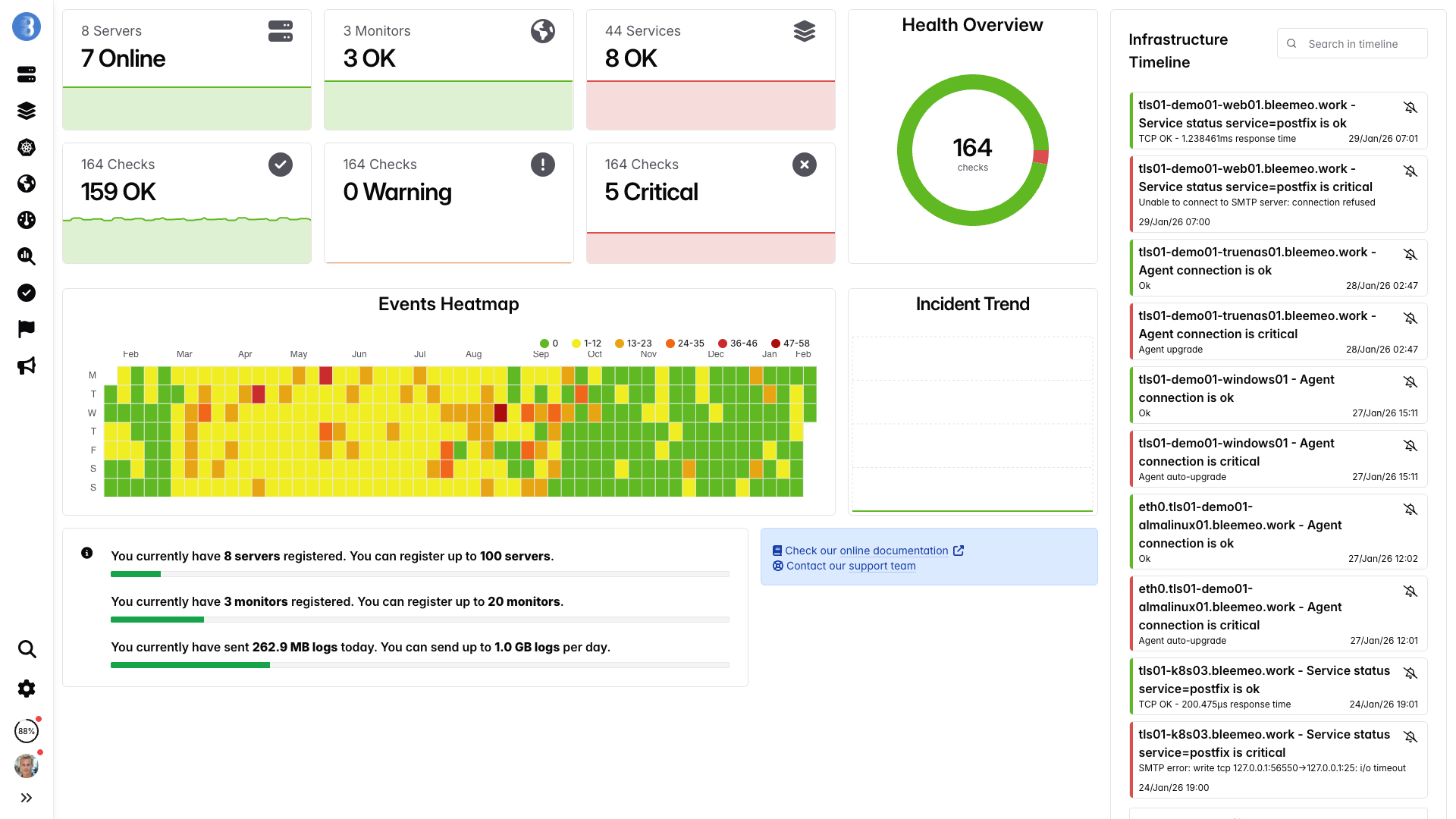
Tableaux de bord en temps réel, prêts en quelques minutes — aucune configuration nécessaire
De l'inscription au dashboard en 30 secondes — gardez PromQL, abandonnez l'ops
Une commande, aucune configuration — les métriques arrivent en moins d'une minute.
Pourquoi changer
Faire fonctionner Prometheus à grande échelle implique de maintenir plusieurs instances Prometheus, de configurer la fédération ou le sharding, et de construire des pipelines pour déplacer les données entre les composants. Chaque instance supplémentaire nécessite sa propre allocation de ressources, sa configuration de scrape et ses règles de recording — créant une charge opérationnelle qui croît linéairement avec votre infrastructure.
Prometheus ne conserve par défaut que 15 jours de données, ce qui signifie que toute analyse historique ou planification de capacité nécessite une solution de stockage à long terme séparée. Thanos, Cortex et Mimir résolvent chacun ce problème mais introduisent leur propre architecture, dépendances de stockage objet et processus de compaction qui nécessitent un réglage et une surveillance attentifs.
Prometheus ne fournit qu'un navigateur d'expressions basique — pas de tableaux de bord intégrés ni d'interface soignée. Vous avez besoin de Grafana pour la visualisation et d'Alertmanager pour les notifications, tous deux nécessitant une configuration manuelle. Chaque panneau de tableau de bord, chaque règle d'alerte et chaque règle de recording doit être écrit manuellement en PromQL et maintenu via le contrôle de version à mesure que votre infrastructure évolue.
Les métriques à haute cardinalité provenant d'environnements dynamiques comme Kubernetes peuvent provoquer des pics de mémoire soudains et des OOM kills qui font tomber toute votre stack de monitoring. La mise à l'échelle de Prometheus nécessite un sharding sur plusieurs instances ou la mise en place de hiérarchies de fédération, et les politiques de rétention doivent être soigneusement équilibrées avec l'espace disque disponible. La planification de capacité devient une tâche récurrente qui éloigne les ingénieurs du développement produit.
Le déploiement de Bleemeo a été incroyablement rapide. En environ une heure, nous l'avons déployé sur plus de 100 serveurs et avons immédiatement obtenu une visibilité complète sur notre infrastructure.

Comparatif
| Feature | Prometheus (auto-hébergé) | Bleemeo |
|---|---|---|
| Temps d'installation | Des heures à des jours de configuration | 5 minutes, une seule commande |
| Infrastructure requise | Prometheus + Alertmanager + Grafana + stockage | Aucune — SaaS entièrement managé |
| Stockage à long terme | Thanos/Cortex/Mimir requis | 13 mois inclus |
| Découverte de services | Configuration de scrape manuelle par cible | Automatique, zéro configuration |
| Tableaux de bord | Construire dans Grafana à partir de zéro | Préconstruits, activés automatiquement |
| Règles d'alerte | Écrire et maintenir des règles PromQL | Valeurs par défaut intelligentes + détection d'anomalies par ML |
| Haute disponibilité | Stacks dupliquées + fédération | Redondance intégrée |
| Maintenance | Mises à jour, mise à l'échelle, dépannage | Zéro — nous gérons tout |
| Modèle réseau | Pull : nécessite un accès réseau à toutes les cibles | Push : les agents envoient les données en sortie, aucun port entrant nécessaire |
| Gestion de la cardinalité | La haute cardinalité cause une pression mémoire et des OOM kills | Gérée côté serveur avec des contrôles automatiques de cardinalité |
| Gestion des logs | Non incluse — nécessite Loki ou une stack séparée | Collecte et recherche de logs intégrées aux métriques |
| Compatibilité PromQL | Natif | Métriques compatibles Prometheus |
| Agent open source | Exporters Prometheus | Glouton (Apache 2.0) |
Coûts
Pour une infrastructure typique de 100 serveurs avec Prometheus auto-hébergé, le coût réel va bien au-delà du calcul et du stockage — il inclut les heures d'ingénierie passées à maintenir, dépanner et faire évoluer votre stack de monitoring au lieu de développer des fonctionnalités produit.
*Plus les coûts cachés : fatigue d'astreinte, silos de connaissances et coût d'opportunité des ingénieurs ne travaillant pas sur le produit
*Avec réservation 1 an. Aucun coût d'infrastructure.
Les chiffres ci-dessus reposent sur une infrastructure de 100 hôtes. Saisissez votre propre nombre d'hôtes et volume d'ingestion pour estimer vos économies en exploitant Prometheus sur Bleemeo plutôt qu'en auto-hébergé.
Avantages
Plus de serveurs Prometheus à maintenir, plus de clusters Thanos à surveiller, plus d'instances Grafana à mettre à jour, et plus de buckets de stockage objet à gérer. Bleemeo gère toute l'infrastructure pour que votre équipe puisse se concentrer sur le développement de fonctionnalités produit au lieu de maintenir la stack de monitoring en vie. Vous n'avez plus jamais à vous soucier de l'espace disque, de la pression mémoire ou des OOM kills dans votre couche d'observabilité.
Glouton scrape directement les exporters Prometheus et conserve intacts vos exporters et votre code d'instrumentation existants. Bleemeo supporte les mêmes formats de métriques compatibles Prometheus et les mêmes labels que vous utilisez déjà, ce qui en fait un remplacement direct de votre backend Prometheus sans réécrire une seule règle de recording ou configuration de relabeling.
Contrairement à Prometheus, qui nécessite une configuration de scrape manuelle pour chaque nouvelle cible, l'agent Bleemeo Glouton détecte automatiquement les services en cours d'exécution — bases de données, serveurs web, brokers de messages et plus encore — et commence immédiatement à collecter les bonnes métriques. Pas d'édition de YAML, pas de plugins de découverte de services, pas de règles de relabeling à maintenir.
Alors que Prometheus vous offre un navigateur d'expressions vierge, Bleemeo fournit de riches tableaux de bord préconstruits, des seuils d'alerte intelligents et une détection d'anomalies par ML qui s'activent automatiquement dès qu'un service est découvert. Plus besoin de passer des jours à créer des panneaux Grafana ou à écrire des règles d'alerte PromQL depuis zéro pour chaque nouvelle application déployée.
Glouton, notre agent de monitoring, est entièrement open source sous licence Apache 2.0. Vous pouvez auditer chaque ligne de code exécutée sur vos serveurs, contribuer des améliorations et être assuré qu'il n'y a aucun verrouillage fournisseur. Vos données de métriques restent les vôtrès, et vous pouvez les exporter à tout moment en utilisant les formats standard Prometheus.
Toutes vos données de monitoring sont stockées dans des centres de données européens avec une conformité RGPD complète intégrée dès le premier jour. Contrairement aux alternatives SaaS américaines, Bleemeo est une entreprise européenne qui conserve votre télémétrie d'infrastructure sous la juridiction de l'UE, vous offrant une conformité simple pour les exigences de résidence des données.
Fonctionnalités
Supervision complète du CPU, de la mémoire, du disque, du réseau et des processus avec découverte automatique des services qui détecte bases de données, serveurs web et runtimes applicatifs sans aucune configuration. Obtenez une visibilité plus profonde que les métriques standard du node_exporter Prometheus dès l'installation.
Support natif Docker et Kubernetes avec métriques au niveau des pods, monitoring de la santé des nœuds et vues d'ensemble du cluster. Contrairement à Prometheus, qui nécessite kube-state-metrics, cAdvisor et des règles de relabeling complexes, Bleemeo fournit un monitoring des conteneurs qui fonctionne immédiatement après l'installation de l'agent.
Collectez, indexez et recherchez des logs aux côtés de vos métriques dans une seule plateforme unifiée. Prometheus n'a aucune gestion des logs — les équipes ajoutent généralement Loki, Elasticsearch ou Splunk comme un système supplémentaire à gérer. Avec Bleemeo, logs et métriques cohabitent, rendant l'analyse des causes racines plus rapide et plus simple.
La détection d'anomalies par machine learning identifie les schémas inhabituels avant qu'ils ne deviennent des pannes, complétant les seuils d'alerte préconfigurés pour chaque service découvert. Plus besoin d'écrire et d'ajuster manuellement des règles d'alerte PromQL ou de maintenir des arbres de routage Alertmanager — les valeurs par défaut intelligentes couvrent les cas courants tandis que vous personnalisez ce qui compte le plus.
Construisez les vues exactes dont votre équipe a besoin avec des widgets intuitifs en glisser-déposer, ou partez de la riche bibliothèque de tableaux de bord préconstruits qui s'activent automatiquement. Contrairement à Grafana, où chaque panneau nécessite des requêtes PromQL manuelles et une configuration JSON, les tableaux de bord Bleemeo sont prêts à l'emploi dès que vos agents se connectent.
Vérifications de disponibilité HTTP, TCP et ICMP depuis plusieurs emplacements mondiaux, avec monitoring de l'expiration des certificats SSL et suivi des temps de réponse. Le blackbox_exporter de Prometheus fournit un sondage basique, mais Bleemeo offre une approche entièrement managée et multi-sites avec alerting intégré et pages de statut ne nécessitant aucune infrastructure de votre côté.
Migration
La plupart des équipes font tourner les deux systèmes en parallèle pendant quelques semaines avant de basculer complètement. La migration est simple et non perturbante — les agents Bleemeo fonctionnent aux côtés de votre installation Prometheus existante sans conflit. Notre équipe est disponible pour vous aider dans la planification et la validation de la migration à chaque étape.
Installez l'agent Bleemeo aux côtés de vos exporters Prometheus existants avec une seule commande. L'agent fonctionne indépendamment et n'interfère pas avec votre stack de monitoring actuelle, donc zéro risque pendant la période de transition :
wget -qO- 'https://get.bleemeo.com?accountId=...' | sudo bashOuvrez le tableau de bord Bleemeo et vérifiez que tous vos serveurs et services ont été automatiquement détectés. Comparez la liste des services découverts avec vos cibles de scrape Prometheus pour confirmer une couverture complète. Glouton identifie bases de données, serveurs web, brokers de messages et runtimes applicatifs sans aucun fichier de configuration.
Si vous avez des exporters Prometheus personnalisés ou une instrumentation au niveau applicatif, configurez Glouton pour scraper directement leurs endpoints. Cela vous donne une vue unifiée des métriques collectées par l'agent et scrapées depuis les exporters dans une seule plateforme, tout en préservant vos labels et noms de métriques existants.
Examinez les tableaux de bord préconstruits de Bleemeo et comparez-les côte à côte avec vos panneaux Grafana existants. Confirmez que les métriques, les plages temporelles et la granularité correspondent à vos besoins opérationnels. La plupart des équipes constatent que les tableaux de bord automatiques de Bleemeo couvrent leurs cas d'usage clés sans aucune personnalisation requise.
Configurez vos canaux de notification préférés — Slack, PagerDuty, email, Microsoft Teams ou webhooks personnalisés — pour remplacer votre configuration de routage Alertmanager. L'alerting de Bleemeo est livré avec des seuils par défaut pertinents déjà actifs pour chaque service découvert, vous êtes donc couvert dès le départ pendant que vous ajustez les préférences de notification.
Une fois que vous avez validé que Bleemeo fournit une couverture complète et que votre équipe est à l'aise avec les nouveaux tableaux de bord et l'alerting, décommissionnez vos serveurs Prometheus auto-hébergés, clusters Alertmanager, instances Grafana et backends de stockage Thanos ou Mimir. Récupérez les ressources de calcul et libérez votre équipe d'ingénierie de la maintenance de la stack de monitoring définitivement.
Ingénieurs et CTO font confiance à Bleemeo pour surveiller leur infrastructure
Nous avons besoin que nos équipes restent concentrées sur notre métier — l'affichage dynamique — plutôt que sur la surveillance d'infrastructure. Bleemeo supervise l'ensemble de notre environnement, du dédié à Azure, et libère nos équipes des alertes inutiles tout en garantissant notre qualité de service.

Bleemeo nous accompagne depuis des années : une supervision simple et fiable, essentielle pour la qualité de service que nous devons à nos clients.

On-premise ou cloud, Bleemeo supervise les clusters Kubernetes de mes clients sans complexité. Un outil que je recommande pour sa simplicité et la clarté qu'il apporte.

Client depuis le premier jour, je suis ravi de Bleemeo. C'est facile à installer, efficace, et ça ne cesse de s'améliorer !

Pendant une courte pause déjeuner, nous avons installé Bleemeo, créé une métrique personnalisée, testé les alertes et étions prêts pour la production. La rapidité de déploiement est remarquable.

Le support Bleemeo est tout simplement légendaire — rapide, compétent et toujours présent quand on en a besoin.

Le déploiement de Bleemeo a été incroyablement rapide. En environ une heure, nous l'avons déployé sur plus de 100 serveurs et avons immédiatement obtenu une visibilité complète sur notre infrastructure.
Nous avons mis en place le monitoring de tous nos serveurs en quelques heures seulement. Le tableau de bord est clair, puissant et véritablement agréable à utiliser.

Nous avons déployé Bleemeo sur l'ensemble de notre infrastructure serveur en quelques heures seulement. Le monitoring de disponibilité nous alerte désormais instantanément dès qu'un service rencontre un problème.

Démo
Découvrez comment les équipes passent de l'installation au monitoring complet en moins de 5 minutes
Oui. Bleemeo collecte les mêmes métriques d'infrastructure, scrape nativement les exporters Prometheus pour les métriques personnalisées, et inclut tableaux de bord, alerting et 13 mois de stockage — sans aucun serveur à gérer.
Glouton, l'agent Bleemeo, scrape nativement les exporters Prometheus en utilisant le format d'exposition standard. Vos exporters existants et votre instrumentation fonctionnent directement.
Bleemeo stocke les métriques en pleine résolution pendant 13 mois, inclus dans le prix de base. Pas besoin de Thanos, Cortex ou Mimir.
Oui. Glouton est sous licence Apache 2.0 et prend en charge la découverte automatique de plus de 100 services — aucune configuration de scrape nécessaire.
Oui. Glouton scrape nativement n'importe quel endpoint d'exporter Prometheus. Vos exporters existants et votre instrumentation personnalisée fonctionnent sans modification.
Bleemeo inclut des seuils d'alerte préconfigurés pour chaque service découvert, ainsi que la détection d'anomalies par ML. Notifications par email, Slack, PagerDuty et webhooks — aucun Alertmanager à configurer.
Oui. Supervisez jusqu'à 3 serveurs gratuitement sans limité de durée. Toutes les fonctionnalités incluses — tableaux de bord, alertes, découverte de services.
Oui. De nombreuses équipes font tourner les deux pendant la migration. Glouton fonctionne indépendamment et n'interfère pas avec le scraping Prometheus existant.