Monitoriza tu producto SaaS en 10 minutos
Cada minuto de inactividad erosiona la confianza de tus clientes y tus ingresos. Obtén visibilidad completa de tus servidores, bases de datos, APIs y disponibilidad — antes de que tus clientes noten un problema.
Prueba gratuita de 15 días · Sin tarjeta de crédito · Listo para producción en minutos
Cuando tu SaaS cae, la confianza desaparece
La inactividad es devastadora
El coste medio de la inactividad IT es de $5.600 por minuto para empresas medianas. Para un producto SaaS, no es solo ingresos perdidos — son clientes que se van, integraciones rotas y penalizaciones SLA. Una sola interrupción prolongada puede deshacer meses de adquisición de clientes.
La monitorización DIY es un proyecto que nunca terminarás
Configurar Prometheus, Grafana, Alertmanager y almacenamiento a largo plazo lleva semanas. Luego necesitas mantenerlo, actualizarlo y escribir reglas de alerta para cada servicio. Es tiempo de ingeniería que no se dedica a construir tu producto.
Bleemeo: monitorización de producción sin el proyecto
Bleemeo te ofrece monitorización completa de infraestructura — servidores, bases de datos, servidores web, cachés, colas de mensajes y disponibilidad — en 10 minutos, sin ninguna configuración. Conoce los problemas antes de que tus clientes abran un ticket de soporte.
Se adapta a tu arquitectura
Ya ejecutes un monolito en un solo servidor o una arquitectura de microservicios en múltiples nubes, Bleemeo se adapta automáticamente a tu stack. Obtienes métricas de servidor, rendimiento de bases de datos, eficiencia de caché y monitorización de disponibilidad externa — todo desde un solo agente y un solo dashboard, con alertas listas para usar.
3 pasos para una monitorización SaaS completa
Tu equipo de ingeniería puede configurarlo durante una pausa para el café.
Instala el agente en tus servidores
Un comando por servidor. El agente Glouton de Bleemeo descubre automáticamente todo tu stack SaaS: servidor web, runtime de aplicación, base de datos, caché, broker de mensajes y motor de búsqueda.
wget -qO- 'https://get.bleemeo.com?accountId=...' Ejecuta este comando en cada servidor de tu stack. El agente detecta todo lo que se ejecuta en la máquina — sin archivos de configuración que escribir.
Stacks SaaS auto-detectados
Por qué el auto-descubrimiento importa para SaaS
Los stacks SaaS evolucionan rápido — nuevos servicios se despliegan, los contenedores se reemplazan, las dependencias cambian. Configurar manualmente la monitorización para cada componente lleva horas de YAML con el riesgo constante de puntos ciegos. Bleemeo detecta cada servicio en tu máquina en segundos, para que nada se escape — incluso cuando tu arquitectura evoluciona.
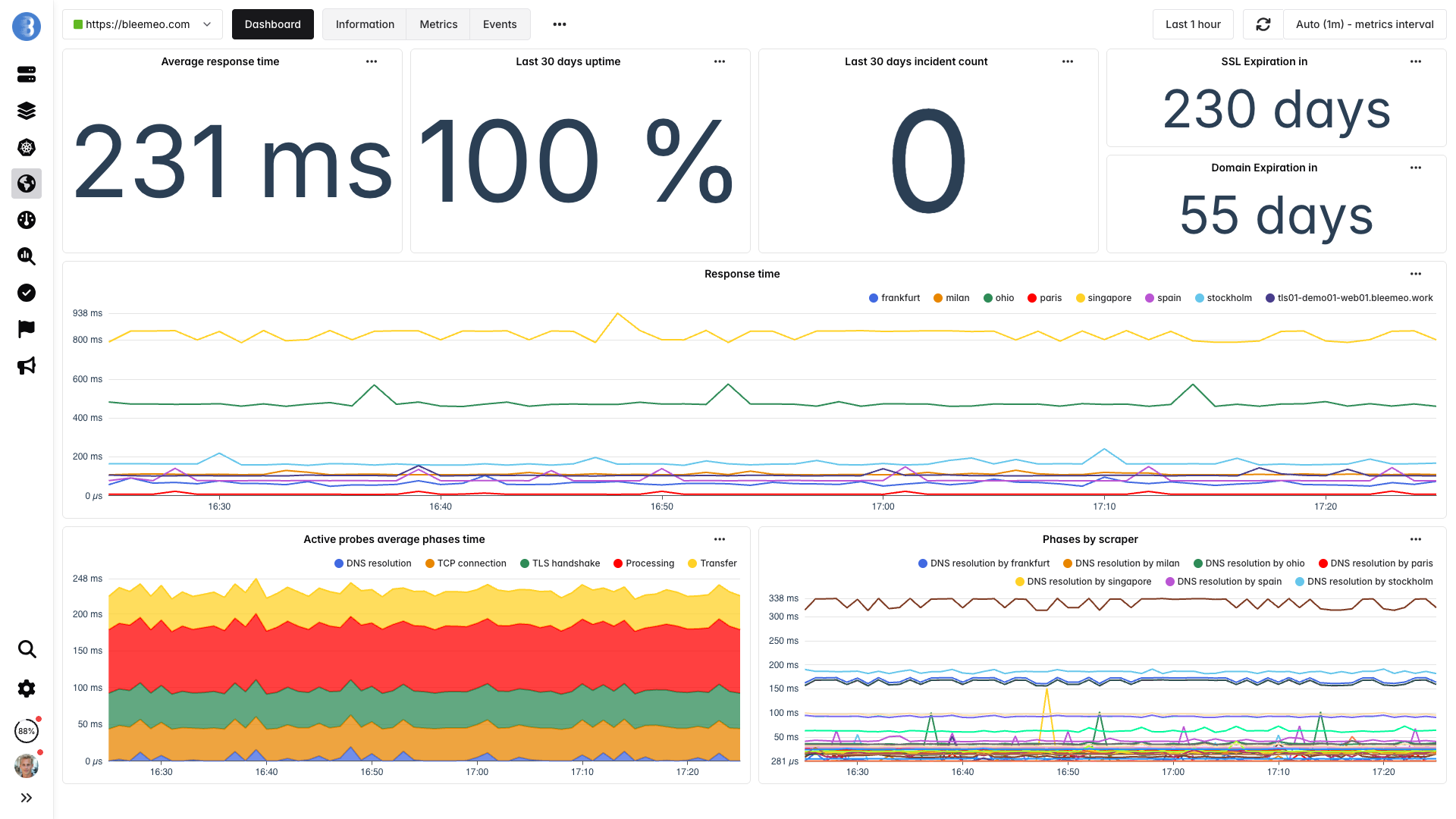
Añade monitores de disponibilidad para tus endpoints críticos
Monitoriza tus URLs más importantes desde 7 ubicaciones globales. Bleemeo verifica disponibilidad, tiempo de respuesta, expiración de certificados SSL y validación de contenido cada 60 segundos.
- Endpoints API — la columna vertebral de tu producto
- Aplicación web — página de login, dashboard, flujos clave
- Receptores de webhooks — fiabilidad de integraciones
- Página de estado — lo que tus clientes ven
- Panel de administración — tu columna vertebral operativa
Saber más: Funcionalidades de monitorización de disponibilidad
Por qué la monitorización externa es crítica para SaaS
Tus servidores pueden mostrar todo verde, pero un problema DNS, una mala configuración CDN o la expiración de un certificado puede impedir que tus clientes accedan a tu producto. La monitorización desde 7 ubicaciones globales ve lo que tus clientes ven — y detecta problemas que los health checks internos no captan.
Recibe alertas antes de que tus clientes se den cuenta
Las reglas de alerta predeterminadas se activan inmediatamente. Envía las notificaciones donde tu equipo trabaja — ya sean las 14:00 o las 2 de la madrugada.
Problemas de servidor
- Uso elevado de CPU
- Presión de memoria
- Disco lleno
Problemas de base de datos
- Consultas lentas
- Agotamiento del pool de conexiones
- Retraso de replicación
Errores del servidor web
- Pico de errores 5xx
- Tiempo de respuesta elevado
- Expiración SSL
Caché & disponibilidad
- Presión de memoria Redis/Memcached
- Inactividad desde cualquier ubicación
- Retraso en cola de mensajes
- Slack y Microsoft Teams
- Email (activado por defecto)
- PagerDuty, OpsGenie, VictorOps
- SMS vía Twilio o MessageBird
- Webhooks para integraciones personalizadas
Por qué los valores predeterminados inteligentes superan la configuración manual
Escribir reglas de alerta efectivas requiere un conocimiento profundo de los modos de fallo de cada servicio. Bleemeo viene con umbrales probados en batalla para cada servicio auto-detectado — estás protegido desde el primer minuto, sin pasar horas ajustando condiciones de alerta que podrían de todos modos fallar en detectar el problema real.
Qué monitorizas en tu stack SaaS
Cada capa de tu infraestructura, cubierta automáticamente.
Un producto SaaS es una cadena — y es tan fuerte como su eslabón más débil. Una consulta de base de datos lenta hace que tu API se arrastre. Un disco lleno bloquea tus procesos worker. Un pico de evictions de caché sobrecarga tu base de datos durante un pico de tráfico. Bleemeo monitoriza cada capa para que puedas ver dónde empiezan los problemas, no solo dónde se manifiestan.
Capa cliente
Esto es lo que tus clientes experimentan. Si tu API es lenta o tu página de login está caída, necesitas saberlo inmediatamente — no por un ticket de soporte una hora después.
- Disponibilidad desde 7 ubicaciones globales
- Seguimiento de tiempos de respuesta
- Monitorización de certificados SSL
Capa Web / Aplicación
Tu servidor web y tu runtime de aplicación manejan cada petición. Un pool de workers mal configurado o una fuga de memoria aquí afecta a cada usuario de tu producto.
Capa de datos
- Rendimiento de consultas MySQL / PostgreSQL
- Tasa de aciertos & memoria Redis / Memcached
- Profundidad & throughput de colas RabbitMQ / Kafka
Capa de infraestructura
- CPU, memoria, disco, red por servidor
- Métricas de contenedores Docker y pods Kubernetes
- Recopilación y búsqueda de logs
El coste de no monitorizar
Inactividad = Ingresos & confianza perdidos
Para un SaaS con $50K de MRR, incluso un 1% de inactividad cuesta $500/mes en créditos SLA directos — sin contar los clientes que se van silenciosamente. Bleemeo detecta caídas en menos de 60 segundos desde 7 ubicaciones globales, para que puedas empezar a arreglar en minutos, no en horas.
APIs lentas = Clientes perdidos
Los estudios muestran que el 53% de los usuarios abandonan un servicio si tarda más de 3 segundos en responder. Rastrea los tiempos de respuesta en tus endpoints API, aplicación web y webhooks — y recibe alertas antes de que la latencia se degrade hasta el punto en que los clientes busquen alternativas.
La monitorización cuesta < un solo incidente
Monitorizar 10 servidores con Bleemeo cuesta €109,90/mes. Es menos que el tiempo de ingeniería desperdiciado depurando una sola caída a ciegas. Prueba la calculadora de costes.
Diseñado para equipos SaaS en crecimiento
Bleemeo está diseñado para equipos de ingeniería que necesitan entregar funcionalidades, no mantener infraestructura de monitorización. Sin Prometheus que configurar, sin dashboards Grafana que construir, sin reglas de alerta que escribir. Tu equipo puede configurarlo durante una pausa para el café y volver a construir el producto por el que tus clientes pagan.
La mayoría de las empresas SaaS tienen equipos de ingeniería reducidos. Las mismas personas que construyen funcionalidades también gestionan infraestructura, despliegan y responden a incidentes. Bleemeo quita completamente la monitorización de esa carga — obtienes observabilidad de nivel producción sin contratar un SRE dedicado ni pasar semanas en herramientas que no son tu negocio principal.
Ver cómo funcionaDe confianza para equipos SaaS en producción
Ingenieros y CTOs confían en Bleemeo para monitorear su infraestructura
Durante una breve pausa para almorzar, instalamos Bleemeo, creamos una métrica personalizada, probamos las alertas y estábamos listos para producción. La velocidad de despliegue es notable.

El soporte de Bleemeo es simplemente legendario: rápido, competente y siempre disponible cuando lo necesitamos.
Bleemeo fue increíblemente rápido de desplegar. En aproximadamente una hora lo implementamos en más de 100 servidores y obtuvimos visibilidad completa de nuestra infraestructura de inmediato.

Configuramos el monitoreo de todos nuestros servidores en solo unas pocas horas. El dashboard es claro, potente y realmente agradable de usar.

Desplegamos Bleemeo en toda nuestra infraestructura de servidores en solo unas pocas horas. El monitoreo de disponibilidad ahora nos alerta instantáneamente cuando un servicio tiene un problema.

Nuestra pila de Prometheus + Grafana se había convertido en un proyecto de mantenimiento. Con Bleemeo desplegamos el agente en minutos y finalmente nos enfocamos en usar el monitoreo en lugar de mantenerlo.
Después de instalar el agente, Bleemeo descubrió automáticamente nuestras bases de datos, contenedores y servicios. En una hora teníamos visibilidad completa de la infraestructura, sin dashboards ni exporters que construir.
Bleemeo reemplazó varias herramientas de monitoreo con una sola plataforma. Métricas, alertas y logs están ahora en un solo lugar, ahorrando a nuestro equipo un tiempo significativo.
Bleemeo nos dio una visión inmediata de nuestra infraestructura sin la complejidad habitual. En un par de horas teníamos métricas, alertas y dashboards funcionando sin problemas.
Configurar Bleemeo fue sorprendentemente simple. El despliegue del agente tomó minutos y el descubrimiento automático nos ahorró días de configuración.
Gracias a Bleemeo, nuestro equipo ahora detecta problemas antes de que los usuarios los noten. Las alertas son fiables y la interfaz hace que la resolución de problemas sea mucho más rápida.
Migrar a Bleemeo simplificó drásticamente nuestra pila de monitoreo. En lugar de gestionar múltiples herramientas, todo lo que necesitamos está disponible en una sola plataforma.
Centralizar nuestros logs en Bleemeo simplificó drásticamente la resolución de problemas. En lugar de saltar entre herramientas, ahora podemos correlacionar métricas y logs instantáneamente para entender qué está pasando.
Bleemeo hizo que el monitoreo de Kubernetes fuera sorprendentemente fácil. En minutos teníamos visibilidad de nuestros clusters, pods y cargas de trabajo sin tener que construir dashboards complejos nosotros mismos.
Tu SaaS merece algo mejor que cruzar los dedos
Obtén monitorización SaaS completa en 10 minutos. Conoce los problemas antes que tus clientes.
Prueba gratuita de 15 días · Sin tarjeta de crédito · Cancela cuando quieras
Preguntas frecuentes
¿Cuánto tiempo se tarda en empezar a monitorizar mi SaaS?
La mayoría de los equipos pasan de cero a monitorización completa en menos de 10 minutos. Crea una cuenta, ejecuta un comando de instalación por servidor, y los dashboards y alertas se activan automáticamente a medida que se descubren los servicios.
¿Necesito configurar los dashboards manualmente?
No. Bleemeo crea automáticamente dashboards para cada servicio descubierto — bases de datos, servidores web, cachés, brokers de mensajes y más. Obtienes dashboards listos para producción desde el primer minuto sin escribir ninguna configuración.
¿Qué componentes de infraestructura SaaS monitoriza Bleemeo?
Bleemeo monitoriza servidores, contenedores, clústeres Kubernetes, bases de datos (PostgreSQL, MySQL, MongoDB, Redis), servidores web (Nginx, Apache), brokers de mensajes (RabbitMQ, Kafka) y más de 100 servicios adicionales. También proporciona monitorización de disponibilidad y gestión de logs.
¿Puedo monitorizar despliegues multi-región desde un solo dashboard?
Sí. Instala el agente en servidores de cualquier región o proveedor cloud. Todos los datos fluyen al mismo dashboard de Bleemeo, dándote una vista unificada entre AWS, GCP, Azure, on-premise y entornos híbridos.
¿Cómo me ayuda Bleemeo a cumplir mis SLA?
Bleemeo proporciona monitorización de disponibilidad desde 7 ubicaciones globales, alertas en tiempo real y datos históricos de disponibilidad. Puedes rastrear tiempos de respuesta, establecer umbrales alineados con tus objetivos SLA y recibir alertas antes de que ocurran incumplimientos.
¿El agente de monitorización es open source?
Sí. Glouton, el agente de monitorización de Bleemeo, es completamente open source bajo licencia Apache 2.0. Puedes auditar el código, contribuir y verificar exactamente qué datos se recopilan.
¿Qué canales de alerta se soportan?
Bleemeo envía alertas por email, Slack, Microsoft Teams, PagerDuty y webhooks. Puedes configurar diferentes canales para diferentes niveles de severidad, para que los problemas críticos lleguen inmediatamente a los ingenieros de guardia.
¿Puede Bleemeo monitorizar mis endpoints API?
Sí. Configura monitores HTTP para cualquier URL — endpoints API, health checks, webhooks. Bleemeo verifica disponibilidad y tiempo de respuesta desde múltiples ubicaciones globales cada 60 segundos y te alerta si el rendimiento se degrada o los endpoints caen.
¿Cómo funciona la tarificación para un SaaS en crecimiento?
Bleemeo cobra por servidor por mes sin compromiso a largo plazo. A medida que escalas, añade agentes en nuevos servidores con un solo comando. Reduce simplemente eliminándolos. Solo pagas por lo que monitorizas activamente. Ver detalles de precios.
¿Puedo integrar Bleemeo con mis herramientas existentes?
Sí. Bleemeo expone una interfaz de consulta compatible con PromQL, para que puedas mantener tus dashboards de Grafana existentes. También se integra con Slack, Teams, PagerDuty y proporciona una API REST para integraciones personalizadas en tus pipelines CI/CD.