Monitora il tuo prodotto SaaS in 10 minuti
Ogni minuto di downtime erode la fiducia dei clienti e i ricavi. Ottieni piena visibilità su server, database, API e uptime — prima che i tuoi clienti notino un problema.
15 giorni di prova gratuita · Nessuna carta di credito richiesta · Pronto per la produzione in minuti
Quando il tuo SaaS va offline, la fiducia scompare
Il downtime è devastante
Il costo medio del downtime IT è di $5.600 al minuto per le aziende di medie dimensioni. Per un prodotto SaaS, non si tratta solo di ricavi persi — sono clienti che se ne vanno, integrazioni interrotte e penali SLA. Un singolo outage prolungato può annullare mesi di acquisizione clienti.
Il monitoraggio fai-da-te è un progetto che non finirai mai
Configurare Prometheus, Grafana, Alertmanager e lo storage a lungo termine richiede settimane. Poi devi mantenerlo, aggiornarlo e scrivere regole di allarme per ogni servizio. È tempo di sviluppo non speso a costruire il tuo prodotto.
Bleemeo: monitoraggio in produzione senza il progetto
Bleemeo ti offre un monitoraggio infrastrutturale completo — server, database, web server, cache, code di messaggi e uptime — in 10 minuti, con zero configurazione. Scopri i problemi prima che i tuoi clienti aprano un ticket di supporto.
Si adatta alla tua architettura
Che tu stia eseguendo un monolite su un singolo server o un'architettura a microservizi su più cloud, Bleemeo si adatta al tuo stack automaticamente. Ottieni metriche server, prestazioni database, efficienza cache e monitoraggio uptime esterno — tutto da un agente e una dashboard, con avvisi che funzionano subito.
3 passaggi per un monitoraggio SaaS completo
Il tuo team di sviluppo può configurare tutto durante una pausa caffè.
Installa l'agente sui tuoi server
Un comando per server. L'agente Glouton di Bleemeo scopre automaticamente l'intero stack SaaS: web server, runtime applicativo, database, cache, broker di messaggi e motore di ricerca.
wget -qO- 'https://get.bleemeo.com?accountId=...' Esegui questo su ogni server del tuo stack. L'agente rileva tutto ciò che gira sulla macchina — nessun file di configurazione da scrivere.
Stack SaaS rilevati automaticamente
Perché l'auto-discovery è importante per il SaaS
Gli stack SaaS evolvono velocemente — nuovi servizi vengono deployati, i container vengono sostituiti, le dipendenze cambiano. Configurare manualmente il monitoraggio per ogni componente significa ore di YAML e il rischio costante di punti ciechi. Bleemeo rileva ogni servizio sulla tua macchina in pochi secondi, così nulla sfugge — anche quando la tua architettura evolve.
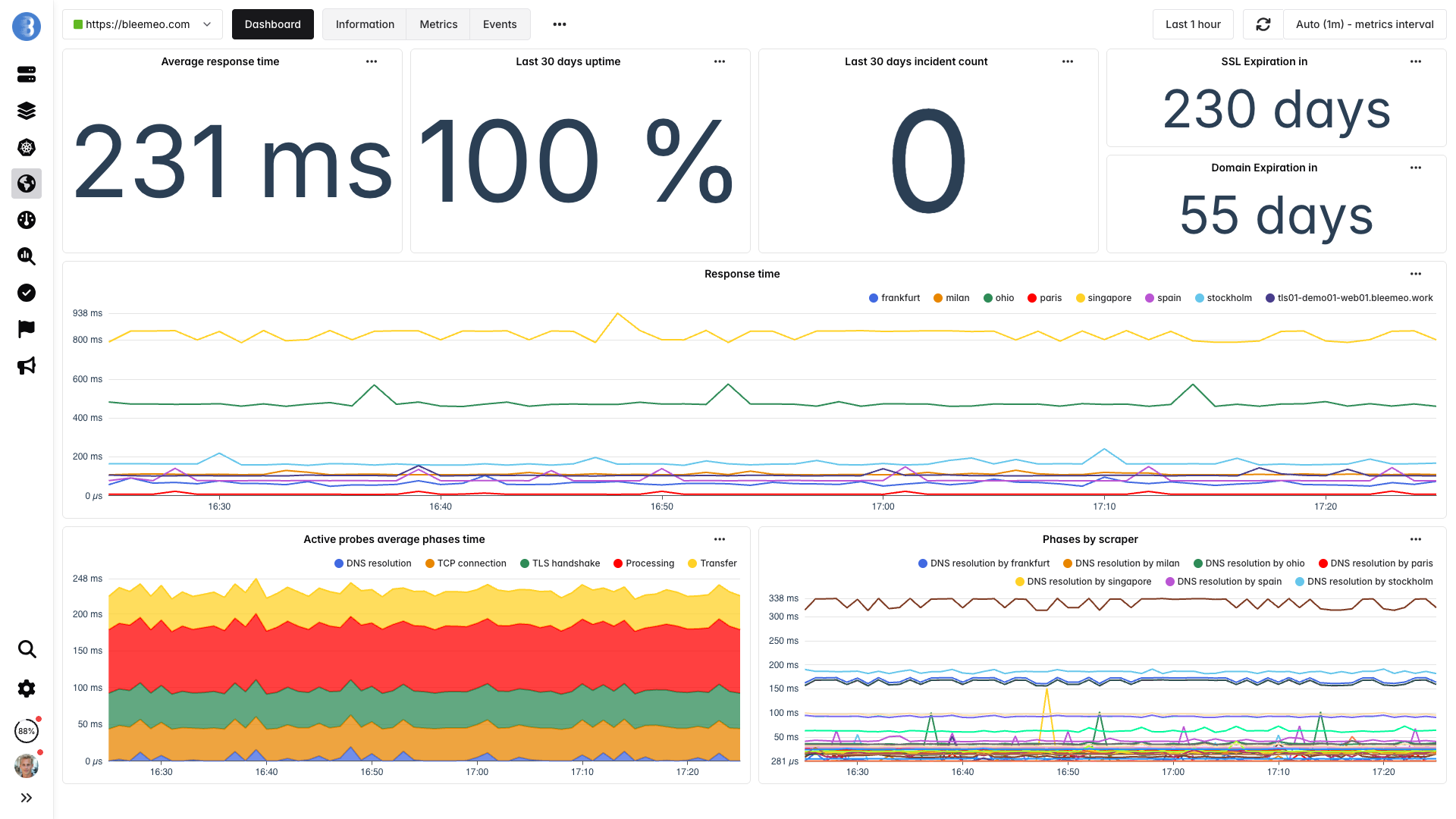
Aggiungi monitor uptime per i tuoi endpoint critici
Monitora i tuoi URL più importanti da 7 posizioni globali. Bleemeo verifica disponibilità, tempo di risposta, scadenza certificati SSL e validazione dei contenuti ogni 60 secondi.
- Endpoint API — la spina dorsale del tuo prodotto
- Applicazione web — pagina login, dashboard, flussi chiave
- Ricevitori webhook — affidabilità delle integrazioni
- Pagina di stato — ciò che vedono i tuoi clienti
- Pannello admin — la tua spina dorsale operativa
Per saperne di più: Funzionalità monitoraggio uptime
Perché il monitoraggio esterno è critico per il SaaS
I tuoi server potrebbero mostrare tutto verde, ma un problema DNS, una configurazione CDN errata o la scadenza di un certificato possono comunque impedire ai clienti di raggiungere il tuo prodotto. Il monitoraggio da 7 posizioni globali vede ciò che vedono i tuoi clienti — e individua problemi che i controlli di salute interni non rilevano.
Ricevi avvisi prima che i tuoi clienti se ne accorgano
Le regole di avviso predefinite sono attive immediatamente. Instrada le notifiche dove lavora il tuo team — che siano le 14:00 o le 2:00 di notte.
Problemi server
- Utilizzo CPU elevato
- Pressione di memoria
- Disco pieno
Problemi database
- Query lente
- Esaurimento pool connessioni
- Ritardo di replica
Errori web server
- Picco errori 5xx
- Tempo di risposta elevato
- Scadenza SSL
Cache & uptime
- Pressione memoria Redis/Memcached
- Downtime da qualsiasi posizione
- Arretrato coda messaggi
- Slack e Microsoft Teams
- Email (abilitata di default)
- PagerDuty, OpsGenie, VictorOps
- SMS tramite Twilio o MessageBird
- Webhook per integrazioni personalizzate
Perché i valori predefiniti intelligenti battono la configurazione manuale
Scrivere regole di avviso efficaci richiede una conoscenza approfondita delle modalità di guasto di ogni servizio. Bleemeo include soglie testate in battaglia per ogni servizio auto-rilevato — così sei protetto dal primo minuto, senza spendere ore a regolare condizioni di allarme che potrebbero comunque non rilevare il problema che conta davvero.
Cosa monitori nel tuo stack SaaS
Ogni livello della tua infrastruttura, coperto automaticamente.
Un prodotto SaaS è una catena — ed è forte solo quanto il suo anello più debole. Una query database lenta rallenta la tua API. Un disco pieno blocca i tuoi worker process. Un picco di eviction della cache martella il tuo database durante un'impennata di traffico. Bleemeo monitora ogni livello così puoi vedere dove iniziano i problemi, non solo dove si manifestano.
Livello rivolto al cliente
Questo è ciò che i tuoi clienti sperimentano. Se la tua API è lenta o la tua pagina di login è offline, devi saperlo immediatamente — non da un ticket di supporto un'ora dopo.
- Uptime da 7 posizioni globali
- Tracciamento tempi di risposta
- Monitoraggio certificati SSL
Livello web / applicativo
Il tuo web server e il runtime applicativo gestiscono ogni richiesta. Un worker pool mal configurato o un memory leak qui impatta ogni utente del tuo prodotto.
Livello dati
- Prestazioni query MySQL / PostgreSQL
- Hit rate e memoria Redis / Memcached
- Profondità coda e throughput RabbitMQ / Kafka
Livello infrastruttura
- CPU, memoria, disco, rete per server
- Container Docker e metriche pod Kubernetes
- Raccolta e ricerca log
Il costo di non monitorare
Downtime = Ricavi e fiducia persi
Per un SaaS con $50K MRR, anche l'1% di downtime costa $500/mese in crediti SLA diretti — senza contare i clienti che silenziosamente se ne vanno. Bleemeo rileva le interruzioni in meno di 60 secondi da 7 posizioni globali, così puoi iniziare a risolvere in minuti, non in ore.
API lente = Clienti persi
Le ricerche mostrano che il 53% degli utenti abbandona un servizio se impiega più di 3 secondi a rispondere. Traccia i tempi di risposta su tutti i tuoi endpoint API, app web e webhook — e ricevi avvisi prima che la latenza peggiori al punto in cui i clienti cercano alternative.
Costi di monitoraggio < un singolo incidente
Monitorare 10 server con Bleemeo costa €109,90/mese. È meno del tempo di sviluppo sprecato nel debug di un singolo outage alla cieca. Prova il calcolatore dei costi.
Progettato per team SaaS in crescita
Bleemeo è progettato per team di sviluppo che devono rilasciare funzionalità, non mantenere infrastruttura di monitoraggio. Non c'è Prometheus da configurare, nessuna dashboard Grafana da costruire, nessuna regola di allarme da scrivere. Il tuo team può configurarlo durante una pausa caffè e tornare a costruire il prodotto per cui i tuoi clienti pagano.
La maggior parte delle aziende SaaS ha team di sviluppo snelli. Le stesse persone che costruiscono funzionalità gestiscono anche l'infrastruttura, i deployment e rispondono agli incidenti. Bleemeo elimina completamente il monitoraggio da quel carico — ottieni osservabilità di livello produzione senza assumere un SRE dedicato o spendere settimane su strumenti che non sono il tuo core business.
Scopri come funzionaScelto da team SaaS in produzione
Ingegneri e CTO si affidano a Bleemeo per monitorare la loro infrastruttura
Durante una breve pausa pranzo abbiamo installato Bleemeo, creato una metrica personalizzata, testato gli alert ed eravamo pronti per la produzione. La velocità di deployment è notevole.

Il supporto di Bleemeo è semplicemente leggendario: rapido, competente e sempre presente quando ne abbiamo bisogno.
Il deployment di Bleemeo è stato incredibilmente veloce. In circa un'ora lo abbiamo distribuito su più di 100 server e abbiamo immediatamente ottenuto piena visibilità sulla nostra infrastruttura.

Abbiamo configurato il monitoraggio di tutti i nostri server in poche ore. La dashboard è chiara, potente e davvero piacevole da usare.

Abbiamo distribuito Bleemeo su tutta la nostra infrastruttura server in poche ore. Il monitoraggio dell'uptime ci avvisa istantaneamente ogni volta che un servizio riscontra un problema.

Il nostro stack Prometheus + Grafana era diventato un progetto di manutenzione. Con Bleemeo abbiamo distribuito l'agente in pochi minuti e finalmente ci siamo concentrati sull'uso del monitoraggio anziché sulla sua manutenzione.
Dopo aver installato l'agente, Bleemeo ha scoperto automaticamente i nostri database, container e servizi. In un'ora avevamo piena visibilità sull'infrastruttura — senza dashboard o exporter da costruire.
Bleemeo ha sostituito diversi strumenti di monitoraggio con un'unica piattaforma. Metriche, alert e log sono ora in un unico posto, facendo risparmiare al nostro team un tempo significativo.
Bleemeo ci ha dato una visibilità immediata sulla nostra infrastruttura senza la complessità abituale. In un paio d'ore avevamo metriche, alert e dashboard perfettamente funzionanti.
Configurare Bleemeo è stato sorprendentemente semplice. Il deployment dell'agente ha richiesto pochi minuti e la scoperta automatica ci ha fatto risparmiare giorni di configurazione.
Grazie a Bleemeo, il nostro team ora rileva i problemi prima che gli utenti li notino. Gli alert sono affidabili e l'interfaccia rende la risoluzione dei problemi molto più rapida.
Il passaggio a Bleemeo ha semplificato drasticamente il nostro stack di monitoraggio. Invece di gestire più strumenti, tutto ciò di cui abbiamo bisogno è disponibile in un'unica piattaforma.
Centralizzare i nostri log in Bleemeo ha semplificato drasticamente la risoluzione dei problemi. Invece di saltare tra gli strumenti, ora possiamo correlare metriche e log istantaneamente per capire cosa sta succedendo.
Bleemeo ha reso il monitoraggio di Kubernetes sorprendentemente facile. In pochi minuti avevamo visibilità sui nostri cluster, pod e workload senza dover costruire dashboard complessi da soli.
Il tuo SaaS merita di meglio che sperare per il meglio
Ottieni un monitoraggio SaaS completo in 10 minuti. Scopri i problemi prima dei tuoi clienti.
15 giorni di prova gratuita · Nessuna carta di credito richiesta · Cancella quando vuoi
Domande frequenti
Quanto tempo ci vuole per iniziare a monitorare il mio SaaS?
La maggior parte dei team passa da zero al monitoraggio completo in meno di 10 minuti. Crea un account, esegui un comando di installazione per server, e dashboard e avvisi si attivano automaticamente man mano che i servizi vengono scoperti.
Devo configurare le dashboard manualmente?
No. Bleemeo crea automaticamente dashboard per ogni servizio scoperto — database, web server, cache, broker di messaggi e altro. Ottieni dashboard pronte per la produzione dal primo minuto senza scrivere alcuna configurazione.
Quali componenti dell'infrastruttura SaaS monitora Bleemeo?
Bleemeo monitora server, container, cluster Kubernetes, database (PostgreSQL, MySQL, MongoDB, Redis), web server (Nginx, Apache), broker di messaggi (RabbitMQ, Kafka) e oltre 100 altri servizi. Fornisce anche monitoraggio uptime e gestione dei log.
Posso monitorare deployment multi-regione da un'unica dashboard?
Sì. Installa l'agente sui server in qualsiasi regione o provider cloud. Tutti i dati confluiscono nella stessa dashboard Bleemeo, offrendoti una vista unificata su AWS, GCP, Azure, on-premise e ambienti ibridi.
Come mi aiuta Bleemeo a rispettare i miei SLA?
Bleemeo fornisce monitoraggio uptime da 7 posizioni globali, avvisi in tempo reale e dati storici di disponibilità. Puoi tracciare i tempi di risposta, impostare soglie allineate ai tuoi obiettivi SLA e ricevere avvisi prima che si verifichino violazioni.
L'agente di monitoraggio è open source?
Sì. Glouton, l'agente di monitoraggio di Bleemeo, è completamente open source con licenza Apache 2.0. Puoi verificare il codice, contribuire e controllare esattamente quali dati vengono raccolti.
Quali canali di avviso sono supportati?
Bleemeo invia avvisi tramite email, Slack, Microsoft Teams, PagerDuty e webhook. Puoi configurare canali diversi per diversi livelli di gravità, in modo che i problemi critici raggiungano immediatamente gli ingegneri di turno.
Bleemeo può monitorare i miei endpoint API?
Sì. Configura monitor HTTP per qualsiasi URL — endpoint API, health check, webhook. Bleemeo verifica disponibilità e tempo di risposta da più posizioni globali ogni 60 secondi e ti avvisa se le prestazioni peggiorano o gli endpoint vanno offline.
Come funziona il pricing per un SaaS in crescita?
Bleemeo addebita per server al mese senza impegno a lungo termine. Man mano che cresci, aggiungi agenti ai nuovi server con un singolo comando. Riduci semplicemente rimuovendoli. Paghi solo ciò che monitori attivamente. Vedi i dettagli dei prezzi.
Posso integrare Bleemeo con i miei strumenti esistenti?
Sì. Bleemeo espone un'interfaccia di query compatibile con PromQL, permettendoti di mantenere le tue dashboard Grafana esistenti. Si integra anche con Slack, Teams, PagerDuty e fornisce un'API REST per integrazioni personalizzate nelle tue pipeline CI/CD.