Überwachen Sie Ihr SaaS-Produkt in 10 Minuten
Jede Minute Downtime untergräbt das Vertrauen der Kunden und den Umsatz. Erhalten Sie volle Transparenz über Server, Datenbanken, APIs und Uptime — bevor Ihre Kunden ein Problem bemerken.
15 Tage kostenlos testen · Keine Kreditkarte erforderlich · Produktionsbereit in Minuten
Wenn Ihr SaaS ausfällt, verschwindet das Vertrauen
Downtime ist verheerend
Die durchschnittlichen Kosten von IT-Downtime betragen $5.600 pro Minute für mittelständische Unternehmen. Für ein SaaS-Produkt geht es nicht nur um verlorenen Umsatz — es sind abwandernde Kunden, kaputte Integrationen und SLA-Strafen. Ein einziger längerer Ausfall kann Monate der Kundenakquise zunichtemachen.
DIY-Monitoring ist ein Projekt, das Sie nie fertigstellen werden
Prometheus, Grafana, Alertmanager und Langzeitspeicher einzurichten dauert Wochen. Dann müssen Sie es pflegen, aktualisieren und Alarmregeln für jeden Dienst schreiben. Das ist Entwicklungszeit, die nicht für den Aufbau Ihres Produkts verwendet wird.
Bleemeo: Produktionsmonitoring ohne das Projekt
Bleemeo bietet Ihnen vollständiges Infrastruktur-Monitoring — Server, Datenbanken, Webserver, Caches, Message Queues und Uptime — in 10 Minuten, ohne jede Konfiguration. Erfahren Sie von Problemen, bevor Ihre Kunden ein Support-Ticket öffnen.
Skaliert mit Ihrer Architektur
Ob Sie einen Monolithen auf einem einzelnen Server oder eine Microservices-Architektur über mehrere Clouds betreiben — Bleemeo passt sich automatisch an Ihren Stack an. Sie erhalten Server-Metriken, Datenbank-Performance, Cache-Effizienz und externes Uptime-Monitoring — alles von einem Agenten und einem Dashboard, mit Alarmen, die sofort funktionieren.
3 Schritte zur vollständigen SaaS-Überwachung
Ihr Entwicklungsteam kann das während einer Kaffeepause einrichten.
Installieren Sie den Agenten auf Ihren Servern
Ein Befehl pro Server. Der Glouton-Agent von Bleemeo erkennt automatisch Ihren gesamten SaaS-Stack: Webserver, Anwendungsruntime, Datenbank, Cache, Message Broker und Suchmaschine.
wget -qO- 'https://get.bleemeo.com?accountId=...' Führen Sie dies auf jedem Server in Ihrem Stack aus. Der Agent erkennt alles, was auf der Maschine läuft — keine Konfigurationsdatei zu schreiben.
Automatisch erkannte SaaS-Stacks
Warum Auto-Discovery für SaaS wichtig ist
SaaS-Stacks entwickeln sich schnell — neue Dienste werden bereitgestellt, Container werden ersetzt, Abhängigkeiten ändern sich. Die manuelle Konfiguration der Überwachung für jede Komponente bedeutet Stunden von YAML und das ständige Risiko blinder Flecken. Bleemeo erkennt jeden Dienst auf Ihrer Maschine in Sekunden, damit nichts übersehen wird — auch wenn sich Ihre Architektur weiterentwickelt.
Fügen Sie Uptime-Monitore für Ihre kritischen Endpunkte hinzu
Überwachen Sie Ihre wichtigsten URLs von 7 globalen Standorten. Bleemeo prüft Verfügbarkeit, Antwortzeit, SSL-Zertifikat-Ablauf und Inhaltsvalidierung alle 60 Sekunden.
- API-Endpunkte — das Rückgrat Ihres Produkts
- Webanwendung — Login-Seite, Dashboard, wichtige Abläufe
- Webhook-Empfänger — Zuverlässigkeit der Integrationen
- Status-Seite — was Ihre Kunden sehen
- Admin-Panel — Ihr operatives Rückgrat
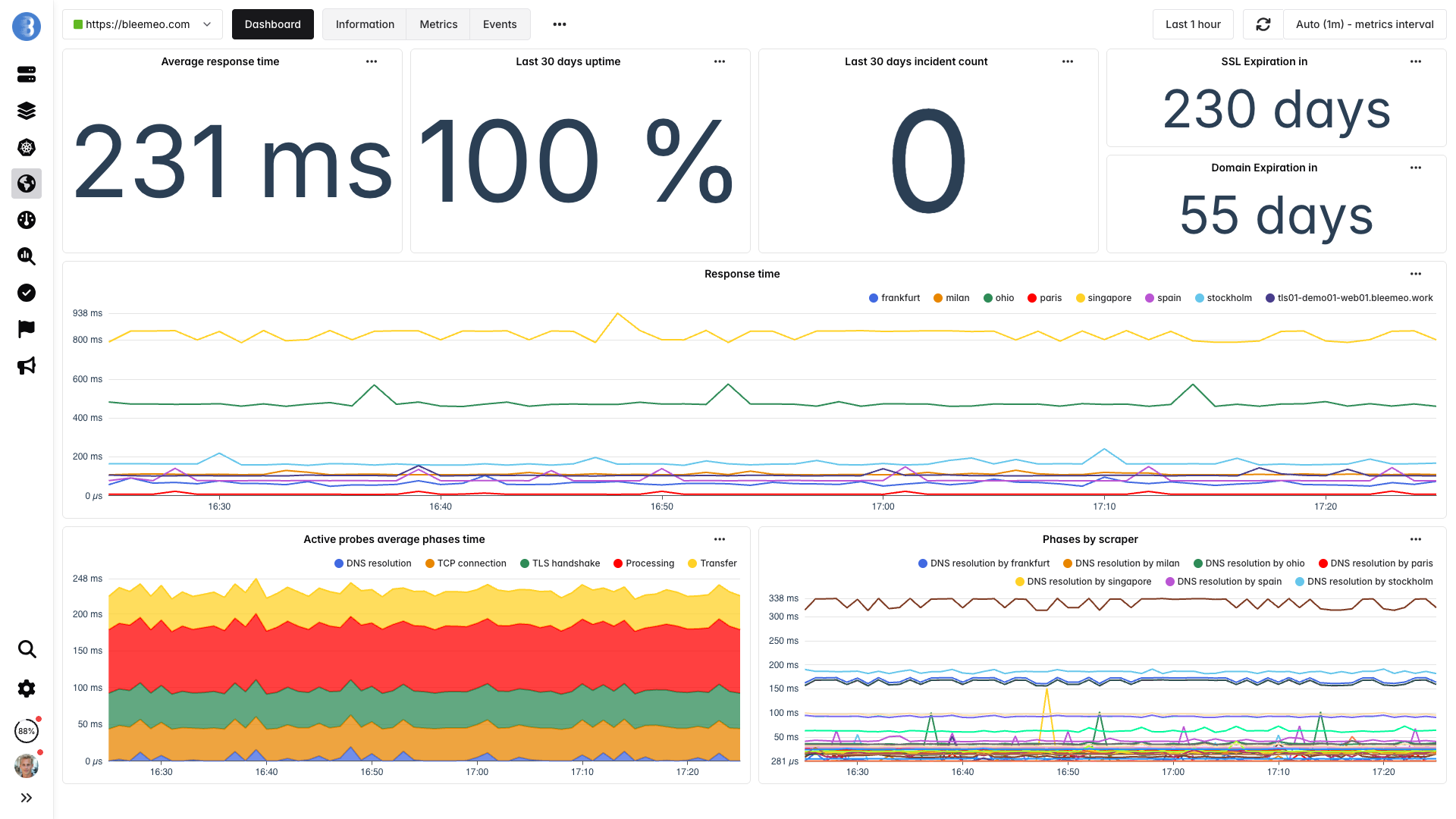
Mehr erfahren: Uptime-Monitoring-Funktionen
Warum externe Überwachung für SaaS kritisch ist
Ihre Server zeigen möglicherweise überall grün, aber ein DNS-Problem, eine CDN-Fehlkonfiguration oder ein Zertifikatsablauf kann Kunden dennoch daran hindern, Ihr Produkt zu erreichen. Die Überwachung von 7 globalen Standorten sieht, was Ihre Kunden sehen — und erkennt Probleme, die interne Health Checks übersehen.
Werden Sie gewarnt, bevor Ihre Kunden es bemerken
Standard-Alarmregeln sind sofort aktiv. Leiten Sie Benachrichtigungen dorthin, wo Ihr Team arbeitet — ob um 14:00 oder um 2:00 Uhr nachts.
Server-Probleme
- Hohe CPU-Auslastung
- Speicherdruck
- Festplatte voll
Datenbank-Probleme
- Langsame Abfragen
- Connection-Pool-Erschöpfung
- Replikationsverzögerung
Webserver-Fehler
- 5xx-Fehler-Spitze
- Hohe Antwortzeit
- SSL-Ablauf
Cache & Uptime
- Redis/Memcached-Speicherdruck
- Downtime von jedem Standort
- Message-Queue-Rückstau
- Slack und Microsoft Teams
- E-Mail (standardmäßig aktiviert)
- PagerDuty, OpsGenie, VictorOps
- SMS über Twilio oder MessageBird
- Webhooks für benutzerdefinierte Integrationen
Warum intelligente Standardwerte manuelle Konfiguration schlagen
Effektive Alarmregeln zu schreiben erfordert tiefes Wissen über die Fehlermodi jedes Dienstes. Bleemeo liefert kampferprobte Schwellenwerte für jeden automatisch erkannten Dienst — so sind Sie ab der ersten Minute geschützt, ohne Stunden mit der Feinabstimmung von Alarmbedingungen zu verbringen, die möglicherweise trotzdem das Problem übersehen, das wirklich zählt.
Was Sie in Ihrem SaaS-Stack überwachen
Jede Schicht Ihrer Infrastruktur, automatisch abgedeckt.
Ein SaaS-Produkt ist eine Kette — und sie ist nur so stark wie ihr schwächstes Glied. Eine langsame Datenbankabfrage lässt Ihre API kriechen. Eine volle Festplatte bringt Ihre Worker-Prozesse zum Absturz. Ein Cache-Eviction-Spike hämmert auf Ihre Datenbank während eines Traffic-Anstiegs. Bleemeo überwacht jede Schicht, damit Sie sehen können, wo Probleme beginnen, nicht nur wo sie auftauchen.
Kundenorientierte Schicht
Das ist es, was Ihre Kunden erleben. Wenn Ihre API langsam oder Ihre Login-Seite offline ist, müssen Sie das sofort wissen — nicht durch ein Support-Ticket eine Stunde später.
- Uptime von 7 globalen Standorten
- Antwortzeit-Tracking
- SSL-Zertifikat-Überwachung
Web-/Anwendungsschicht
Ihr Webserver und Ihre Anwendungsruntime verarbeiten jede Anfrage. Ein falsch konfigurierter Worker-Pool oder ein Speicherleck hier betrifft jeden Benutzer Ihres Produkts.
Datenschicht
- MySQL / PostgreSQL Abfrage-Performance
- Redis / Memcached Hit-Rate & Speicher
- RabbitMQ / Kafka Queue-Tiefe & Durchsatz
Infrastrukturschicht
- CPU, Speicher, Festplatte, Netzwerk pro Server
- Docker-Container und Kubernetes-Pod-Metriken
- Log-Sammlung und -Suche
Die Kosten des Nicht-Überwachens
Downtime = Verlorener Umsatz & Vertrauen
Für ein SaaS mit $50K MRR kosten selbst 1% Downtime $500/Monat an direkten SLA-Gutschriften — ohne die Kunden zu zählen, die still abwandern. Bleemeo erkennt Ausfälle in unter 60 Sekunden von 7 globalen Standorten, damit Sie in Minuten mit der Behebung beginnen können, nicht in Stunden.
Langsame APIs = Verlorene Kunden
Studien zeigen, dass 53% der Nutzer einen Dienst verlassen, wenn er mehr als 3 Sekunden zum Antworten braucht. Verfolgen Sie Antwortzeiten über Ihre API-Endpunkte, Web-App und Webhooks — und werden Sie gewarnt, bevor die Latenz so weit steigt, dass Kunden nach Alternativen suchen.
Monitoring-Kosten < ein einziger Vorfall
Die Überwachung von 10 Servern mit Bleemeo kostet €109,90/Monat. Das ist weniger als die verschwendete Entwicklungszeit beim Debugging eines einzigen blinden Ausfalls. Probieren Sie den Kostenrechner.
Entwickelt für wachsende SaaS-Teams
Bleemeo ist für Entwicklungsteams gebaut, die Features liefern müssen, nicht Monitoring-Infrastruktur pflegen. Es gibt kein Prometheus zu konfigurieren, keine Grafana-Dashboards zu bauen, keine Alarmregeln zu schreiben. Ihr Team kann es während einer Kaffeepause einrichten und sich wieder dem Produkt widmen, für das Ihre Kunden bezahlen.
Die meisten SaaS-Unternehmen haben schlanke Entwicklungsteams. Dieselben Leute, die Produktfeatures bauen, verwalten auch die Infrastruktur, kümmern sich um Deployments und reagieren auf Vorfälle. Bleemeo nimmt das Monitoring komplett von diesem Teller — Sie erhalten Observability auf Produktionsniveau, ohne einen dedizierten SRE einzustellen oder Wochen mit Tooling zu verbringen, das nicht Ihr Kerngeschäft ist.
So funktioniert esVertraut von SaaS-Teams in der Produktion
Ingenieure und CTOs vertrauen auf Bleemeo für ihr Infrastruktur-Monitoring
Während einer kurzen Mittagspause haben wir Bleemeo installiert, eine benutzerdefinierte Metrik erstellt, Alerts getestet und waren produktionsbereit. Die Geschwindigkeit der Bereitstellung ist bemerkenswert.

Der Bleemeo-Support ist schlicht legendär — schnell, kompetent und immer da, wenn wir ihn brauchen.
Bleemeo war unglaublich schnell einzurichten. In etwa einer Stunde haben wir es auf über 100 Servern ausgerollt und sofort volle Sicht auf unsere Infrastruktur erhalten.

Wir haben das Monitoring für alle unsere Server in nur wenigen Stunden eingerichtet. Das Dashboard ist übersichtlich, leistungsstark und macht wirklich Freude in der Nutzung.

Wir haben Bleemeo in nur wenigen Stunden auf unserer gesamten Server-Infrastruktur ausgerollt. Das Uptime-Monitoring benachrichtigt uns jetzt sofort, wenn ein Dienst ein Problem hat.

Unser Prometheus + Grafana-Stack war zu einem Wartungsprojekt geworden. Mit Bleemeo haben wir den Agenten in Minuten ausgerollt und uns endlich auf die Nutzung des Monitorings statt auf dessen Wartung konzentriert.
Nach der Installation des Agenten hat Bleemeo automatisch unsere Datenbanken, Container und Services erkannt. Innerhalb einer Stunde hatten wir volle Infrastruktur-Sichtbarkeit — ohne Dashboards oder Exporter bauen zu müssen.
Bleemeo hat mehrere Monitoring-Tools durch eine einzige Plattform ersetzt. Metriken, Alerts und Logs sind jetzt an einem Ort, was unserem Team erheblich Zeit spart.
Bleemeo gab uns sofortigen Einblick in unsere Infrastruktur ohne die übliche Komplexität. Innerhalb weniger Stunden liefen Metriken, Alerts und Dashboards reibungslos.
Die Einrichtung von Bleemeo war erfrischend einfach. Das Agent-Deployment dauerte Minuten und die automatische Erkennung ersparte uns Tage an Konfiguration.
Dank Bleemeo erkennt unser Team Probleme jetzt, bevor unsere Nutzer sie bemerken. Die Alerting-Funktion ist zuverlässig und die Oberfläche macht die Fehlersuche deutlich schneller.
Der Wechsel zu Bleemeo hat unseren Monitoring-Stack dramatisch vereinfacht. Statt mehrere Tools zu verwalten, ist alles, was wir brauchen, auf einer einzigen Plattform verfügbar.
Die Zentralisierung unserer Logs in Bleemeo hat die Fehlersuche drastisch vereinfacht. Statt zwischen Tools zu wechseln, können wir jetzt Metriken und Logs sofort korrelieren, um zu verstehen, was passiert.
Bleemeo hat das Kubernetes-Monitoring überraschend einfach gemacht. Innerhalb von Minuten hatten wir Einblick in unsere Cluster, Pods und Workloads, ohne komplexe Dashboards selbst bauen zu müssen.
Ihr SaaS verdient Besseres als auf das Beste zu hoffen
Erhalten Sie vollständiges SaaS-Monitoring in 10 Minuten. Erfahren Sie von Problemen, bevor Ihre Kunden es tun.
15 Tage kostenlos testen · Keine Kreditkarte erforderlich · Jederzeit kündbar
Häufig gestellte Fragen
Wie lange dauert es, mein SaaS zu überwachen?
Die meisten Teams gehen in unter 10 Minuten von null zur vollständigen Überwachung. Erstellen Sie ein Konto, führen Sie einen Installationsbefehl pro Server aus, und Dashboards und Alarme aktivieren sich automatisch, sobald Dienste erkannt werden.
Muss ich Dashboards manuell konfigurieren?
Nein. Bleemeo erstellt automatisch Dashboards für jeden erkannten Dienst — Datenbanken, Webserver, Caches, Message Broker und mehr. Sie erhalten produktionsfertige Dashboards ab der ersten Minute, ohne eine einzige Konfiguration zu schreiben.
Welche SaaS-Infrastrukturkomponenten überwacht Bleemeo?
Bleemeo überwacht Server, Container, Kubernetes-Cluster, Datenbanken (PostgreSQL, MySQL, MongoDB, Redis), Webserver (Nginx, Apache), Message Broker (RabbitMQ, Kafka) und über 100 weitere Dienste. Es bietet auch Uptime-Überwachung und Log-Management.
Kann ich Multi-Region-Deployments von einem einzigen Dashboard überwachen?
Ja. Installieren Sie den Agenten auf Servern in jeder Region oder bei jedem Cloud-Anbieter. Alle Daten fließen in dasselbe Bleemeo-Dashboard und bieten Ihnen eine einheitliche Ansicht über AWS, GCP, Azure, On-Premise und hybride Umgebungen.
Wie hilft mir Bleemeo, meine SLAs einzuhalten?
Bleemeo bietet Uptime-Überwachung von 7 globalen Standorten, Echtzeit-Alarmierung und historische Verfügbarkeitsdaten. Sie können Antwortzeiten verfolgen, Schwellenwerte an Ihren SLA-Zielen ausrichten und gewarnt werden, bevor Verstöße auftreten.
Ist der Überwachungsagent Open Source?
Ja. Glouton, der Überwachungsagent von Bleemeo, ist vollständig Open Source unter der Apache 2.0 Lizenz. Sie können den Code prüfen, beitragen und genau überprüfen, welche Daten gesammelt werden.
Welche Alarmkanäle werden unterstützt?
Bleemeo sendet Alarme per E-Mail, Slack, Microsoft Teams, PagerDuty und Webhooks. Sie können verschiedene Kanäle für verschiedene Schweregrade konfigurieren, damit kritische Probleme sofort die diensthabenden Ingenieure erreichen.
Kann Bleemeo meine API-Endpunkte überwachen?
Ja. Richten Sie HTTP-Monitore für beliebige URLs ein — API-Endpunkte, Health Checks, Webhooks. Bleemeo prüft Verfügbarkeit und Antwortzeit von mehreren globalen Standorten alle 60 Sekunden und warnt Sie, wenn die Leistung nachlässt oder Endpunkte ausfallen.
Wie funktioniert die Preisgestaltung für ein wachsendes SaaS?
Bleemeo berechnet pro Server pro Monat ohne langfristige Bindung. Wenn Sie skalieren, fügen Sie mit einem einzigen Befehl Agenten zu neuen Servern hinzu. Skalieren Sie herunter, indem Sie sie einfach entfernen. Sie zahlen nur für das, was Sie aktiv überwachen. Preisdetails anzeigen.
Kann ich Bleemeo mit meinen bestehenden Tools integrieren?
Ja. Bleemeo bietet eine PromQL-kompatible Abfrageschnittstelle, sodass Sie Ihre bestehenden Grafana-Dashboards behalten können. Es integriert sich auch mit Slack, Teams, PagerDuty und bietet eine REST-API für benutzerdefinierte Integrationen in Ihre CI/CD-Pipelines.