Monitora il tuo cluster Kubernetes in 10 minuti
Un chart Helm. Zero configurazione. Ottieni visibilità completa su cluster, nodi, pod e container — con scoperta automatica che tiene il passo con i tuoi deployment.
Prova gratuita di 15 giorni · Nessuna carta di credito richiesta · Compatibile con EKS, GKE, AKS & autogestito
Il monitoring Kubernetes non dovrebbe essere così difficile
La trappola di Prometheus
La maggior parte dei team inizia con Prometheus, Grafana, Alertmanager e una montagna di YAML. Prima che una singola dashboard sia utile, hai passato giorni a scrivere scrape config, recording rule e a costruire dashboard da zero — e questo prima di affrontare storage, alta disponibilità o federazione. Poi serve la retention a lungo termine, così aggiungi Thanos o Mimir — e improvvisamente stai gestendo una piattaforma di monitoring invece di monitorare la tua piattaforma.
I workload effimeri rompono tutto
Kubernetes si muove velocemente. I pod vanno e vengono, i ReplicaSet scalano, i nodi vengono drenati. Le configurazioni di monitoring statiche non riescono a tenere il passo — i target scompaiono, le dashboard diventano obsolete, e gli avvisi si attivano su risorse che non esistono più. Gli strumenti tradizionali richiedono liste di target manuali o scoperta basata su annotazioni che richiede modifiche a ogni manifesto di deployment. Più dinamico è il tuo cluster, più lavoro genera.
L'approccio di Bleemeo
Distribuisci un chart Helm. L'agente Glouton viene eseguito come DaemonSet su ogni nodo, monitora l'API Kubernetes per i cambiamenti e scopre automaticamente ogni pod, container e servizio. Dashboard e avvisi si attivano in secondi — nessun file di configurazione, nessun linguaggio di query, nessuna manutenzione. Quando un pod scala alle 2 di notte, Bleemeo lo rileva istantaneamente. Quando scala giù, i dati obsoleti vengono puliti automaticamente.
3 passi verso un'osservabilità Kubernetes completa
Da zero a monitoring pronto per la produzione in circa 10 minuti.
Distribuisci con Helm
Aggiungi il repository Helm di Bleemeo e installa il chart. L'agente si distribuisce come DaemonSet — un pod per nodo, automaticamente.
helm repo add bleemeo https://packages.bleemeo.com/helm/ helm repo update helm install bleemeo-agent bleemeo/bleemeo-agent \ --set bleemeo.account=YOUR_ACCOUNT_ID \ --set bleemeo.key=YOUR_REGISTRATION_KEY Ottieni le tue credenziali dal tuo account Bleemeo. Nessun'altra configurazione necessaria.
- DaemonSet viene eseguito automaticamente su ogni nodo
- Compatibile con EKS, GKE, AKS, k3s e autogestito
- Leggero — meno di 100 MB di memoria per nodo
- Agente open source (Apache 2.0)
Perché un DaemonSet?
Un DaemonSet garantisce un pod dell'agente per nodo — inclusi i nodi aggiunti successivamente dagli autoscaler. Non devi mai aggiornare il tuo monitoring quando il cluster cresce o si riduce. Confrontalo con l'iniezione sidecar, che richiede modifiche a ogni manifesto di workload e aggiunge overhead a ogni pod.
La scoperta automatica si attiva
Glouton monitora l'API Kubernetes e scopre ogni pod, container e servizio in esecuzione su ogni nodo. Nessuna annotazione, nessun label, nessun ServiceMonitor da scrivere.
- Nodi, pod e container rilevati automaticamente
- Servizi nei pod riconosciuti (MySQL, Redis, Nginx, ecc.)
- Nuovi deployment rilevati in pochi secondi
- Pod terminati puliti — nessun dato obsoleto
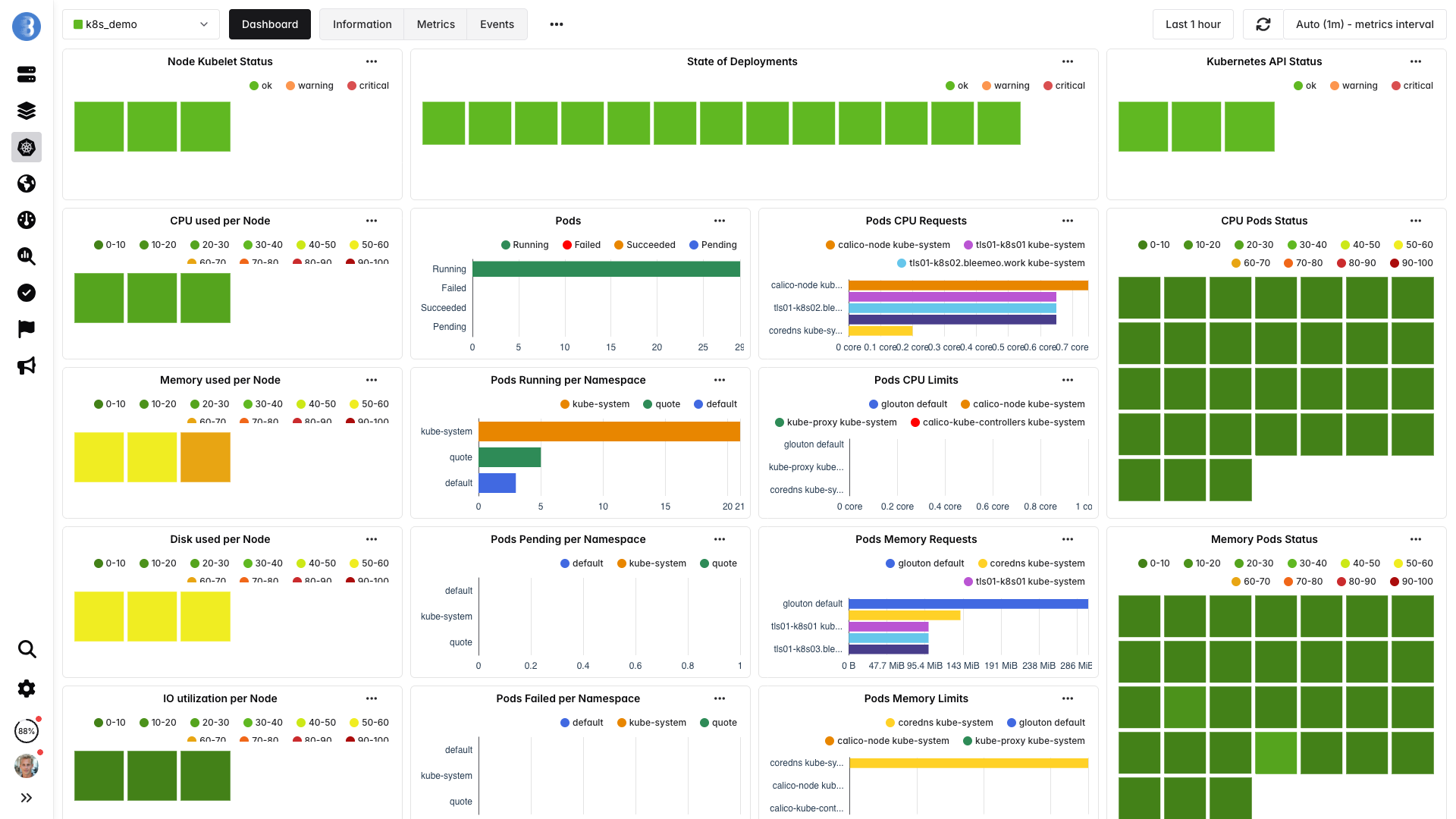
Perché la scoperta automatica è importante in Kubernetes
In un ambiente Kubernetes, i workload vengono costantemente creati, spostati e distrutti. La configurazione manuale del monitoring non riesce a tenere il passo. La scoperta automatica significa che ogni nuovo deployment, replica di StatefulSet o pod CronJob viene monitorato nell'istante in cui si avvia — senza intervento umano.
Dashboard e avvisi — Pronti
Dashboard precostruite e regole di avviso intelligenti si attivano nel momento in cui i servizi vengono scoperti. Stai monitorando in produzione — non stai costruendo una piattaforma di monitoring.
- Panoramica del cluster: conteggio nodi, stato dei pod, utilizzo delle risorse
- Dashboard per pod: CPU, memoria, riavvii, rete
- Esempi di avvisi: crash loop dei pod, CPU alta dei nodi, pressione disco
- Notifiche via Slack, Teams, PagerDuty, email, webhook
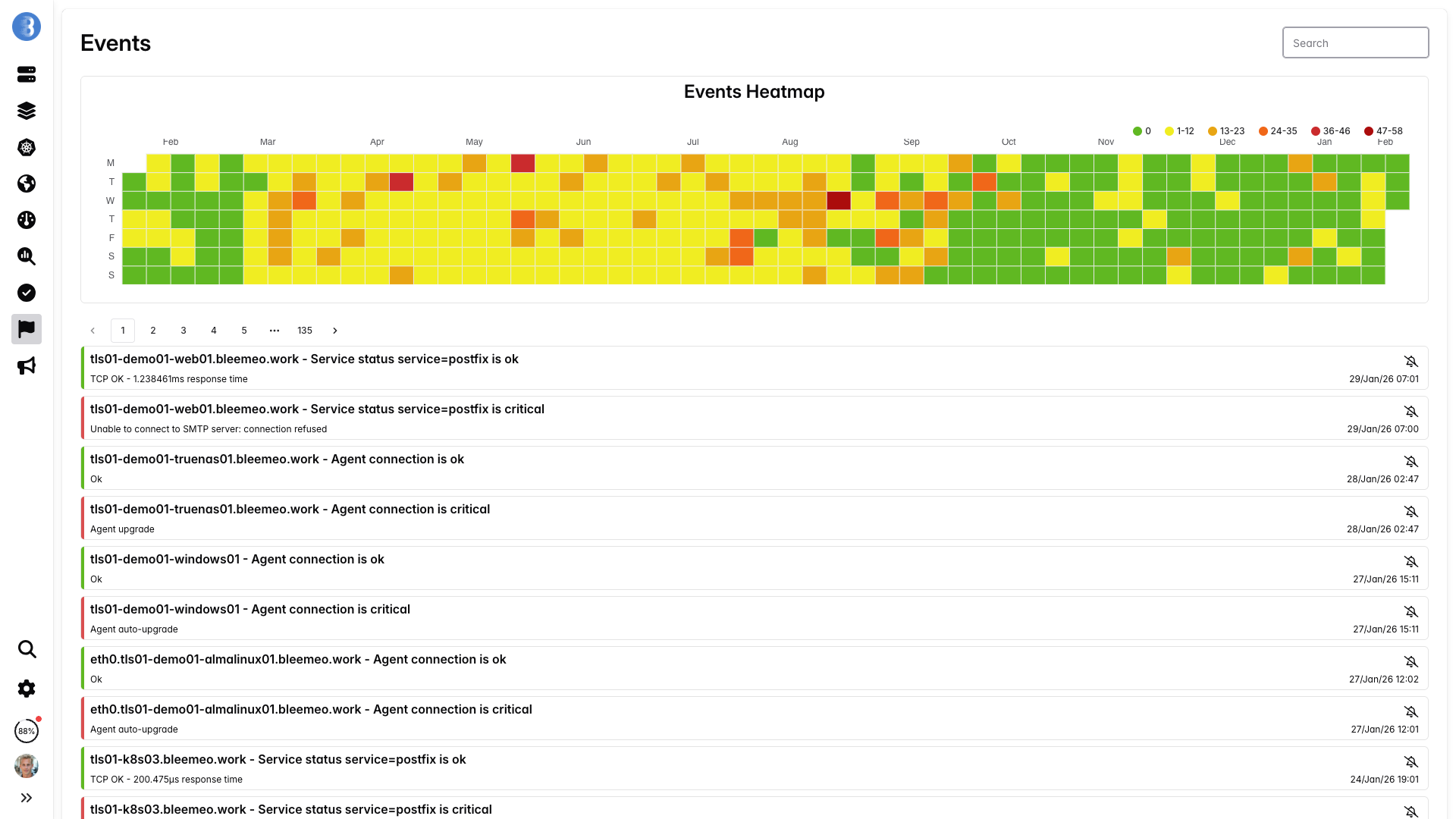
Perché gli avvisi precostruiti ti fanno risparmiare ore
Scrivere buone regole di avviso per Kubernetes da zero è sorprendentemente difficile. Devi gestire le fasi dei pod, gli stati dei container, le condizioni di pressione delle risorse e evitare falsi positivi rumorosi durante i rolling deployment. Bleemeo viene fornito con valori predefiniti collaudati per iniziare con avvisi affidabili dal primo giorno — e puoi sempre personalizzarli in seguito.
Cosa monitori fin da subito
Tutto scoperto automaticamente — nessuna query personalizzata, nessuna configurazione manuale.
Kubernetes introduce più livelli di astrazione — cluster, nodi, pod, container e i servizi in esecuzione al loro interno. Un monitoring efficace significa coprire ogni livello, perché un problema a un livello (ad esempio, pressione disco di un nodo) si propaga in sintomi a un altro (eviction dei pod, errori dell'applicazione). Bleemeo monitora tutti questi livelli fin da subito, per vedere sia la causa radice che l'impatto in un'unica dashboard.
| Livello | Metriche chiave | Avvisi di esempio |
|---|---|---|
| Cluster | Conteggio nodi, capacità pod, allocazione risorse | Nodo del cluster non pronto |
| Nodi | CPU, memoria, disco, rete per nodo | CPU nodo > 90%, pressione disco |
| Pod | Stato, riavvii, CPU/memoria request vs. utilizzo | Crash loop del pod, OOMKilled |
| Container | Throttling CPU, limit di memoria, I/O del filesystem | Memoria container > 90% del limite |
| Servizi | Query MySQL/s, latenza Redis, req/s Nginx, ecc. | Soglie specifiche per servizio |
| Rete | Byte in/out, errori di pacchetto, risoluzione DNS | Alta perdita di pacchetti, errori DNS |
Perché Bleemeo per Kubernetes
Progettato appositamente per ambienti dinamici e containerizzati.
Zero configurazione
Nessuna scrape config, nessun ServiceMonitor, nessuna annotazione. Glouton scopre tutto monitorando l'API Kubernetes — i nuovi deployment vengono monitorati automaticamente.
Visibilità immediata
Le metriche appaiono in pochi secondi dopo il deployment dell'agente. Le dashboard precostruite offrono viste cluster, nodo e pod senza costruire un singolo pannello.
Multi-cluster pronto
Distribuisci lo stesso chart Helm su cluster di staging, produzione e edge. Tutti i dati confluiscono in un'unica interfaccia — senza federazione necessaria.
Avvisi intelligenti
Regole di avviso collaudate per crash loop, OOMKill, pressione sui nodi e altro — attive dal primo minuto. Invia notifiche a Slack, Teams, PagerDuty o email.
Agente leggero
Glouton utilizza meno di 100 MB di memoria per nodo. I limiti delle risorse sono preimpostati nel chart Helm, l'agente non compete mai con i tuoi workload.
Copertura completa dello stack
Dalla capacità a livello di cluster al throttling CPU per container e metriche applicative come query MySQL o latenza Redis — un solo agente copre tutto.
Bleemeo vs. Stack Prometheus fai-da-te
Cosa serve davvero per monitorare Kubernetes
| Aspetto | Prometheus DIY | Bleemeo |
|---|---|---|
| Tempo di configurazione | Giorni o settimane | 10 minuti |
| Configurazione | Scrape config, recording rule, regole di avviso | Zero config — scoperta automatica |
| Dashboard | Costruire da zero in Grafana | Precostruite, auto-attivate |
| Storage & retention | Gestire Thanos/Cortex/Mimir | Completamente gestito, incluso |
| Alta disponibilità | Stack duplicati + federazione | Ridondanza integrata |
| Supporto nuovi servizi | Trovare exporter, aggiungere scrape config | Rilevato in secondi |
| Manutenzione continua | Aggiornamenti versioni, pianificazione capacità | Nessuna — SaaS completamente gestito |
Hai già investito in Prometheus? Bleemeo è progettato per gli utenti Prometheus — mantieni le tue query PromQL e dashboard Grafana, elimina il carico operativo.
Progettato per gli utenti Prometheus
Usi già Prometheus? Bleemeo raccoglie le stesse metriche che conosci e le espone tramite un'interfaccia di query compatibile con PromQL. Mantieni le tue dashboard Grafana e la logica di alerting esistente — senza mantenere l'infrastruttura Prometheus tu stesso.
Scopri Prometheus nel CloudScelto da team che gestiscono Kubernetes in produzione
Ingegneri e CTO si affidano a Bleemeo per monitorare la loro infrastruttura
Durante una breve pausa pranzo abbiamo installato Bleemeo, creato una metrica personalizzata, testato gli alert ed eravamo pronti per la produzione. La velocità di deployment è notevole.

Il supporto di Bleemeo è semplicemente leggendario: rapido, competente e sempre presente quando ne abbiamo bisogno.
Il deployment di Bleemeo è stato incredibilmente veloce. In circa un'ora lo abbiamo distribuito su più di 100 server e abbiamo immediatamente ottenuto piena visibilità sulla nostra infrastruttura.

Abbiamo configurato il monitoraggio di tutti i nostri server in poche ore. La dashboard è chiara, potente e davvero piacevole da usare.

Abbiamo distribuito Bleemeo su tutta la nostra infrastruttura server in poche ore. Il monitoraggio dell'uptime ci avvisa istantaneamente ogni volta che un servizio riscontra un problema.

Il nostro stack Prometheus + Grafana era diventato un progetto di manutenzione. Con Bleemeo abbiamo distribuito l'agente in pochi minuti e finalmente ci siamo concentrati sull'uso del monitoraggio anziché sulla sua manutenzione.
Dopo aver installato l'agente, Bleemeo ha scoperto automaticamente i nostri database, container e servizi. In un'ora avevamo piena visibilità sull'infrastruttura — senza dashboard o exporter da costruire.
Bleemeo ha sostituito diversi strumenti di monitoraggio con un'unica piattaforma. Metriche, alert e log sono ora in un unico posto, facendo risparmiare al nostro team un tempo significativo.
Bleemeo ci ha dato una visibilità immediata sulla nostra infrastruttura senza la complessità abituale. In un paio d'ore avevamo metriche, alert e dashboard perfettamente funzionanti.
Configurare Bleemeo è stato sorprendentemente semplice. Il deployment dell'agente ha richiesto pochi minuti e la scoperta automatica ci ha fatto risparmiare giorni di configurazione.
Grazie a Bleemeo, il nostro team ora rileva i problemi prima che gli utenti li notino. Gli alert sono affidabili e l'interfaccia rende la risoluzione dei problemi molto più rapida.
Il passaggio a Bleemeo ha semplificato drasticamente il nostro stack di monitoraggio. Invece di gestire più strumenti, tutto ciò di cui abbiamo bisogno è disponibile in un'unica piattaforma.
Centralizzare i nostri log in Bleemeo ha semplificato drasticamente la risoluzione dei problemi. Invece di saltare tra gli strumenti, ora possiamo correlare metriche e log istantaneamente per capire cosa sta succedendo.
Bleemeo ha reso il monitoraggio di Kubernetes sorprendentemente facile. In pochi minuti avevamo visibilità sui nostri cluster, pod e workload senza dover costruire dashboard complessi da soli.
Pronto a monitorare Kubernetes in 10 minuti?
Un chart Helm. Osservabilità completa. Nessuna manutenzione. Inizia la tua prova gratuita oggi.
Prova gratuita di 15 giorni · Nessuna carta di credito richiesta · Cancella in qualsiasi momento
Domande frequenti
Bleemeo funziona con servizi Kubernetes gestiti come EKS, GKE e AKS?
Sì. Bleemeo funziona con qualsiasi distribuzione Kubernetes, inclusi Amazon EKS, Google GKE, Azure AKS e cluster autogestiti. Il chart Helm distribuisce un DaemonSet che viene eseguito su ogni nodo indipendentemente dall'infrastruttura sottostante.
Come fa Bleemeo a scoprire nuovi pod e servizi?
L'agente Glouton monitora l'API Kubernetes per gli eventi del ciclo di vita dei pod. Quando un nuovo pod si avvia, Bleemeo rileva automaticamente i servizi in esecuzione (database, server web, broker di messaggi, ecc.) e inizia a raccogliere metriche — senza configurazione di annotazioni o label.
Posso inviare le metriche Kubernetes alla mia installazione Prometheus esistente?
Sì. Bleemeo raccoglie le stesse metriche che gli utenti Prometheus si aspettano e le espone tramite un'interfaccia di query compatibile con PromQL. Puoi mantenere le tue dashboard Grafana e la logica di alerting esistenti. Scopri di più su Prometheus nel Cloud.
Quante risorse consuma l'agente Bleemeo?
L'agente Glouton è leggero per natura. Utilizza tipicamente meno di 100 MB di memoria e un minimo di CPU. Le request e i limit delle risorse sono preconfigurati nel chart Helm affinché l'agente non impatti mai sui tuoi workload.
Devo configurare qualcosa dopo l'installazione del chart Helm?
No. Una volta distribuito, Glouton scopre automaticamente nodi, pod, container e servizi. Le dashboard e le regole di avviso si attivano istantaneamente. Puoi opzionalmente personalizzare le soglie o aggiungere canali di notifica, ma i valori predefiniti coprono i casi d'uso più comuni.
Posso monitorare più cluster Kubernetes da un singolo account?
Sì. Installa il chart Helm su ogni cluster utilizzando le stesse credenziali dell'account. Tutti i cluster inviano dati alla stessa dashboard Bleemeo, offrendoti una vista unificata su ambienti di staging, produzione e edge — senza alcuna configurazione di federazione.
Come funzionano gli aggiornamenti del chart Helm?
L'aggiornamento avviene con un singolo comando: helm upgrade bleemeo-agent bleemeo/bleemeo-agent. Il DaemonSet esegue un aggiornamento progressivo, sostituendo i pod dell'agente uno alla volta senza interruzioni nel monitoring. Nessun dato viene perso durante l'aggiornamento.
Bleemeo può monitorare anche servizi fuori da Kubernetes?
Sì. L'agente Glouton di Bleemeo viene eseguito anche su server bare-metal, macchine virtuali e istanze cloud. Puoi monitorare l'intera infrastruttura — Kubernetes e non-Kubernetes — dalla stessa dashboard con le stesse regole di avviso.
Bleemeo supporta il monitoring a livello di namespace Kubernetes?
Sì. Bleemeo raggruppa automaticamente le metriche per namespace, offrendoti dashboard per namespace e la possibilità di impostare avvisi specifici per namespace. Questo è particolarmente utile per cluster multi-tenant dove i team necessitano visibilità sui propri workload.
Cosa succede se un nodo va giù?
Quando un nodo diventa irraggiungibile, Bleemeo rileva la perdita dell'heartbeat entro pochi minuti e attiva gli avvisi. Tutti i pod che erano in esecuzione su quel nodo vengono contrassegnati e il loro stato si riflette nelle dashboard. Una volta che il nodo si riprende o i pod vengono ripianificati, il monitoring riprende automaticamente.