Surveillez votre cluster Kubernetes en 10 minutes
Un chart Helm. Zéro configuration. Obtenez une visibilité complète sur vos clusters, nœuds, pods et conteneurs — avec une découverte automatique qui suit le rythme de vos déploiements.
Essai gratuit de 15 jours · Sans carte bancaire · Compatible EKS, GKE, AKS & auto-géré
Le monitoring Kubernetes ne devrait pas être aussi difficile
Le piège Prometheus
La plupart des équipes commencent avec Prometheus, Grafana, Alertmanager et une montagne de YAML. Avant qu'un seul tableau de bord ne soit utile, vous avez passé des jours à écrire des scrape configs, des recording rules et à construire des tableaux de bord de zéro — et c'est avant de gérer le stockage, la haute disponibilité ou la fédération. Ensuite, il faut de la rétention long terme, alors vous ajoutez Thanos ou Mimir — et soudain vous gérez une plateforme de monitoring au lieu de monitorer votre plateforme.
Les workloads éphémères cassent tout
Kubernetes évolue vite. Les pods vont et viennent, les ReplicaSets scalent, les nœuds se drainent. Les configurations de monitoring statiques ne suivent pas — les cibles disparaissent, les tableaux de bord deviennent obsolètes, et les alertes se déclenchent sur des ressources qui n'existent plus. Les outils traditionnels nécessitent des listes de cibles manuelles ou une découverte par annotations qui demande des modifications dans chaque manifeste de déploiement. Plus votre cluster est dynamique, plus cela génère de travail.
L'approche Bleemeo
Déployez un chart Helm. L'agent Glouton s'exécute en DaemonSet sur chaque nœud, surveille l'API Kubernetes pour les changements et découvre automatiquement chaque pod, conteneur et service. Les tableaux de bord et alertes s'activent en secondes — pas de fichiers de config, pas de langage de requête, pas de maintenance. Quand un pod scale up à 2h du matin, Bleemeo le détecte instantanément. Quand il scale down, les données obsolètes sont nettoyées automatiquement.
3 étapes vers une observabilité Kubernetes complète
De zéro à un monitoring prêt pour la production en environ 10 minutes.
Déployez avec Helm
Ajoutez le dépôt Helm Bleemeo et installez le chart. L'agent se déploie en DaemonSet — un pod par nœud, automatiquement.
helm repo add bleemeo https://packages.bleemeo.com/helm/ helm repo update helm install bleemeo-agent bleemeo/bleemeo-agent \ --set bleemeo.account=YOUR_ACCOUNT_ID \ --set bleemeo.key=YOUR_REGISTRATION_KEY Obtenez vos identifiants depuis votre compte Bleemeo. Aucune autre configuration nécessaire.
- DaemonSet s'exécute automatiquement sur chaque nœud
- Compatible EKS, GKE, AKS, k3s et auto-géré
- Léger — moins de 100 Mo de mémoire par nœud
- Agent open source (Apache 2.0)
Pourquoi un DaemonSet ?
Un DaemonSet garantit un pod agent par nœud — y compris les nœuds ajoutés plus tard par les autoscalers. Vous n'avez jamais à mettre à jour votre monitoring quand le cluster grandit ou rétrécit. Comparez cela avec l'injection sidecar, qui nécessite des modifications dans chaque manifeste de workload et ajoute de l'overhead à chaque pod.
La découverte automatique se met en marche
Glouton surveille l'API Kubernetes et découvre chaque pod, conteneur et service en cours d'exécution sur chaque nœud. Pas d'annotations, pas de labels, pas de ServiceMonitors à écrire.
- Nœuds, pods et conteneurs détectés automatiquement
- Services dans les pods reconnus (MySQL, Redis, Nginx, etc.)
- Nouveaux déploiements détectés en quelques secondes
- Pods terminés nettoyés — pas de données obsolètes
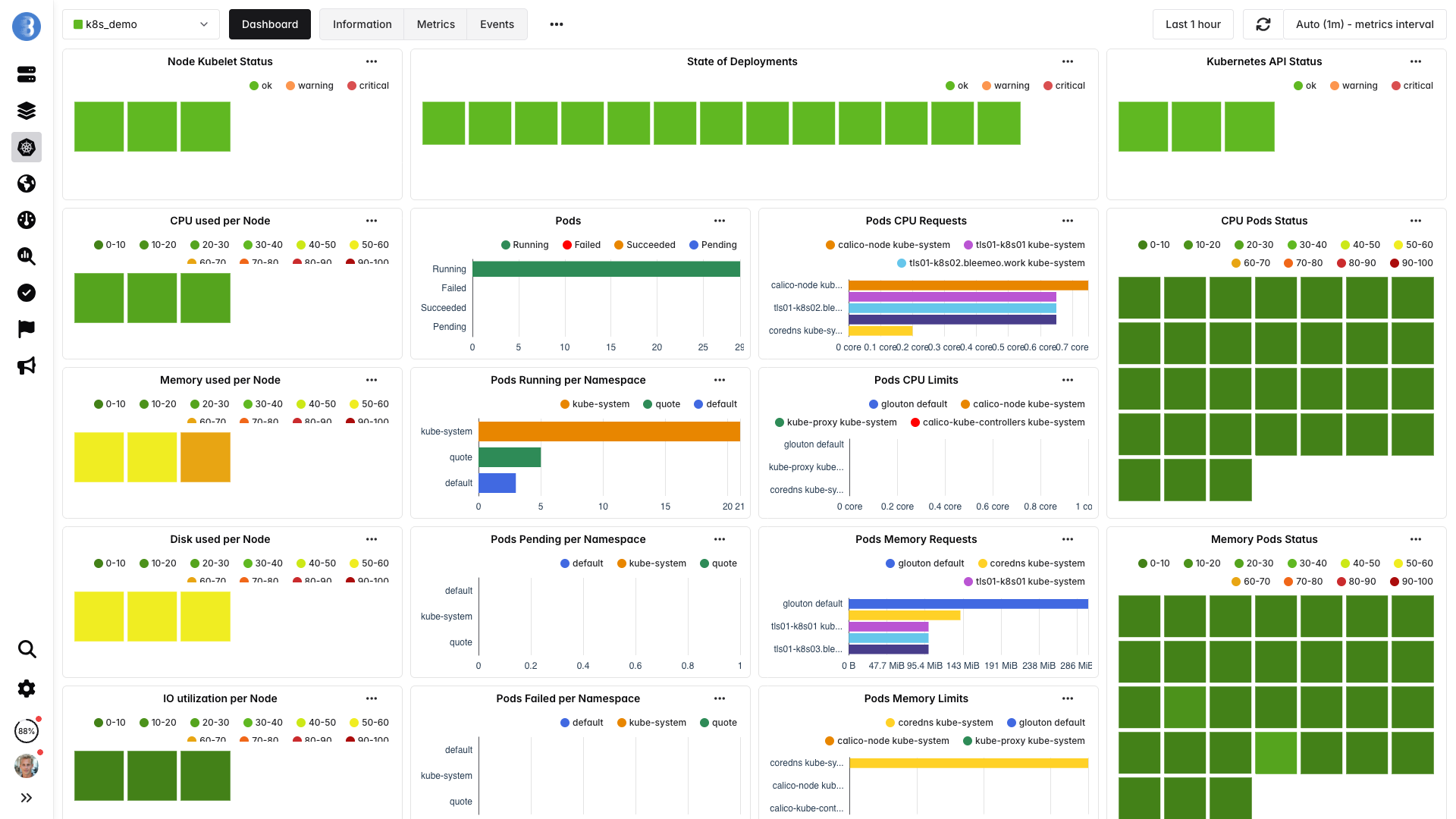
Pourquoi la découverte automatique est importante dans Kubernetes
Dans un environnement Kubernetes, les workloads sont constamment créés, déplacés et détruits. La configuration manuelle du monitoring ne peut pas suivre ce rythme. La découverte automatique signifie que chaque nouveau déploiement, réplica de StatefulSet ou pod CronJob est monitoré dès son démarrage — sans intervention humaine.
Tableaux de bord & alertes — Prêts
Des tableaux de bord pré-construits et des règles d'alerte intelligentes s'activent dès que les services sont découverts. Vous faites du monitoring en production — pas de la construction de plateforme de monitoring.
- Vue d'ensemble du cluster : nombre de nœuds, état des pods, utilisation des ressources
- Tableaux de bord par pod : CPU, mémoire, redémarrages, réseau
- Exemples d'alertes : crash loops de pods, CPU élevé des nœuds, pression disque
- Notifications via Slack, Teams, PagerDuty, email, webhooks
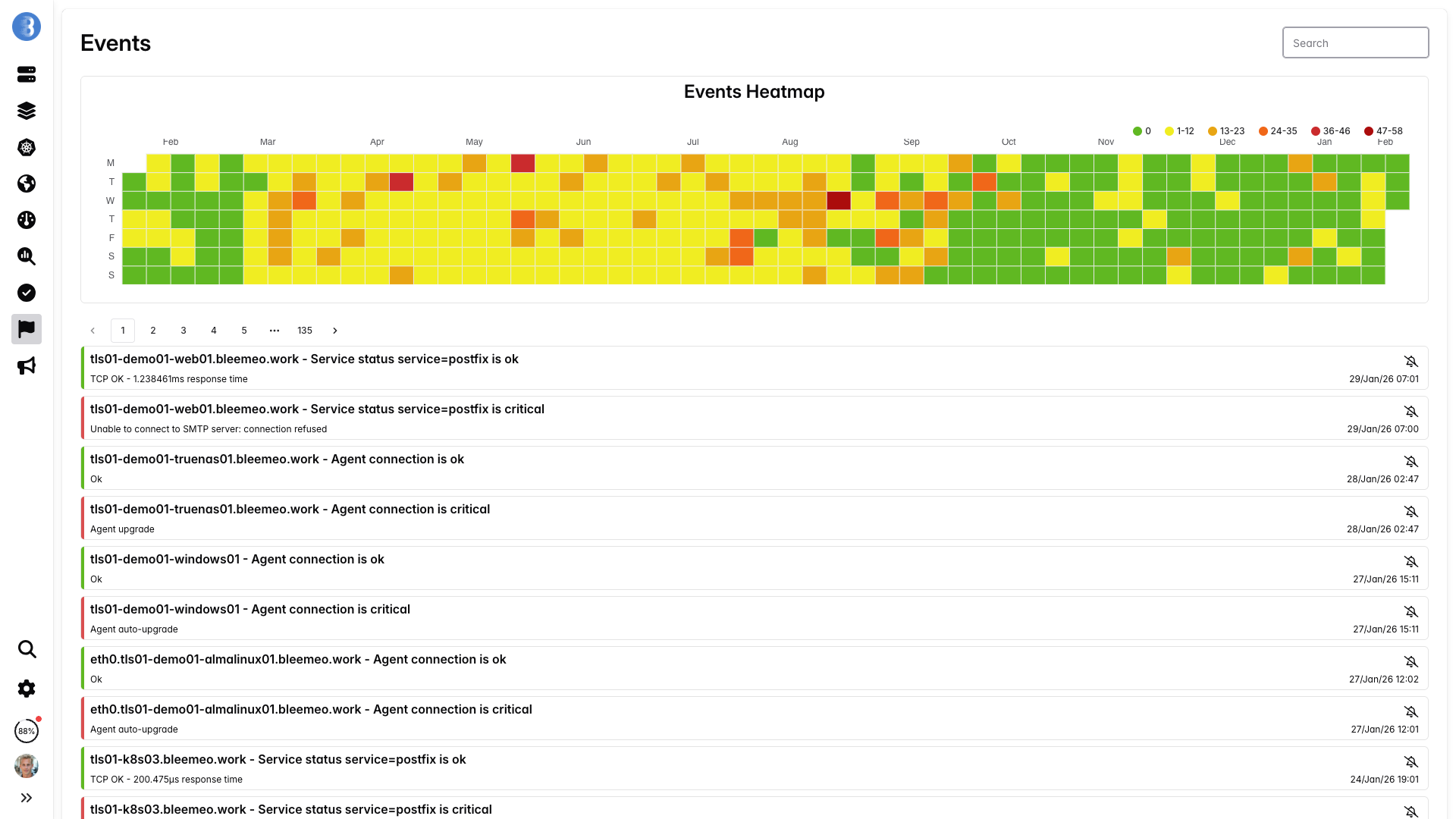
Pourquoi les alertes pré-construites vous font gagner des heures
Écrire de bonnes règles d'alerte Kubernetes de zéro est étonnamment difficile. Il faut gérer les phases des pods, les états des conteneurs, les conditions de pression sur les ressources, et éviter les faux positifs bruyants pendant les rolling deployments. Bleemeo est livré avec des valeurs par défaut éprouvées pour que vous commenciez avec des alertes fiables dès le premier jour — et vous pouvez toujours les personnaliser ensuite.
Ce que vous monitorez dès le départ
Tout est découvert automatiquement — pas de requêtes personnalisées, pas de configuration manuelle.
Kubernetes introduit plusieurs couches d'abstraction — clusters, nœuds, pods, conteneurs et les services qui tournent à l'intérieur. Un monitoring efficace signifie couvrir chaque couche, car un problème à un niveau (par exemple, pression disque sur un nœud) se propage en symptômes à un autre (évictions de pods, erreurs applicatives). Bleemeo surveille toutes ces couches dès le départ, pour que vous voyiez à la fois la cause racine et l'impact dans un seul tableau de bord.
| Couche | Métriques clés | Exemples d'alertes |
|---|---|---|
| Cluster | Nombre de nœuds, capacité en pods, allocation de ressources | Nœud du cluster non prêt |
| Nœuds | CPU, mémoire, disque, réseau par nœud | CPU nœud > 90%, pression disque |
| Pods | État, redémarrages, requests vs. utilisation CPU/mémoire | Crash loop de pod, OOMKilled |
| Conteneurs | Throttling CPU, limits mémoire, I/O système de fichiers | Mémoire conteneur > 90% de la limite |
| Services | Requêtes MySQL/s, latence Redis, req/s Nginx, etc. | Seuils spécifiques au service |
| Réseau | Octets entrants/sortants, erreurs de paquets, résolution DNS | Perte de paquets élevée, échecs DNS |
Pourquoi Bleemeo pour Kubernetes
Conçu spécifiquement pour les environnements dynamiques et conteneurisés.
Zéro configuration
Pas de scrape configs, pas de ServiceMonitors, pas d'annotations. Glouton découvre tout en surveillant l'API Kubernetes — les nouveaux déploiements sont monitorés automatiquement.
Visibilité instantanée
Les métriques apparaissent en quelques secondes après le déploiement de l'agent. Les tableaux de bord pré-construits vous offrent des vues cluster, nœud et pod sans construire un seul panneau.
Multi-cluster prêt
Déployez le même chart Helm sur vos clusters de staging, production et edge. Toutes les données convergent vers une interface unique — sans fédération nécessaire.
Alertes intelligentes
Des règles d'alerte éprouvées pour les crash loops, OOMKills, pression sur les nœuds et plus encore — actives dès la première minute. Envoyez les notifications vers Slack, Teams, PagerDuty ou email.
Agent léger
Glouton utilise moins de 100 Mo de mémoire par nœud. Les limites de ressources sont pré-configurées dans le chart Helm, l'agent ne concurrence jamais vos workloads.
Couverture complète du stack
De la capacité au niveau cluster au throttling CPU par conteneur et aux métriques applicatives comme les requêtes MySQL ou la latence Redis — un seul agent couvre tout.
Bleemeo vs. Stack Prometheus DIY
Ce qu'il faut vraiment pour monitorer Kubernetes
| Aspect | Prometheus DIY | Bleemeo |
|---|---|---|
| Temps de mise en place | Jours à semaines | 10 minutes |
| Configuration | Scrape configs, recording rules, règles d'alerte | Zéro config — découverte automatique |
| Tableaux de bord | À construire de zéro dans Grafana | Pré-construits, auto-activés |
| Stockage & rétention | Gérer Thanos/Cortex/Mimir | Entièrement géré, inclus |
| Haute disponibilité | Stacks dupliqués + fédération | Redondance intégrée |
| Support nouveau service | Trouver l'exporter, ajouter scrape config | Détecté en secondes |
| Maintenance continue | Mises à jour, planification de capacité | Aucune — SaaS entièrement géré |
Déjà investi dans Prometheus ? Bleemeo est conçu pour les utilisateurs Prometheus — gardez vos requêtes PromQL et vos tableaux de bord Grafana, éliminez la charge opérationnelle.
Conçu pour les utilisateurs Prometheus
Vous utilisez déjà Prometheus ? Bleemeo collecte les mêmes métriques que vous connaissez et les expose via une interface de requête compatible PromQL. Gardez vos tableaux de bord Grafana et votre logique d'alerte existants — sans maintenir l'infrastructure Prometheus vous-même.
En savoir plus sur Prometheus dans le CloudLa confiance d'équipes exécutant Kubernetes en production
Ingénieurs et CTO font confiance à Bleemeo pour surveiller leur infrastructure
Pendant une courte pause déjeuner, nous avons installé Bleemeo, créé une métrique personnalisée, testé les alertes et étions prêts pour la production. La rapidité de déploiement est remarquable.

Le support Bleemeo est tout simplement légendaire — rapide, compétent et toujours présent quand on en a besoin.
Le déploiement de Bleemeo a été incroyablement rapide. En environ une heure, nous l'avons déployé sur plus de 100 serveurs et avons immédiatement obtenu une visibilité complète sur notre infrastructure.

Nous avons mis en place le monitoring de tous nos serveurs en quelques heures seulement. Le tableau de bord est clair, puissant et véritablement agréable à utiliser.

Nous avons déployé Bleemeo sur l'ensemble de notre infrastructure serveur en quelques heures seulement. Le monitoring de disponibilité nous alerte désormais instantanément dès qu'un service rencontre un problème.

Notre stack Prometheus + Grafana était devenu un projet de maintenance. Avec Bleemeo, nous avons déployé l'agent en quelques minutes et avons enfin pu nous concentrer sur l'utilisation du monitoring au lieu de sa maintenance.
Après l'installation de l'agent, Bleemeo a automatiquement découvert nos bases de données, conteneurs et services. En une heure, nous avions une visibilité complète sur l'infrastructure — sans tableaux de bord ni exporters à créer.
Bleemeo a remplacé plusieurs outils de monitoring par une plateforme unique. Métriques, alertes et logs sont désormais au même endroit, ce qui fait gagner un temps considérable à notre équipe.
Bleemeo nous a donné une visibilité immédiate sur notre infrastructure sans la complexité habituelle. En quelques heures, nous avions des métriques, des alertes et des tableaux de bord pleinement opérationnels.
La mise en place de Bleemeo a été d'une simplicité rafraîchissante. Le déploiement de l'agent a pris quelques minutes et la découverte automatique nous a fait économiser des jours de configuration.
Grâce à Bleemeo, notre équipe détecte désormais les problèmes avant que nos utilisateurs ne les remarquent. Les alertes sont fiables et l'interface rend le dépannage bien plus rapide.
Le passage à Bleemeo a considérablement simplifié notre stack de monitoring. Au lieu de gérer plusieurs outils, tout ce dont nous avons besoin est disponible sur une seule plateforme.
La centralisation de nos logs dans Bleemeo a drastiquement simplifié le dépannage. Au lieu de jongler entre les outils, nous pouvons désormais corréler métriques et logs instantanément pour comprendre ce qui se passe.
Bleemeo a rendu le monitoring Kubernetes étonnamment simple. En quelques minutes, nous avions une visibilité sur nos clusters, pods et workloads sans avoir à construire des tableaux de bord complexes nous-mêmes.
Prêt à monitorer Kubernetes en 10 minutes ?
Un chart Helm. Observabilité complète. Zéro maintenance. Commencez votre essai gratuit dès aujourd'hui.
Essai gratuit de 15 jours · Sans carte bancaire · Annulation à tout moment
Questions fréquemment posées
Bleemeo fonctionne-t-il avec les services Kubernetes managés comme EKS, GKE et AKS ?
Oui. Bleemeo fonctionne avec toute distribution Kubernetes, y compris Amazon EKS, Google GKE, Azure AKS et les clusters auto-gérés. Le chart Helm déploie un DaemonSet qui s'exécute sur chaque nœud, quelle que soit l'infrastructure sous-jacente.
Comment Bleemeo découvre-t-il les nouveaux pods et services ?
L'agent Glouton surveille l'API Kubernetes pour les événements de cycle de vie des pods. Quand un nouveau pod démarre, Bleemeo détecte automatiquement les services en cours d'exécution (bases de données, serveurs web, brokers de messages, etc.) et commence à collecter les métriques — sans configuration d'annotations ou de labels.
Puis-je envoyer les métriques Kubernetes vers mon installation Prometheus existante ?
Oui. Bleemeo collecte les mêmes métriques que les utilisateurs Prometheus attendent et les expose via une interface de requête compatible PromQL. Vous pouvez conserver vos tableaux de bord Grafana et votre logique d'alerte existants. En savoir plus sur Prometheus dans le Cloud.
Quelles ressources l'agent Bleemeo consomme-t-il ?
L'agent Glouton est léger par conception. Il utilise généralement moins de 100 Mo de mémoire et un minimum de CPU. Les requests et limits de ressources sont pré-configurés dans le chart Helm pour que l'agent n'impacte jamais vos workloads.
Dois-je configurer quelque chose après l'installation du chart Helm ?
Non. Une fois déployé, Glouton découvre automatiquement les nœuds, pods, conteneurs et services. Les tableaux de bord et règles d'alerte sont activés instantanément. Vous pouvez optionnellement personnaliser les seuils ou ajouter des canaux de notification, mais les valeurs par défaut couvrent les cas d'usage les plus courants.
Puis-je surveiller plusieurs clusters Kubernetes depuis un seul compte ?
Oui. Installez le chart Helm sur chaque cluster en utilisant les mêmes identifiants de compte. Tous les clusters remontent vers le même tableau de bord Bleemeo, vous offrant une vue unifiée à travers les environnements de staging, production et edge — sans configuration de fédération.
Comment fonctionnent les mises à jour du chart Helm ?
La mise à jour se fait en une seule commande : helm upgrade bleemeo-agent bleemeo/bleemeo-agent. Le DaemonSet effectue une mise à jour progressive, les pods agent sont remplacés un nœud à la fois sans interruption du monitoring. Aucune donnée n'est perdue pendant la mise à jour.
Bleemeo peut-il aussi surveiller des services hors Kubernetes ?
Oui. L'agent Glouton de Bleemeo s'exécute aussi sur des serveurs bare-metal, des machines virtuelles et des instances cloud. Vous pouvez surveiller toute votre infrastructure — Kubernetes et non-Kubernetes — depuis le même tableau de bord avec les mêmes règles d'alerte.
Bleemeo supporte-t-il le monitoring par namespace Kubernetes ?
Oui. Bleemeo regroupe automatiquement les métriques par namespace, vous offrant des tableaux de bord par namespace et la possibilité de configurer des alertes ciblées sur des namespaces spécifiques. C'est particulièrement utile pour les clusters multi-tenants où les équipes ont besoin de visibilité sur leurs propres workloads.
Que se passe-t-il si un nœud tombe en panne ?
Quand un nœud devient inaccessible, Bleemeo détecte la perte de heartbeat en quelques minutes et déclenche des alertes. Tous les pods qui s'exécutaient sur ce nœud sont signalés, et leur état est reflété dans vos tableaux de bord. Une fois que le nœud récupère ou que les pods sont re-planifiés, le monitoring reprend automatiquement.