Monitoriza tu clúster Kubernetes en 10 minutos
Un chart Helm. Cero configuración. Obtén visibilidad completa sobre tus clústeres, nodos, pods y contenedores — con detección automática que sigue el ritmo de tus despliegues.
15 días de prueba gratuita · Sin tarjeta de crédito · Compatible con EKS, GKE, AKS & autogestionado
El monitoring de Kubernetes no debería ser tan difícil
La trampa de Prometheus
La mayoría de los equipos empiezan con Prometheus, Grafana, Alertmanager y una montaña de YAML. Antes de que un solo dashboard sea útil, has pasado días escribiendo scrape configs, recording rules y construyendo dashboards desde cero — y eso antes de gestionar el almacenamiento, la alta disponibilidad o la federación. Luego necesitas retención a largo plazo, así que añades Thanos o Mimir — y de repente estás gestionando una plataforma de monitoring en lugar de monitorizar tu plataforma.
Los workloads efímeros lo rompen todo
Kubernetes se mueve rápido. Los pods van y vienen, los ReplicaSets escalan, los nodos se drenan. Las configuraciones de monitoring estáticas no pueden seguir el ritmo — los targets desaparecen, los dashboards quedan obsoletos, y las alertas se disparan sobre recursos que ya no existen. Las herramientas tradicionales necesitan listas de targets manuales o detección basada en anotaciones que requiere cambios en cada manifiesto de despliegue. Cuanto más dinámico es tu clúster, más trabajo genera.
El enfoque de Bleemeo
Despliega un chart Helm. El agente Glouton se ejecuta como DaemonSet en cada nodo, monitoriza la API de Kubernetes en busca de cambios y descubre automáticamente cada pod, contenedor y servicio. Los dashboards y alertas se activan en segundos — sin archivos de configuración, sin lenguaje de consulta, sin mantenimiento. Cuando un pod escala a las 2 de la madrugada, Bleemeo lo detecta al instante. Cuando vuelve a escalar, los datos obsoletos se limpian automáticamente.
3 pasos hacia una observabilidad Kubernetes completa
De cero a monitoring listo para producción en unos 10 minutos.
Despliega con Helm
Añade el repositorio Helm de Bleemeo e instala el chart. El agente se despliega como DaemonSet — un pod por nodo, automáticamente.
helm repo add bleemeo https://packages.bleemeo.com/helm/ helm repo update helm install bleemeo-agent bleemeo/bleemeo-agent \ --set bleemeo.account=YOUR_ACCOUNT_ID \ --set bleemeo.key=YOUR_REGISTRATION_KEY Obtén tus credenciales desde tu cuenta Bleemeo. No se necesita más configuración.
- DaemonSet se ejecuta automáticamente en cada nodo
- Compatible con EKS, GKE, AKS, k3s y autogestionado
- Ligero — menos de 100 MB de memoria por nodo
- Agente open source (Apache 2.0)
¿Por qué un DaemonSet?
Un DaemonSet garantiza un pod de agente por nodo — incluyendo nodos añadidos después por los autoscalers. Nunca tienes que actualizar tu monitoring cuando el clúster crece o se reduce. Compáralo con la inyección sidecar, que requiere cambios en cada manifiesto de workload y añade overhead a cada pod.
La detección automática se activa
Glouton monitoriza la API de Kubernetes y descubre cada pod, contenedor y servicio en ejecución en cada nodo. Sin anotaciones, sin labels, sin ServiceMonitors que escribir.
- Nodos, pods y contenedores detectados automáticamente
- Servicios dentro de pods reconocidos (MySQL, Redis, Nginx, etc.)
- Nuevos despliegues detectados en segundos
- Pods terminados limpiados — sin datos obsoletos
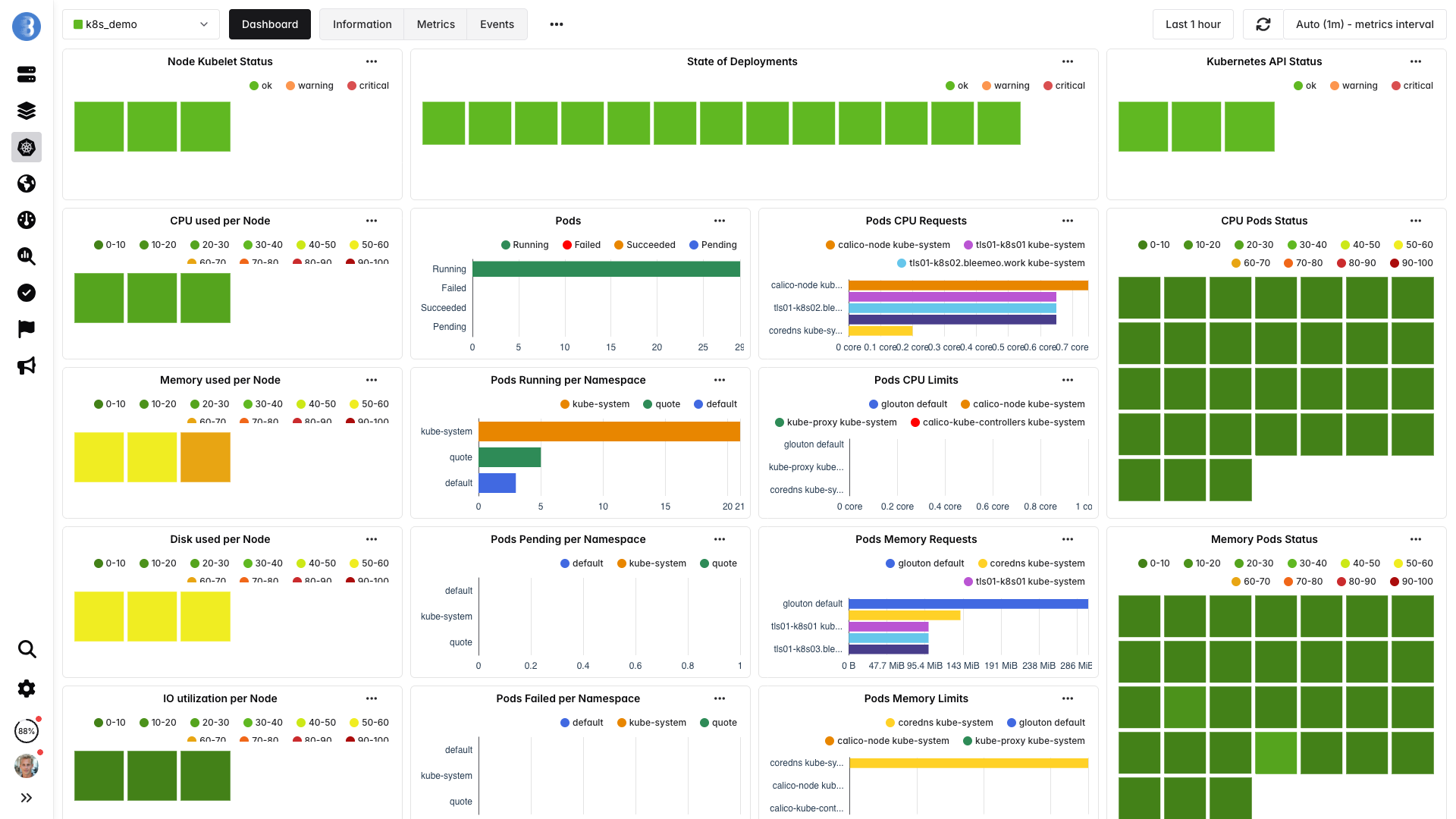
Por qué la detección automática importa en Kubernetes
En un entorno Kubernetes, los workloads se crean, mueven y destruyen constantemente. La configuración manual del monitoring no puede seguir el ritmo. La detección automática significa que cada nuevo despliegue, réplica de StatefulSet o pod CronJob se monitoriza en el instante en que se inicia — sin intervención humana.
Dashboards y alertas — Listos
Dashboards preconstruidos y reglas de alerta inteligentes se activan en el momento en que se descubren los servicios. Estás monitorizando en producción — no construyendo una plataforma de monitoring.
- Vista general del clúster: número de nodos, estado de pods, uso de recursos
- Dashboards por pod: CPU, memoria, reinicios, red
- Ejemplos de alertas: crash loops de pods, CPU alta en nodos, presión de disco
- Notificaciones vía Slack, Teams, PagerDuty, email, webhooks
Por qué las alertas preconstruidas te ahorran horas
Escribir buenas reglas de alerta para Kubernetes desde cero es sorprendentemente difícil. Necesitas manejar las fases de los pods, los estados de los contenedores, las condiciones de presión de recursos y evitar falsos positivos ruidosos durante los rolling deployments. Bleemeo viene con valores predeterminados probados para que empieces con alertas fiables desde el primer día — y siempre puedes personalizarlas después.
Qué monitorizas desde el primer momento
Todo descubierto automáticamente — sin consultas personalizadas, sin configuración manual.
Kubernetes introduce múltiples capas de abstracción — clústeres, nodos, pods, contenedores y los servicios que se ejecutan dentro de ellos. Un monitoring eficaz significa cubrir cada capa, porque un problema en un nivel (por ejemplo, presión de disco en un nodo) se propaga en síntomas en otro (evictions de pods, errores de aplicación). Bleemeo monitoriza todas estas capas desde el primer momento, para que veas tanto la causa raíz como el impacto en un solo dashboard.
| Capa | Métricas clave | Alertas de ejemplo |
|---|---|---|
| Clúster | Número de nodos, capacidad de pods, asignación de recursos | Nodo del clúster no listo |
| Nodos | CPU, memoria, disco, red por nodo | CPU nodo > 90%, presión de disco |
| Pods | Estado, reinicios, CPU/memoria requests vs. uso | Crash loop de pod, OOMKilled |
| Contenedores | Throttling de CPU, limits de memoria, I/O de sistema de archivos | Memoria del contenedor > 90% del límite |
| Servicios | Consultas MySQL/s, latencia Redis, req/s Nginx, etc. | Umbrales específicos del servicio |
| Red | Bytes entrada/salida, errores de paquetes, resolución DNS | Alta pérdida de paquetes, fallos DNS |
Por qué Bleemeo para Kubernetes
Diseñado específicamente para entornos dinámicos y contenedorizados.
Cero configuración
Sin scrape configs, sin ServiceMonitors, sin anotaciones. Glouton descubre todo monitorizando la API de Kubernetes — los nuevos despliegues se monitorizan automáticamente.
Visibilidad instantánea
Las métricas aparecen en segundos tras el despliegue del agente. Los dashboards preconstruidos te ofrecen vistas de clúster, nodo y pod sin construir un solo panel.
Multi-clúster listo
Despliega el mismo chart Helm en tus clústeres de staging, producción y edge. Todos los datos fluyen a una única interfaz — sin federación necesaria.
Alertas inteligentes
Reglas de alerta probadas para crash loops, OOMKills, presión en nodos y más — activas desde el primer minuto. Envía notificaciones a Slack, Teams, PagerDuty o email.
Agente ligero
Glouton utiliza menos de 100 MB de memoria por nodo. Los límites de recursos están preconfigurados en el chart Helm, el agente nunca compite con tus workloads.
Cobertura completa del stack
Desde la capacidad a nivel de clúster hasta el throttling de CPU por contenedor y métricas de aplicación como consultas MySQL o latencia Redis — un solo agente lo cubre todo.
Bleemeo vs. Stack Prometheus DIY
Lo que realmente se necesita para monitorizar Kubernetes
| Aspecto | Prometheus DIY | Bleemeo |
|---|---|---|
| Tiempo de configuración | Días a semanas | 10 minutos |
| Configuración | Scrape configs, recording rules, reglas de alerta | Cero configuración — detección automática |
| Dashboards | Construir desde cero en Grafana | Preconstruidos, auto-activados |
| Almacenamiento & retención | Gestionar Thanos/Cortex/Mimir | Totalmente gestionado, incluido |
| Alta disponibilidad | Stacks duplicados + federación | Redundancia integrada |
| Soporte nuevo servicio | Encontrar exporter, añadir scrape config | Detectado en segundos |
| Mantenimiento continuo | Actualizaciones de versión, planificación de capacidad | Ninguno — SaaS totalmente gestionado |
¿Ya invertiste en Prometheus? Bleemeo está diseñado para usuarios de Prometheus — conserva tus consultas PromQL y dashboards de Grafana, elimina la carga operacional.
Diseñado para usuarios de Prometheus
¿Ya usas Prometheus? Bleemeo recopila las mismas métricas que conoces y las expone a través de una interfaz de consulta compatible con PromQL. Conserva tus dashboards de Grafana y tu lógica de alertas existente — sin mantener la infraestructura de Prometheus tú mismo.
Más sobre Prometheus en la NubeLa confianza de equipos que ejecutan Kubernetes en producción
Ingenieros y CTOs confían en Bleemeo para monitorear su infraestructura
Durante una breve pausa para almorzar, instalamos Bleemeo, creamos una métrica personalizada, probamos las alertas y estábamos listos para producción. La velocidad de despliegue es notable.

El soporte de Bleemeo es simplemente legendario: rápido, competente y siempre disponible cuando lo necesitamos.
Bleemeo fue increíblemente rápido de desplegar. En aproximadamente una hora lo implementamos en más de 100 servidores y obtuvimos visibilidad completa de nuestra infraestructura de inmediato.

Configuramos el monitoreo de todos nuestros servidores en solo unas pocas horas. El dashboard es claro, potente y realmente agradable de usar.

Desplegamos Bleemeo en toda nuestra infraestructura de servidores en solo unas pocas horas. El monitoreo de disponibilidad ahora nos alerta instantáneamente cuando un servicio tiene un problema.

Nuestra pila de Prometheus + Grafana se había convertido en un proyecto de mantenimiento. Con Bleemeo desplegamos el agente en minutos y finalmente nos enfocamos en usar el monitoreo en lugar de mantenerlo.
Después de instalar el agente, Bleemeo descubrió automáticamente nuestras bases de datos, contenedores y servicios. En una hora teníamos visibilidad completa de la infraestructura, sin dashboards ni exporters que construir.
Bleemeo reemplazó varias herramientas de monitoreo con una sola plataforma. Métricas, alertas y logs están ahora en un solo lugar, ahorrando a nuestro equipo un tiempo significativo.
Bleemeo nos dio una visión inmediata de nuestra infraestructura sin la complejidad habitual. En un par de horas teníamos métricas, alertas y dashboards funcionando sin problemas.
Configurar Bleemeo fue sorprendentemente simple. El despliegue del agente tomó minutos y el descubrimiento automático nos ahorró días de configuración.
Gracias a Bleemeo, nuestro equipo ahora detecta problemas antes de que los usuarios los noten. Las alertas son fiables y la interfaz hace que la resolución de problemas sea mucho más rápida.
Migrar a Bleemeo simplificó drásticamente nuestra pila de monitoreo. En lugar de gestionar múltiples herramientas, todo lo que necesitamos está disponible en una sola plataforma.
Centralizar nuestros logs en Bleemeo simplificó drásticamente la resolución de problemas. En lugar de saltar entre herramientas, ahora podemos correlacionar métricas y logs instantáneamente para entender qué está pasando.
Bleemeo hizo que el monitoreo de Kubernetes fuera sorprendentemente fácil. En minutos teníamos visibilidad de nuestros clusters, pods y cargas de trabajo sin tener que construir dashboards complejos nosotros mismos.
¿Listo para monitorizar Kubernetes en 10 minutos?
Un chart Helm. Observabilidad completa. Sin mantenimiento. Comienza tu prueba gratuita hoy.
15 días de prueba gratuita · Sin tarjeta de crédito · Cancela en cualquier momento
Preguntas frecuentes
¿Funciona Bleemeo con servicios Kubernetes gestionados como EKS, GKE y AKS?
Sí. Bleemeo funciona con cualquier distribución de Kubernetes, incluyendo Amazon EKS, Google GKE, Azure AKS y clústeres autogestionados. El chart Helm despliega un DaemonSet que se ejecuta en cada nodo independientemente de la infraestructura subyacente.
¿Cómo descubre Bleemeo nuevos pods y servicios?
El agente Glouton monitoriza la API de Kubernetes en busca de eventos del ciclo de vida de los pods. Cuando un nuevo pod se inicia, Bleemeo detecta automáticamente los servicios en ejecución (bases de datos, servidores web, brokers de mensajes, etc.) y comienza a recopilar métricas — sin configuración de anotaciones ni labels.
¿Puedo enviar métricas de Kubernetes a mi instalación Prometheus existente?
Sí. Bleemeo recopila las mismas métricas que los usuarios de Prometheus esperan y las expone a través de una interfaz de consulta compatible con PromQL. Puedes conservar tus dashboards de Grafana y tu lógica de alertas existentes. Más sobre Prometheus en la Nube.
¿Qué recursos consume el agente de Bleemeo?
El agente Glouton es ligero por diseño. Normalmente utiliza menos de 100 MB de memoria y un mínimo de CPU. Los requests y limits de recursos están preconfigurados en el chart Helm para que el agente nunca afecte a tus workloads.
¿Necesito configurar algo después de instalar el chart Helm?
No. Una vez desplegado, Glouton descubre automáticamente nodos, pods, contenedores y servicios. Los dashboards y las reglas de alerta se activan instantáneamente. Puedes personalizar opcionalmente los umbrales o añadir canales de notificación, pero los valores predeterminados cubren los casos de uso más comunes.
¿Puedo monitorizar múltiples clústeres Kubernetes desde una sola cuenta?
Sí. Instala el chart Helm en cada clúster utilizando las mismas credenciales de cuenta. Todos los clústeres reportan al mismo dashboard de Bleemeo, ofreciéndote una vista unificada de los entornos de staging, producción y edge — sin configuración de federación.
¿Cómo funcionan las actualizaciones del chart Helm?
La actualización se realiza con un solo comando: helm upgrade bleemeo-agent bleemeo/bleemeo-agent. El DaemonSet realiza una actualización progresiva, reemplazando los pods del agente de uno en uno sin interrupciones en el monitoring. No se pierde ningún dato durante la actualización.
¿Puede Bleemeo monitorizar servicios fuera de Kubernetes?
Sí. El agente Glouton de Bleemeo también se ejecuta en servidores bare-metal, máquinas virtuales e instancias en la nube. Puedes monitorizar toda tu infraestructura — Kubernetes y no-Kubernetes — desde el mismo dashboard con las mismas reglas de alerta.
¿Soporta Bleemeo el monitoring a nivel de namespace de Kubernetes?
Sí. Bleemeo agrupa automáticamente las métricas por namespace, ofreciéndote dashboards por namespace y la posibilidad de configurar alertas limitadas a namespaces específicos. Esto es especialmente útil para clústeres multi-tenant donde los equipos necesitan visibilidad sobre sus propios workloads.
¿Qué ocurre si un nodo se cae?
Cuando un nodo deja de ser accesible, Bleemeo detecta la pérdida de heartbeat en minutos y dispara alertas. Todos los pods que se ejecutaban en ese nodo se marcan y su estado se refleja en tus dashboards. Una vez que el nodo se recupera o los pods se reprograman, el monitoring se reanuda automáticamente.