Überwachen Sie Ihren Kubernetes-Cluster in 10 Minuten
Ein Helm Chart. Null Konfiguration. Erhalten Sie volle Sichtbarkeit über Ihre Cluster, Knoten, Pods und Container — mit automatischer Erkennung, die mit Ihren Deployments Schritt hält.
15 Tage kostenlos testen · Keine Kreditkarte erforderlich · Kompatibel mit EKS, GKE, AKS & selbstverwaltet
Kubernetes-Monitoring sollte nicht so schwer sein
Die Prometheus-Falle
Die meisten Teams starten mit Prometheus, Grafana, Alertmanager und einem Berg von YAML. Bevor ein einziges Dashboard nützlich ist, haben Sie Tage damit verbracht, Scrape-Configs, Recording Rules und Dashboards von Grund auf zu erstellen — und das noch bevor Sie sich um Speicher, Hochverfügbarkeit oder Federation kümmern. Dann brauchen Sie Langzeitretention, also fügen Sie Thanos oder Mimir hinzu — und plötzlich betreiben Sie eine Monitoring-Plattform, anstatt Ihre Plattform zu monitoren.
Kurzlebige Workloads machen alles kaputt
Kubernetes bewegt sich schnell. Pods kommen und gehen, ReplicaSets skalieren, Knoten werden drainiert. Statische Monitoring-Konfigurationen können nicht mithalten — Ziele verschwinden, Dashboards veralten, und Alerts feuern auf Ressourcen, die nicht mehr existieren. Traditionelle Tools benötigen manuelle Ziellisten oder annotationsbasierte Erkennung, die Änderungen an jedem Deployment-Manifest erfordert. Je dynamischer Ihr Cluster, desto mehr Arbeit entsteht.
Der Bleemeo-Ansatz
Deployen Sie ein Helm Chart. Der Glouton-Agent läuft als DaemonSet auf jedem Knoten, überwacht die Kubernetes-API auf Änderungen und erkennt automatisch jeden Pod, Container und Service. Dashboards und Alerts aktivieren sich in Sekunden — keine Config-Dateien, keine Abfragesprache, keine Wartung. Wenn ein Pod um 2 Uhr nachts hochskaliert, erkennt Bleemeo ihn sofort. Wenn er wieder herunterskaliert, werden veraltete Daten automatisch bereinigt.
3 Schritte zur vollständigen Kubernetes-Observability
Von null zu produktionsreifem Monitoring in etwa 10 Minuten.
Mit Helm bereitstellen
Fügen Sie das Bleemeo Helm-Repository hinzu und installieren Sie das Chart. Der Agent wird als DaemonSet bereitgestellt — ein Pod pro Knoten, automatisch.
helm repo add bleemeo https://packages.bleemeo.com/helm/ helm repo update helm install bleemeo-agent bleemeo/bleemeo-agent \ --set bleemeo.account=YOUR_ACCOUNT_ID \ --set bleemeo.key=YOUR_REGISTRATION_KEY Holen Sie sich Ihre Zugangsdaten von Ihrem Bleemeo-Konto. Keine weitere Konfiguration nötig.
- DaemonSet läuft automatisch auf jedem Knoten
- Kompatibel mit EKS, GKE, AKS, k3s und selbstverwaltet
- Leichtgewichtig — unter 100 MB Speicher pro Knoten
- Open-Source-Agent (Apache 2.0)
Warum ein DaemonSet?
Ein DaemonSet garantiert einen Agent-Pod pro Knoten — einschließlich Knoten, die später von Autoscalern hinzugefügt werden. Sie müssen Ihr Monitoring nie aktualisieren, wenn der Cluster wächst oder schrumpft. Vergleichen Sie das mit Sidecar-Injection, die Änderungen an jedem Workload-Manifest erfordert und Overhead zu jedem Pod hinzufügt.
Die automatische Erkennung startet
Glouton überwacht die Kubernetes-API und erkennt jeden Pod, Container und Service, der auf jedem Knoten läuft. Keine Annotations, keine Labels, keine ServiceMonitors zu schreiben.
- Knoten, Pods und Container automatisch erkannt
- Services in Pods erkannt (MySQL, Redis, Nginx usw.)
- Neue Deployments innerhalb von Sekunden erfasst
- Beendete Pods bereinigt — keine veralteten Daten
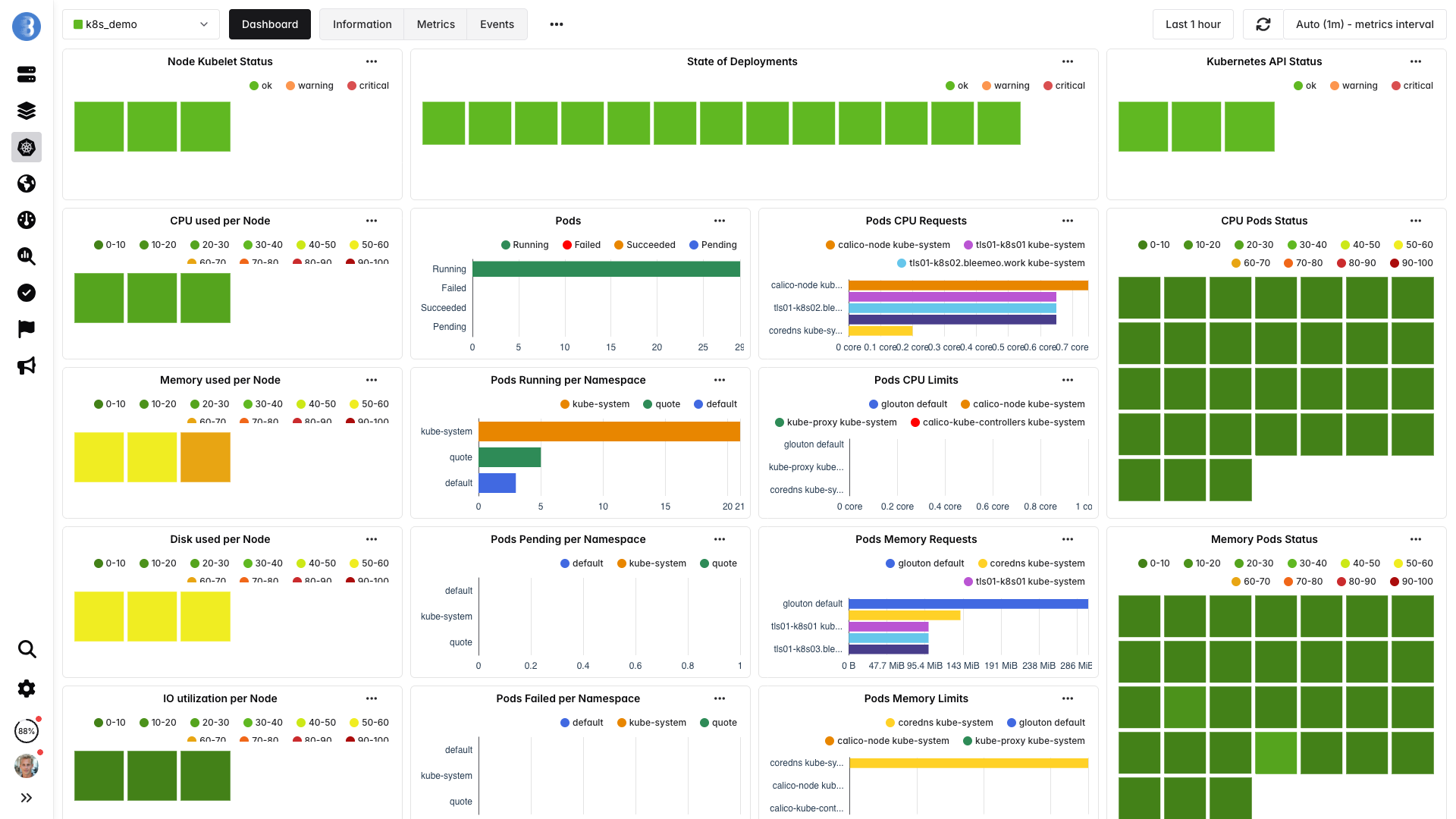
Warum automatische Erkennung in Kubernetes wichtig ist
In einer Kubernetes-Umgebung werden Workloads ständig erstellt, verschoben und zerstört. Manuelle Monitoring-Konfiguration kann nicht mithalten. Automatische Erkennung bedeutet, dass jedes neue Deployment, jede StatefulSet-Replik oder jeder CronJob-Pod sofort beim Start überwacht wird — ohne menschliches Eingreifen.
Dashboards & Alerts — Bereit
Vorgefertigte Dashboards und intelligente Alert-Regeln aktivieren sich, sobald Services erkannt werden. Sie monitoren in der Produktion — nicht bauen Sie eine Monitoring-Plattform.
- Cluster-Übersicht: Knotenanzahl, Pod-Status, Ressourcenauslastung
- Dashboards pro Pod: CPU, Speicher, Neustarts, Netzwerk
- Alert-Beispiele: Pod-Crash-Loops, hohe Knoten-CPU, Disk-Pressure
- Benachrichtigungen via Slack, Teams, PagerDuty, E-Mail, Webhooks
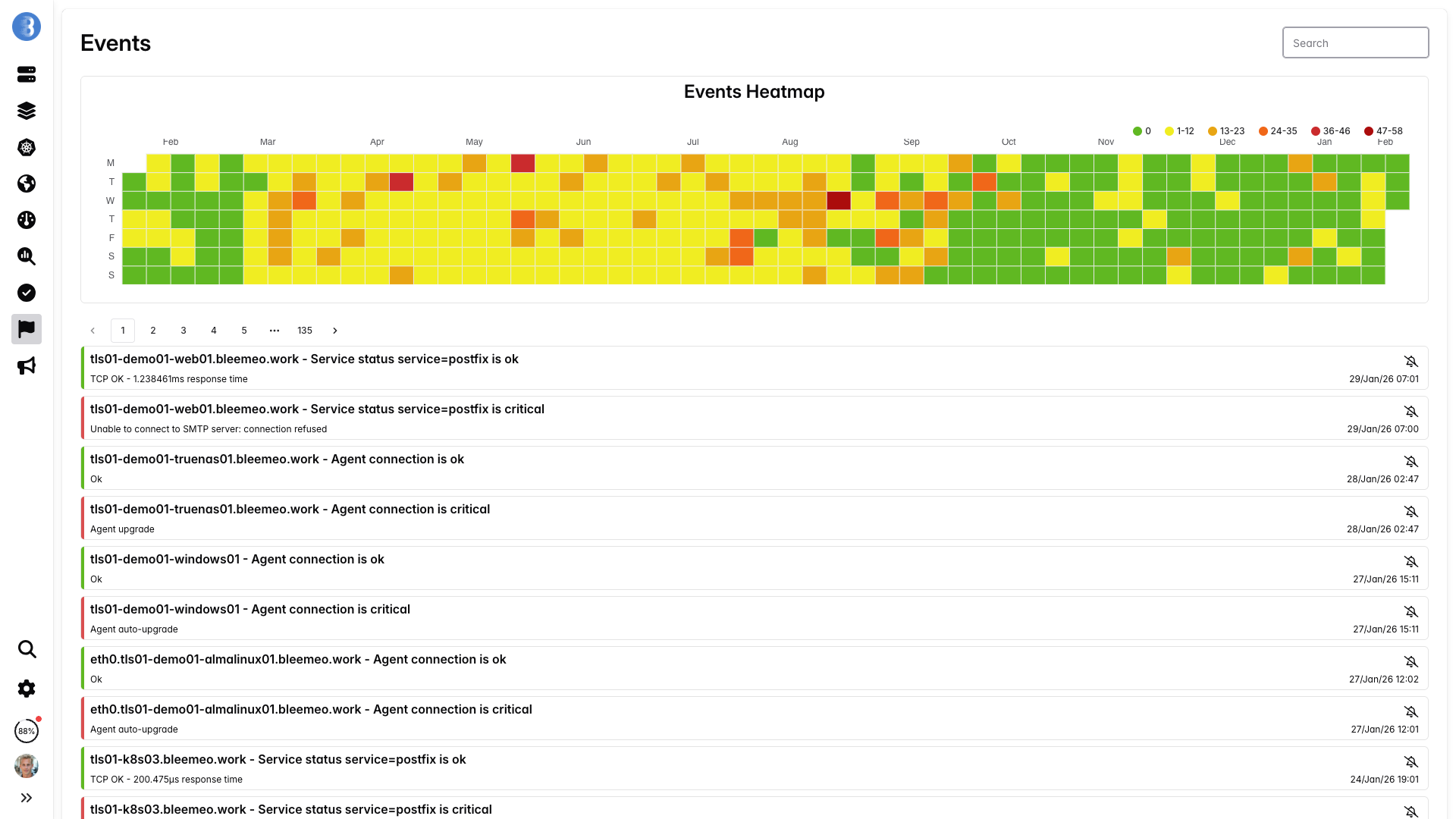
Warum vorgefertigte Alerts Ihnen Stunden sparen
Gute Kubernetes-Alert-Regeln von Grund auf zu schreiben ist überraschend schwer. Sie müssen Pod-Phasen, Container-Zustände, Ressourcen-Druck-Bedingungen handhaben und laute Fehlalarme während Rolling Deployments vermeiden. Bleemeo wird mit bewährten Standardwerten geliefert, damit Sie vom ersten Tag an zuverlässige Alerts haben — und Sie können sie jederzeit anpassen.
Was Sie sofort überwachen
Alles automatisch erkannt — keine benutzerdefinierten Abfragen, kein manuelles Setup.
Kubernetes führt mehrere Abstraktionsebenen ein — Cluster, Knoten, Pods, Container und die darin laufenden Services. Effektives Monitoring bedeutet, jede Ebene abzudecken, denn ein Problem auf einer Ebene (z.B. Disk-Pressure eines Knotens) kaskadiert in Symptome auf einer anderen (Pod-Evictions, Anwendungsfehler). Bleemeo überwacht all diese Ebenen sofort, damit Sie sowohl die Ursache als auch die Auswirkung in einem einzigen Dashboard sehen.
| Schicht | Wichtige Metriken | Beispiel-Alerts |
|---|---|---|
| Cluster | Knotenanzahl, Pod-Kapazität, Ressourcenzuweisung | Cluster-Knoten nicht bereit |
| Knoten | CPU, Speicher, Disk, Netzwerk pro Knoten | Knoten-CPU > 90%, Disk-Pressure |
| Pods | Status, Neustarts, CPU/Speicher-Requests vs. Nutzung | Pod-Crash-Loop, OOMKilled |
| Container | CPU-Throttling, Speicher-Limits, Dateisystem-I/O | Container-Speicher > 90% des Limits |
| Services | MySQL-Abfragen/s, Redis-Latenz, Nginx-Req/s usw. | Service-spezifische Schwellenwerte |
| Netzwerk | Bytes ein/aus, Paketfehler, DNS-Auflösung | Hoher Paketverlust, DNS-Fehler |
Warum Bleemeo für Kubernetes
Speziell entwickelt für dynamische, containerisierte Umgebungen.
Null Konfiguration
Keine Scrape-Configs, keine ServiceMonitors, keine Annotations. Glouton erkennt alles durch Überwachung der Kubernetes-API — neue Deployments werden automatisch monitoriert.
Sofortige Sichtbarkeit
Metriken erscheinen innerhalb von Sekunden nach dem Agent-Deployment. Vorgefertigte Dashboards bieten Ihnen Cluster-, Knoten- und Pod-Ansichten, ohne ein einziges Panel zu erstellen.
Multi-Cluster-fähig
Deployen Sie dasselbe Helm Chart auf Staging-, Produktions- und Edge-Clustern. Alle Daten fließen in eine einzige Oberfläche — keine Federation erforderlich.
Intelligente Alerts
Bewährte Alert-Regeln für Crash-Loops, OOMKills, Knoten-Pressure und mehr — aktiv ab der ersten Minute. Benachrichtigungen an Slack, Teams, PagerDuty oder E-Mail weiterleiten.
Leichtgewichtiger Agent
Glouton verbraucht weniger als 100 MB Speicher pro Knoten. Ressourcen-Limits sind im Helm Chart voreingestellt, sodass der Agent nie mit Ihren Workloads konkurriert.
Vollständige Stack-Abdeckung
Von der Cluster-Kapazität über CPU-Throttling pro Container bis hin zu Anwendungsmetriken wie MySQL-Abfragen oder Redis-Latenz — ein Agent deckt alles ab.
Bleemeo vs. DIY Prometheus-Stack
Was es wirklich braucht, um Kubernetes zu monitoren
| Aspekt | Prometheus DIY | Bleemeo |
|---|---|---|
| Einrichtungszeit | Tage bis Wochen | 10 Minuten |
| Konfiguration | Scrape-Configs, Recording Rules, Alert-Regeln | Null Konfiguration — automatische Erkennung |
| Dashboards | Von Grund auf in Grafana erstellen | Vorgefertigt, automatisch aktiviert |
| Speicher & Retention | Thanos/Cortex/Mimir verwalten | Vollständig verwaltet, inklusive |
| Hochverfügbarkeit | Duplizierte Stacks + Federation | Integrierte Redundanz |
| Neue Service-Unterstützung | Exporter finden, Scrape-Config hinzufügen | In Sekunden erkannt |
| Laufende Wartung | Versions-Upgrades, Kapazitätsplanung | Keine — vollständig verwaltetes SaaS |
Bereits in Prometheus investiert? Bleemeo ist für Prometheus-Nutzer gebaut — behalten Sie Ihre PromQL-Abfragen und Grafana-Dashboards, verlieren Sie die operationale Last.
Entwickelt für Prometheus-Nutzer
Sie nutzen bereits Prometheus? Bleemeo sammelt dieselben Metriken, die Sie kennen, und stellt sie über eine PromQL-kompatible Abfrageschnittstelle bereit. Behalten Sie Ihre bestehenden Grafana-Dashboards und Alerting-Logik — ohne die Prometheus-Infrastruktur selbst zu warten.
Mehr über Prometheus in der Cloud erfahrenVertraut von Teams, die Kubernetes in der Produktion betreiben
Ingenieure und CTOs vertrauen auf Bleemeo für ihr Infrastruktur-Monitoring
Während einer kurzen Mittagspause haben wir Bleemeo installiert, eine benutzerdefinierte Metrik erstellt, Alerts getestet und waren produktionsbereit. Die Geschwindigkeit der Bereitstellung ist bemerkenswert.

Der Bleemeo-Support ist schlicht legendär — schnell, kompetent und immer da, wenn wir ihn brauchen.
Bleemeo war unglaublich schnell einzurichten. In etwa einer Stunde haben wir es auf über 100 Servern ausgerollt und sofort volle Sicht auf unsere Infrastruktur erhalten.

Wir haben das Monitoring für alle unsere Server in nur wenigen Stunden eingerichtet. Das Dashboard ist übersichtlich, leistungsstark und macht wirklich Freude in der Nutzung.

Wir haben Bleemeo in nur wenigen Stunden auf unserer gesamten Server-Infrastruktur ausgerollt. Das Uptime-Monitoring benachrichtigt uns jetzt sofort, wenn ein Dienst ein Problem hat.

Unser Prometheus + Grafana-Stack war zu einem Wartungsprojekt geworden. Mit Bleemeo haben wir den Agenten in Minuten ausgerollt und uns endlich auf die Nutzung des Monitorings statt auf dessen Wartung konzentriert.
Nach der Installation des Agenten hat Bleemeo automatisch unsere Datenbanken, Container und Services erkannt. Innerhalb einer Stunde hatten wir volle Infrastruktur-Sichtbarkeit — ohne Dashboards oder Exporter bauen zu müssen.
Bleemeo hat mehrere Monitoring-Tools durch eine einzige Plattform ersetzt. Metriken, Alerts und Logs sind jetzt an einem Ort, was unserem Team erheblich Zeit spart.
Bleemeo gab uns sofortigen Einblick in unsere Infrastruktur ohne die übliche Komplexität. Innerhalb weniger Stunden liefen Metriken, Alerts und Dashboards reibungslos.
Die Einrichtung von Bleemeo war erfrischend einfach. Das Agent-Deployment dauerte Minuten und die automatische Erkennung ersparte uns Tage an Konfiguration.
Dank Bleemeo erkennt unser Team Probleme jetzt, bevor unsere Nutzer sie bemerken. Die Alerting-Funktion ist zuverlässig und die Oberfläche macht die Fehlersuche deutlich schneller.
Der Wechsel zu Bleemeo hat unseren Monitoring-Stack dramatisch vereinfacht. Statt mehrere Tools zu verwalten, ist alles, was wir brauchen, auf einer einzigen Plattform verfügbar.
Die Zentralisierung unserer Logs in Bleemeo hat die Fehlersuche drastisch vereinfacht. Statt zwischen Tools zu wechseln, können wir jetzt Metriken und Logs sofort korrelieren, um zu verstehen, was passiert.
Bleemeo hat das Kubernetes-Monitoring überraschend einfach gemacht. Innerhalb von Minuten hatten wir Einblick in unsere Cluster, Pods und Workloads, ohne komplexe Dashboards selbst bauen zu müssen.
Bereit, Kubernetes in 10 Minuten zu überwachen?
Ein Helm Chart. Vollständige Observability. Keine Wartung. Starten Sie noch heute Ihre kostenlose Testphase.
15 Tage kostenlos testen · Keine Kreditkarte erforderlich · Jederzeit kündbar
Häufig gestellte Fragen
Funktioniert Bleemeo mit verwalteten Kubernetes-Diensten wie EKS, GKE und AKS?
Ja. Bleemeo funktioniert mit jeder Kubernetes-Distribution, einschließlich Amazon EKS, Google GKE, Azure AKS und selbstverwalteten Clustern. Das Helm Chart deployt ein DaemonSet, das auf jedem Knoten läuft, unabhängig von der zugrunde liegenden Infrastruktur.
Wie erkennt Bleemeo neue Pods und Services?
Der Glouton-Agent überwacht die Kubernetes-API auf Pod-Lifecycle-Events. Wenn ein neuer Pod startet, erkennt Bleemeo automatisch die laufenden Services (Datenbanken, Webserver, Message Broker usw.) und beginnt mit der Metrik-Erfassung — ohne Annotation- oder Label-Konfiguration.
Kann ich Kubernetes-Metriken an mein bestehendes Prometheus-Setup senden?
Ja. Bleemeo sammelt dieselben Metriken, die Prometheus-Nutzer erwarten, und stellt sie über eine PromQL-kompatible Abfrageschnittstelle bereit. Sie können Ihre bestehenden Grafana-Dashboards und Alerting-Logik beibehalten. Mehr über Prometheus in der Cloud erfahren.
Welche Ressourcen verbraucht der Bleemeo-Agent?
Der Glouton-Agent ist von Natur aus leichtgewichtig. Er benötigt typischerweise weniger als 100 MB Speicher und minimale CPU. Ressourcen-Requests und -Limits sind im Helm Chart vorkonfiguriert, sodass der Agent Ihre Workloads nie beeinträchtigt.
Muss ich nach der Installation des Helm Charts etwas konfigurieren?
Nein. Nach dem Deployment erkennt Glouton automatisch Knoten, Pods, Container und Services. Dashboards und Alert-Regeln werden sofort aktiviert. Sie können optional Schwellenwerte anpassen oder Benachrichtigungskanäle hinzufügen, aber die Standardwerte decken die häufigsten Anwendungsfälle ab.
Kann ich mehrere Kubernetes-Cluster von einem einzigen Konto aus überwachen?
Ja. Installieren Sie das Helm Chart auf jedem Cluster mit denselben Kontodaten. Alle Cluster berichten an dasselbe Bleemeo-Dashboard und bieten Ihnen eine einheitliche Ansicht über Staging-, Produktions- und Edge-Umgebungen — ohne Federation-Setup.
Wie funktionieren Helm Chart-Upgrades?
Das Upgrade erfolgt mit einem einzigen Befehl: helm upgrade bleemeo-agent bleemeo/bleemeo-agent. Das DaemonSet führt ein Rolling Update durch, sodass Agent-Pods nacheinander ersetzt werden, ohne Monitoring-Lücken. Keine Daten gehen während des Upgrades verloren.
Kann Bleemeo auch Services außerhalb von Kubernetes überwachen?
Ja. Der Glouton-Agent von Bleemeo läuft auch auf Bare-Metal-Servern, virtuellen Maschinen und Cloud-Instanzen. Sie können Ihre gesamte Infrastruktur — Kubernetes und Nicht-Kubernetes — vom selben Dashboard mit denselben Alerting-Regeln überwachen.
Unterstützt Bleemeo Kubernetes-Namespace-Level-Monitoring?
Ja. Bleemeo gruppiert Metriken automatisch nach Namespace und bietet Ihnen Dashboards pro Namespace sowie die Möglichkeit, Alerts auf bestimmte Namespaces zu beschränken. Dies ist besonders nützlich für Multi-Tenant-Cluster, in denen Teams Einblick in ihre eigenen Workloads benötigen.
Was passiert, wenn ein Knoten ausfällt?
Wenn ein Knoten nicht mehr erreichbar ist, erkennt Bleemeo den Verlust des Heartbeats innerhalb von Minuten und löst Alerts aus. Alle Pods, die auf diesem Knoten liefen, werden markiert und ihr Status wird in Ihren Dashboards angezeigt. Sobald der Knoten wiederhergestellt ist oder Pods neu geplant werden, wird das Monitoring automatisch fortgesetzt.