IA & Machine Learning
Bleemeo integra l'intelligenza artificiale e il machine learning direttamente nel vostro flusso di monitoraggio — senza competenze in data science. Queste funzionalità sono operative fin da subito, analizzando le vostre metriche 24/7 per aiutare il vostro team a passare dalla risoluzione reattiva alle operazioni proattive.
Perché il monitoraggio guidato dall'IA è importante
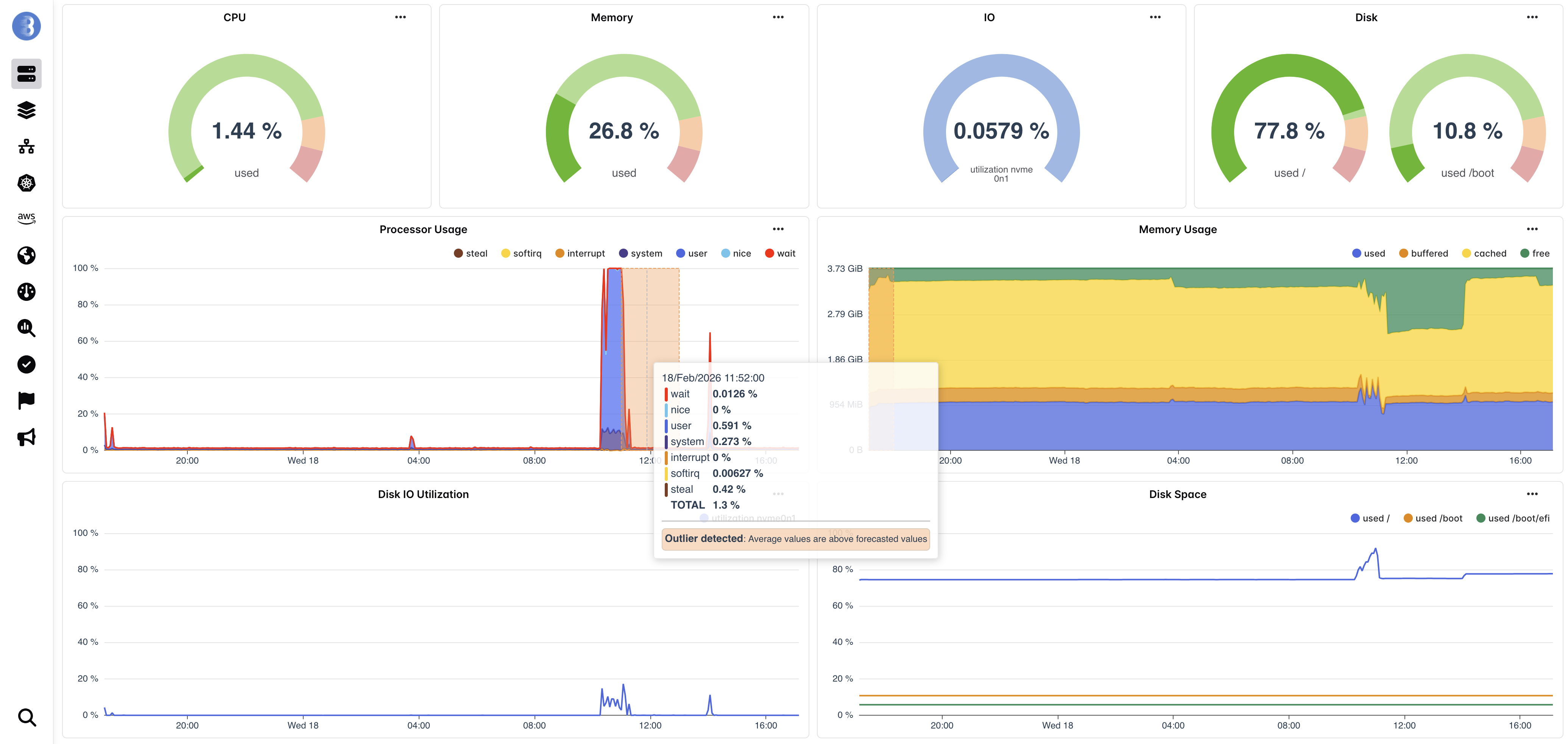
Il monitoraggio tradizionale si basa su soglie statiche: avvisare quando la CPU supera il 90%, quando la memoria scende sotto il 10%, quando l'utilizzo disco supera l'80%. Queste regole rigide generano un flusso costante di falsi positivi perché non distinguono tra un innocuo picco di backup notturno e un processo fuori controllo reale. I team imparano a ignorare gli alert, e quando emerge un problema reale, si perde nel rumore.
Rilevamento intelligente delle anomalie
Invece di chiedervi di definire cosa sia "normale" per ogni metrica su ogni server, i modelli di machine learning di Bleemeo lo apprendono automaticamente. Una rete neurale addestrata sul comportamento reale della vostra infrastruttura genera previsioni probabilistiche con intervalli di confidenza che si adattano ai pattern orari, cicli settimanali e tendenze stagionali. Quando una metrica esce da questi limiti dinamici, sapete che sta accadendo qualcosa di genuinamente insolito.
Pianificazione predittiva della capacità
Una delle cause più comuni di interruzioni dell'infrastruttura è l'esaurimento dello spazio disco. Bleemeo applica modelli di regressione lineare a 30 giorni di storico di utilizzo dello storage e calcola esattamente quando ogni partizione raggiungerà le soglie di avvertimento, critica e piena. Invece di scoprire un disco pieno alle 3 di notte quando un database si blocca, il vostro team riceve un preavviso di giorni o settimane — con il tempo per agire.
Infrastruttura conversazionale
Il server MCP di Bleemeo fa da ponte tra i vostri dati di monitoraggio e i moderni assistenti IA. Connettete Claude Desktop, Cursor, VS Code o Zed al vostro account e fate domande in linguaggio naturale: "Quali server hanno alert critici?", "Cosa è cambiato questa settimana?" Il server MCP fornisce accesso in sola lettura a oltre 26 strumenti di monitoraggio, trasformando la vostra piattaforma in un interlocutore che comprende la vostra infrastruttura.
Come l'IA migliora il vostro monitoraggio
Funzionalità guidate dall'IA
Previsione tramite reti neurali
Un modello transformer Amazon Chronos perfezionato analizza 7 giorni di storico delle metriche e genera previsioni probabilistiche con intervalli di confidenza. Il modello elabora 32 campioni di previsione per metrica per garantire limiti stabili e affidabili che si adattano al comportamento reale della vostra infrastruttura invece di basarsi su regole statiche.
Pianificazione predittiva della capacità
I modelli di regressione lineare analizzano 30 giorni di tendenze di utilizzo disco per calcolare esattamente quando le partizioni raggiungeranno le soglie di avvertimento (80%), critica (90%) e piena (100%). Ricevete alert anticipati multilivello con timestamp precisi — non avvertimenti vaghi, ma previsioni operative come "questo volume sarà pieno il 15 marzo".
Server MCP per assistenti IA
Connettete Claude Desktop, Cursor, VS Code o Zed al vostro account Bleemeo e interrogate la vostra infrastruttura in linguaggio naturale. Oltre 26 strumenti in sola lettura consentono agli assistenti IA di cercare agenti, servizi, container, eventi, log e piste di audit — trasformando i dati di monitoraggio in un'esperienza conversazionale.
Intelligenza senza configurazione
Le funzionalità di IA sono operative fin da subito senza configurazione manuale. Il sistema seleziona automaticamente le metriche rilevanti, addestra i modelli sui vostri dati, esegue le previsioni ogni 15 minuti e genera alert quando vengono rilevate anomalie. I modelli sottostanti sono stati perfezionati su metriche di infrastruttura reali per una precisione di livello produzione.
Riduzione dell'affaticamento da alert
I limiti di previsione dinamici si adattano ai pattern giornalieri e settimanali, eliminando i falsi positivi causati da variazioni di carico prevedibili. Invece di avvisare per un picco di CPU del backup notturno che si verifica ogni giorno, l'IA di Bleemeo riconosce il pattern come normale e si attiva solo quando viene osservato un comportamento genuinamente insolito.
Apprendimento continuo
I modelli vengono rivalutati ogni 15 minuti con dati aggiornati, affinché le previsioni restino attuali mentre la vostra infrastruttura evolve. Quando distribuite nuovi servizi, scalate la capacità o modificate i pattern di traffico, l'IA adatta automaticamente le sue previsioni per riflettere la nuova normalità in poche ore, senza ricalibrazione manuale.
Rilevamento anomalie con reti neurali
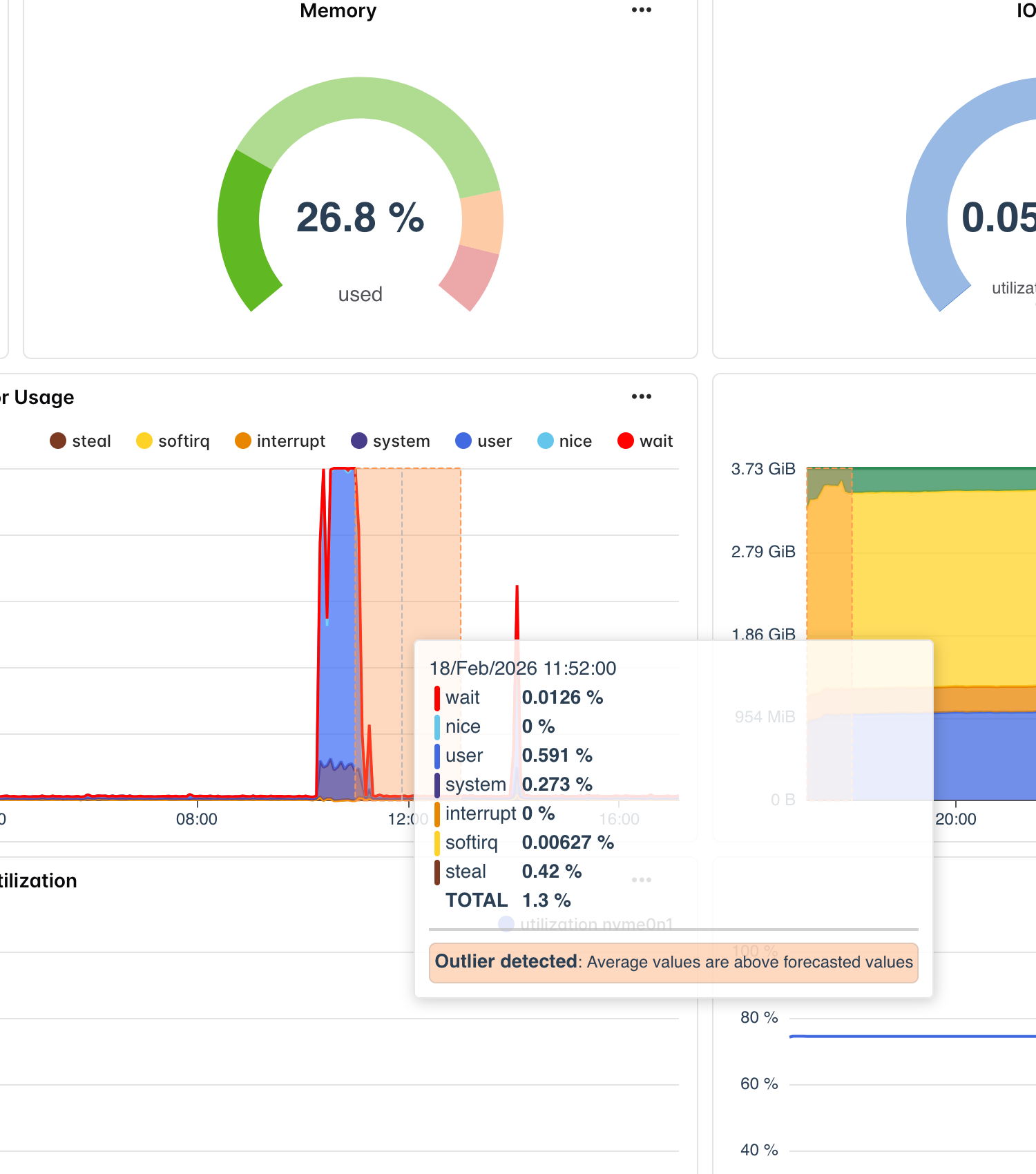
Il motore di rilevamento delle anomalie di Bleemeo è alimentato da una versione perfezionata del modello Chronos-t5 di Amazon, un'architettura basata su transformer progettata specificamente per la previsione di serie temporali. A differenza dei semplici controlli di soglia che confrontano una metrica con un valore fisso, il modello Chronos genera previsioni probabilistiche con limiti di confidenza alto e basso che riflettono l'intervallo di comportamento atteso per ogni metrica in ogni momento.
Il modello opera su una finestra di contesto di 7 giorni, utilizzando 168 ore di dati storici delle metriche campionati a intervalli orari per produrre previsioni a 25 punti. Ogni previsione rappresenta la stima del modello su dove la metrica dovrebbe trovarsi, accompagnata da intervalli di confidenza che catturano la variazione naturale. Quando i valori effettivi cadono consistentemente al di fuori di questi limiti, Bleemeo genera un alert di anomalia che rappresenta una deviazione statisticamente significativa dal comportamento atteso — non semplicemente una metrica che attraversa un numero definito mesi fa.
- Limiti di confidenza probabilistici
Ogni previsione include limiti alto e basso derivati da 32 campioni d'insieme. Il divario tra i limiti viene calibrato automaticamente utilizzando la deviazione standard della metrica più una tolleranza configurabile, garantendo che gli alert siano sufficientemente sensibili per rilevare problemi reali senza segnalare la varianza normale.
- Resistente ai dati mancanti
Le metriche di infrastruttura non sono sempre perfettamente continue. Interruzioni di rete, riavvii degli agenti e finestre di manutenzione creano lacune. Il modello Chronos gestisce fino al 90% di punti dati mancanti, generando previsioni valide anche con dati storici sparsi grazie alla capacità dell'architettura transformer di sfruttare il contesto disponibile.
- Perfezionato su infrastruttura reale
Il modello base Chronos è stato perfezionato con metriche reali dei clienti Bleemeo, coprendo pattern come cicli di utilizzo CPU, tendenze di allocazione memoria, pattern di throughput di rete e profili di I/O disco. Questo addestramento specifico del dominio produce previsioni significativamente più precise rispetto ai modelli generici di serie temporali.
- Selezione automatica delle metriche
Bleemeo identifica automaticamente quali metriche beneficiano del rilevamento delle anomalie e configura la previsione senza intervento manuale. Il requisito minimo di 60 punti dati garantisce che le previsioni vengano generate solo quando esiste uno storico sufficiente per un'analisi significativa.
Previsione disco pieno
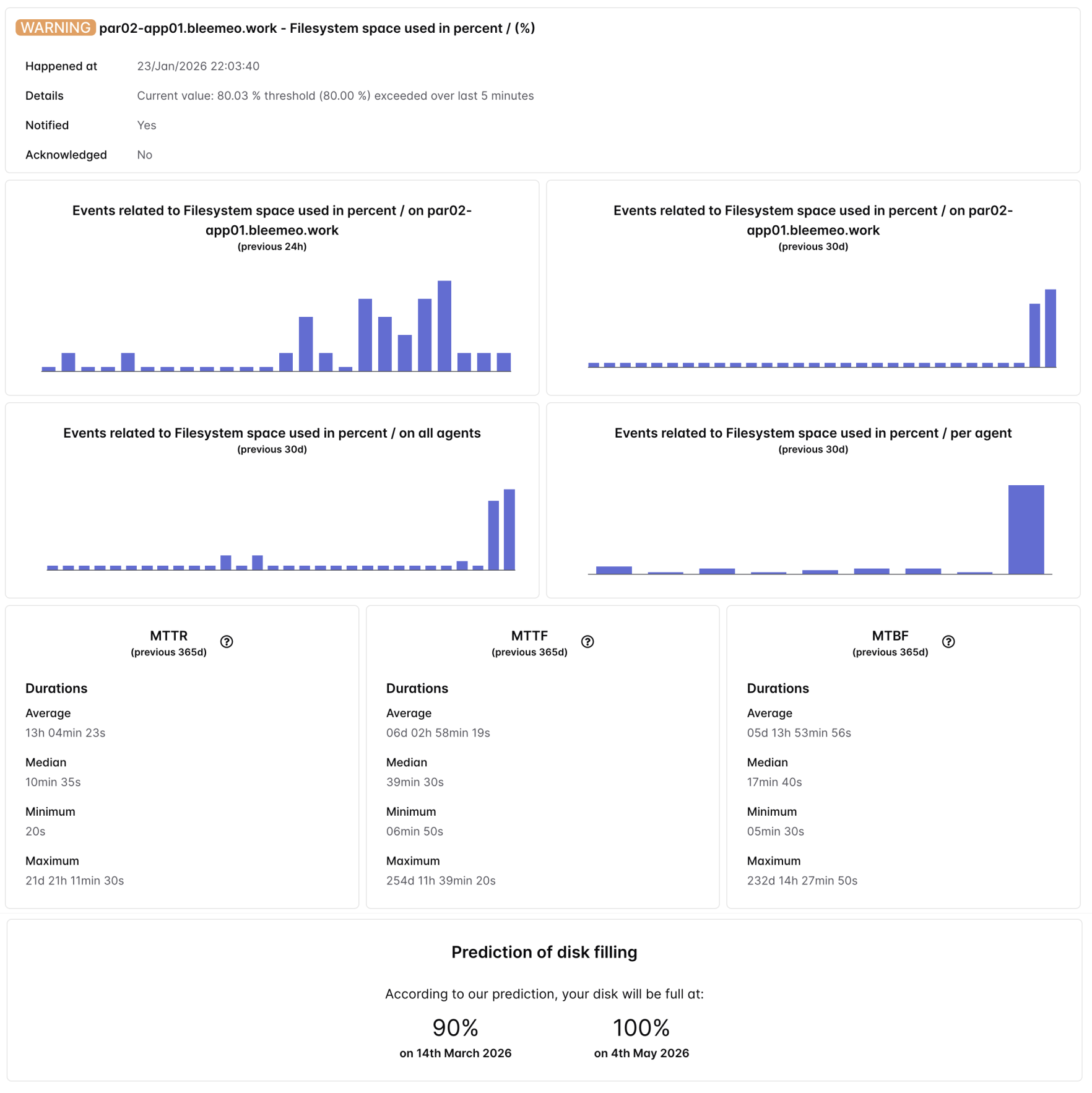
L'esaurimento dello spazio disco resta una delle principali cause di downtime imprevisto. I database si bloccano, i file di log smettono di scrivere, le applicazioni falliscono con errori criptici e i backup si interrompono silenziosamente. Il danno spesso si estende oltre l'interruzione immediata — dati corrotti, transazioni incomplete e guasti a cascata sui servizi dipendenti. Eppure l'esaurimento disco è quasi sempre prevenibile con un preavviso sufficiente.
Il sistema di previsione disco pieno di Bleemeo analizza 30 giorni di storico di utilizzo dello storage per ogni partizione monitorata e adatta un modello di regressione lineare per proiettare la crescita futura. Il modello calcola la pendenza (tasso di crescita per unità di tempo) e la utilizza per determinare esattamente quando la partizione attraverserà tre soglie configurabili: avvertimento all'80% di capacità, critica al 90% e piena al 100%. Ogni previsione restituisce un timestamp ISO-8601 specifico — non un vago avvertimento "spazio in esaurimento", ma una data esatta come "questa partizione raggiungerà il 90% di capacità il 3 aprile 2026 alle 14:30 UTC".
- Previsioni a tre livelli di soglia
Ricevete avvertimenti anticipati ai livelli di avvertimento (80%), critico (90%) e pieno (100%). Ogni soglia genera il proprio timestamp previsto, consentendovi di prioritizzare la risposta: pianificare la pulizia nella fase di avvertimento, programmare l'espansione nella fase critica ed escalare nella fase di disco pieno.
- Previsioni con timestamp preciso
Invece di avvertimenti approssimativi, Bleemeo fornisce date e orari esatti per quando ogni soglia verrà raggiunta. Questo consente una pianificazione precisa della capacità — sapete se disponete di ore, giorni o settimane per rispondere, e potete pianificare di conseguenza senza panico.
- Analisi delle tendenze a 30 giorni
Il modello utilizza un mese completo di punti dati orari per adattare la regressione, smussando le fluttuazioni giornaliere e catturando la vera tendenza di crescita sottostante. Questa lunga baseline produce previsioni stabili e affidabili che non vengono distorte da picchi temporanei di rotazione dei log o invalidazione della cache.
- Copertura automatica
Ogni partizione disco monitorata viene automaticamente iscritta alla pianificazione predittiva della capacità. Non appena l'agente Glouton inizia a riportare metriche disco, il sistema di previsione inizia ad accumulare storico e generare previsioni — nessuna configurazione per server o per partizione necessaria.
Server MCP: parlate con la vostra infrastruttura
Interrogate i vostri dati di monitoraggio in linguaggio naturale tramite il vostro assistente IA preferito
Il server MCP (Model Context Protocol) di Bleemeo connette la vostra piattaforma di monitoraggio al mondo degli assistenti IA. Una volta configurato, potete fare domande sulla vostra infrastruttura in linguaggio naturale e ricevere risposte istantanee e contestuali basate su dati di monitoraggio in tempo reale. Non è necessario imparare linguaggi di query, navigare dashboard complesse o scrivere script personalizzati — descrivete semplicemente cosa volete sapere, e l'assistente IA interroga Bleemeo per voi.
Il server MCP espone oltre 26 strumenti in sola lettura che coprono ogni aspetto dei vostri dati di monitoraggio. Gli assistenti IA possono elencare tutti gli agenti distribuiti e il loro stato, recuperare dettagli sulla salute dei servizi, controllare le metriche dei container, interrogare eventi e alert, cercare globalmente in tutte le risorse, ispezionare i log di audit e persino elencare le fatture. Tutti gli accessi sono autenticati tramite OAuth e strettamente in sola lettura — il server MCP non può creare, modificare o eliminare alcuna risorsa del vostro account Bleemeo, garantendo la sicurezza della vostra infrastruttura consentendo al contempo un'analisi potente guidata dall'IA.
Salute dell'infrastruttura
Chiedete al vostro assistente IA "Qual è lo stato generale della mia infrastruttura?" e ottenete un riepilogo completo degli stati dei server, alert attivi, disponibilità dei servizi e utilizzo delle risorse su tutta la vostra flotta. Il server MCP interroga simultaneamente agenti, eventi e servizi per costruire un quadro completo.
- Elencare e ispezionare gli agenti
- Interrogare eventi e alert attivi
- Controllare lo stato di salute dei servizi
- Ricerca globale nelle risorse
Risoluzione problemi e analisi
Durante un incidente, chiedete "Quali servizi hanno alert critici in questo momento?" o "Cosa è cambiato nell'ultima ora?" L'assistente IA incrocia dati di alert, eventi recenti, log di audit e stati dei container per aiutarvi a identificare le cause radice più velocemente rispetto alla navigazione manuale di molteplici viste dashboard.
- Consultare i log dell'infrastruttura
- Ispezionare stato e metriche dei container
- Accedere alla pista di audit delle modifiche
- Esaminare i risultati degli healthcheck
Monitoraggio conversazionale
Andate oltre le query semplici con domande di approfondimento. Iniziate con "Mostrami i miei agenti Kubernetes" e poi approfondite: "Quale ha il maggior utilizzo CPU?", "Quali servizi girano su quel nodo?", "Ci sono alert recenti per lui?" L'IA mantiene il contesto durante tutta la conversazione.
- Elencare i tipi di agenti (AWS, K8s, SNMP)
- Recuperare fatti e metadati degli agenti
- Elencare applicazioni e dettagli
- Interrogare la configurazione Glouton
Assistenti IA compatibili
Il server MCP si integra con i principali strumenti di sviluppo IA. L'autenticazione avviene tramite OAuth — lanciate la connessione MCP, autorizzate nel browser, selezionate il vostro account Bleemeo e siete pronti per interrogare. Ogni piattaforma fornisce la gestione degli strumenti per attivare o disattivare funzionalità specifiche.
- Claude Desktop (strumenti + prompt)
- Cursor (strumenti)
- Visual Studio Code (strumenti)
- Zed (strumenti)
Perché il monitoraggio con IA aiuta il vostro team
Il vero valore dell'IA nel monitoraggio non è la tecnologia in sé — è la trasformazione operativa che consente. I team che utilizzano le funzionalità di IA di Bleemeo riportano costantemente meno alert notturni, tempi di risoluzione degli incidenti più brevi e una pianificazione della capacità più efficace. Ecco come ogni funzionalità si traduce in risultati concreti per il business.
Il rilevamento delle anomalie elimina le congetture sulla regolazione delle soglie. Ogni team SRE ha dedicato ore a discutere se l'alert CPU debba scattare all'85% o al 90%, solo per scoprire che entrambi i valori generano rumore durante i picchi prevedibili. Con limiti guidati dall'IA, questi dibattiti scompaiono. Il modello apprende che il 95% di CPU alle 2 di notte durante l'ETL notturno è normale, mentre il 75% di CPU a mezzogiorno di un martedì è insolito. Il vostro team risponde agli alert che contano e ignora quelli che non contano, senza toccare una singola configurazione di soglia.
La previsione disco pieno trasforma la risoluzione reattiva in manutenzione pianificata. Il costo medio di un'interruzione da disco pieno non è solo il downtime — include il recupero dati, il replay delle transazioni, l'impatto sui clienti e l'indagine post-mortem. Bleemeo trasforma questa emergenza in un'attività programmata. Quando sapete che un volume raggiungerà la capacità il 15 marzo, potete ordinare storage, programmare l'espansione durante una finestra di manutenzione o implementare politiche di retention — il tutto durante l'orario lavorativo senza impatto sui clienti.
Il server MCP rende il monitoraggio accessibile a tutti nel team. Non tutti in un team parlano PromQL o sanno dove trovare la dashboard giusta durante un incidente. Con l'accesso conversazionale ai dati di monitoraggio, un product manager può verificare la salute di un servizio, uno sviluppatore può indagare l'impatto di un deployment e un ingegnere di turno può classificare gli alert — il tutto in linguaggio naturale. Questo democratizza l'intelligenza operativa senza richiedere che tutti diventino esperti di monitoraggio.
Volete approfondire? Scoprite come configurare il server MCP con il vostro assistente IA, comprendere le soglie di rilevamento delle anomalie e impostare gli alert di previsione disco pieno.
Consulta la documentazioneDomande frequenti
Tutto ciò che dovete sapere sulle funzionalità di IA e machine learning di Bleemeo
Quali funzionalità di IA e machine learning offre Bleemeo?
Bleemeo offre tre funzionalità principali di IA/ML: il rilevamento delle anomalie basato su reti neurali con un modello transformer perfezionato, la pianificazione predittiva della capacità con previsione di disco pieno tramite regressione lineare, e un server MCP che permette di interrogare i dati di monitoraggio tramite assistenti IA come Claude Desktop, Cursor e VS Code. Tutte le funzionalità funzionano automaticamente senza alcuna configurazione.
Come funziona il rilevamento delle anomalie di Bleemeo?
Bleemeo utilizza un modello transformer Amazon Chronos perfezionato per analizzare 7 giorni di dati storici delle metriche e generare previsioni probabilistiche con intervalli di confidenza. Il modello produce 32 campioni di previsione per metrica per garantire limiti stabili. Quando i valori effettivi escono dall'intervallo previsto, viene rilevata un'anomalia. Il modello viene eseguito ogni 15 minuti e gestisce fino al 90% di punti dati mancanti.
Con quanto anticipo Bleemeo può prevedere un disco pieno?
Bleemeo analizza 30 giorni di tendenze di utilizzo disco tramite regressione lineare per proiettare quando lo storage raggiungerà le soglie di avvertimento (80%), critica (90%) e piena (100%). A seconda del tasso di crescita, le previsioni possono spaziare da giorni a mesi, con timestamp ISO-8601 specifici per ogni attraversamento di soglia.
Cos'è il server MCP di Bleemeo?
Il server MCP di Bleemeo implementa il Model Context Protocol, consentendo agli assistenti IA di interrogare i dati di monitoraggio in linguaggio naturale. Fornisce oltre 26 strumenti in sola lettura che coprono agenti, servizi, container, eventi, log e piste di audit. L'autenticazione utilizza OAuth, e tutti gli accessi sono strettamente in sola lettura per la sicurezza.
Quali assistenti IA sono compatibili con il server MCP?
Il server MCP di Bleemeo supporta Claude Desktop (supporto completo con strumenti e prompt), Cursor (solo strumenti), Visual Studio Code (solo strumenti) e Zed (solo strumenti). Ogni piattaforma fornisce la gestione degli strumenti per attivare o disattivare funzionalità specifiche secondo necessità.
L'accesso al server MCP è in sola lettura?
Sì, il server MCP di Bleemeo è interamente in sola lettura. Può interrogare e recuperare dati — metriche, alert, log, eventi, configurazioni e piste di audit — ma non può creare, modificare o eliminare alcuna risorsa del vostro account Bleemeo. Questo design garantisce che la vostra infrastruttura rimanga completamente sicura consentendo al contempo un'analisi potente guidata dall'IA.
È necessario configurare qualcosa per il rilevamento delle anomalie?
No. Il rilevamento delle anomalie di Bleemeo funziona immediatamente senza alcuna configurazione. Il sistema seleziona automaticamente le metriche appropriate, raccoglie i dati storici, esegue le previsioni ogni 15 minuti e genera alert quando vengono rilevate anomalie. Il modello sottostante è stato perfezionato su metriche di infrastruttura reali per una precisione ottimale.
Quali modelli di machine learning utilizza Bleemeo?
Bleemeo utilizza due modelli complementari: un transformer Amazon Chronos-t5 perfezionato per previsioni probabilistiche di serie temporali e rilevamento delle anomalie, e un modello di regressione lineare ottimizzato per la pianificazione della capacità e la previsione di disco pieno. Il modello Chronos utilizza PyTorch e Hugging Face Transformers per l'inferenza delle reti neurali.
Come riduce l'affaticamento da alert il monitoraggio guidato dall'IA?
Gli alert tradizionali basati su soglie si attivano su valori fissi che ignorano le variazioni normali. L'IA di Bleemeo apprende i pattern reali della vostra infrastruttura — cicli giornalieri, tendenze settimanali, cambiamenti stagionali — e avvisa solo quando il comportamento devia genuinamente dall'intervallo previsto. Questo elimina i falsi positivi causati da picchi di carico prevedibili, job notturni e elaborazioni batch di routine.
Quali piani Bleemeo includono le funzionalità di IA e ML?
Il server MCP è disponibile nei piani Free, Starter e Professional. Il rilevamento delle anomalie e la pianificazione predittiva della capacità sono disponibili nei piani Starter e Professional. Tutte le funzionalità funzionano automaticamente, senza configurazione, impostazioni o costi aggiuntivi oltre all'abbonamento.
Iniziate il monitoraggio con l'intelligenza artificiale
Rilevamento anomalie, previsioni di capacità e monitoraggio conversazionale — tutto attivo dal primo giorno. Iniziate la vostra prova gratuita di 15 giorni con accesso completo alle funzionalità di IA e scoprite come il machine learning trasforma le vostre operazioni infrastrutturali.