Eine Managed Alternative zu selbst gehostetem Prometheus
Prometheus ist der Standard für Metriken, aber der Produktionsbetrieb bedeutet Alertmanager, Grafana, Langzeitspeicherung und Kapazitätsplanung zu verwalten. Bleemeo bietet Ihnen dieselbe Sichtbarkeit ohne Server zu betreiben und ohne nächtliche Alarme wegen Ihres Monitoring-Stacks.
15 Tage kostenlos · Keine Kreditkarte erforderlich · Immer vorhersehbare Preise
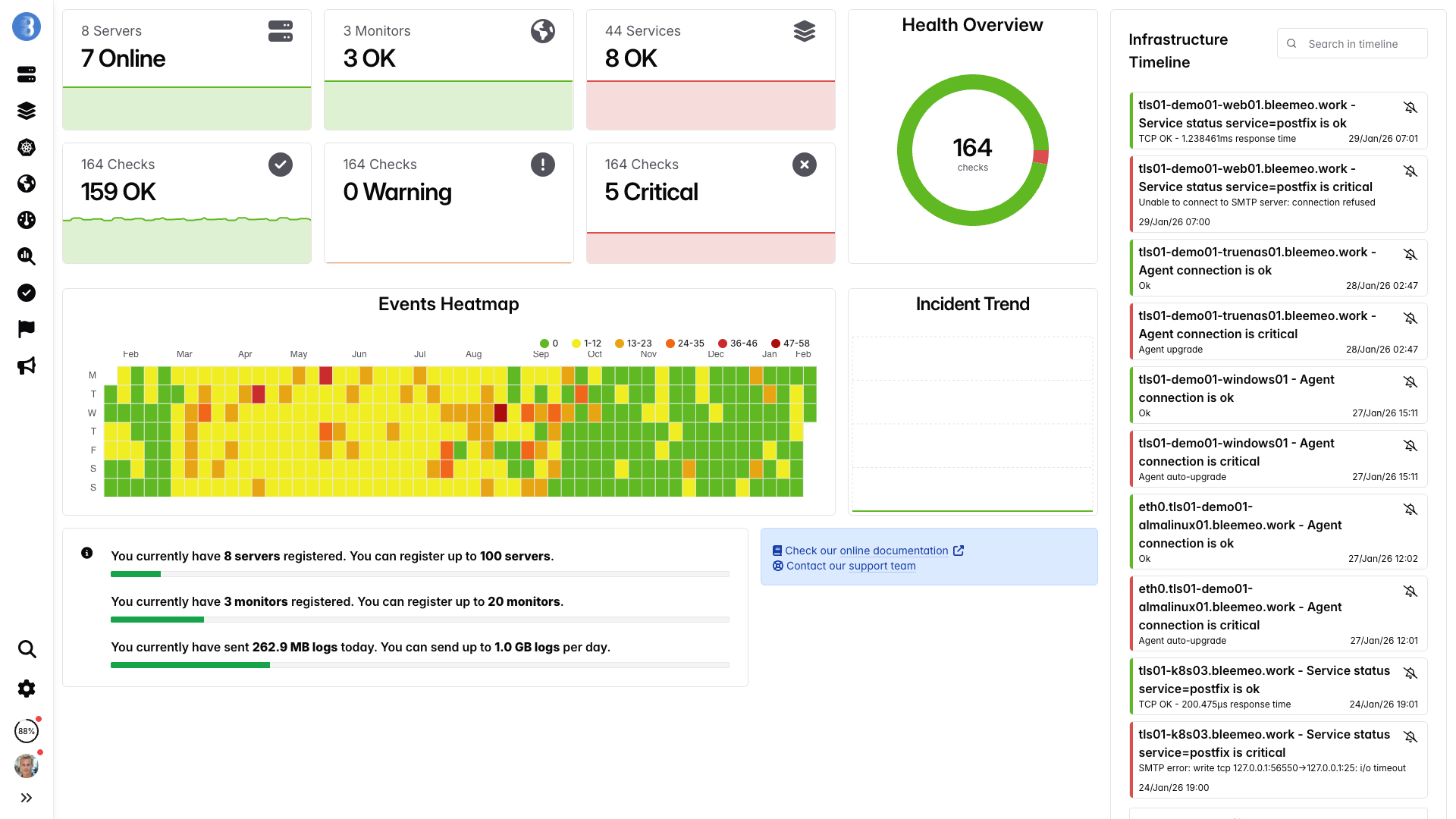
Echtzeit-Dashboards, in Minuten einsatzbereit — keine Konfiguration nötig
Häufige Prometheus-Herausforderungen
Infrastruktur-Overhead
Prometheus im großen Maßstab zu betreiben bedeutet mehrere Prometheus-Instanzen zu warten, Federation oder Sharding zu konfigurieren und Pipelines zum Datentransfer zwischen Komponenten aufzubauen. Jede zusätzliche Instanz erfordert eigene Ressourcenzuweisung, Scrape-Konfiguration und Recording-Regeln — ein Betriebsaufwand, der linear mit Ihrer Infrastruktur wächst.
Speicher-Komplexität
Prometheus hat standardmäßig nur 15 Tage Aufbewahrung, was bedeutet, dass jede historische Analyse oder Kapazitätsplanung eine separate Langzeitspeicherlösung erfordert. Thanos, Cortex und Mimir lösen dieses Problem jeweils, führen aber ihre eigene Architektur, Object-Storage-Abhängigkeiten und Compaction-Prozesse ein, die sorgfältige Abstimmung und Überwachung benötigen.
Dashboard- & Alert-Einrichtung
Prometheus wird nur mit einem einfachen Expression-Browser ausgeliefert — keine integrierten Dashboards oder polierte UI. Sie benötigen Grafana für die Visualisierung und Alertmanager für Benachrichtigungen, beides erfordert manuelle Einrichtung. Jedes Dashboard-Panel, jede Alerting-Regel und jede Recording-Regel muss von Hand in PromQL geschrieben und per Versionskontrolle gepflegt werden.
Skalierungs-Herausforderungen
Metriken mit hoher Kardinalität aus dynamischen Umgebungen wie Kubernetes können plötzliche Speicherspitzen und OOM-Kills verursachen, die Ihren gesamten Monitoring-Stack lahmlegen. Die Skalierung von Prometheus erfordert Sharding über mehrere Instanzen oder das Aufsetzen von Federation-Hierarchien, und Aufbewahrungsrichtlinien müssen sorgfältig gegen den verfügbaren Speicherplatz abgewogen werden.
Prometheus vs Bleemeo
| Funktion | Prometheus (selbst gehostet) | Bleemeo |
|---|---|---|
| Einrichtungszeit | Stunden bis Tage Konfiguration | 5 Minuten, ein Befehl |
| Benötigte Infrastruktur | Prometheus + Alertmanager + Grafana + Speicher | Keine — vollständig verwaltetes SaaS |
| Langzeitspeicherung | Thanos/Cortex/Mimir erforderlich | 13 Monate inklusive |
| Service-Erkennung | Manuelle Scrape-Konfiguration pro Ziel | Automatisch, keine Konfiguration |
| Dashboards | In Grafana von Grund auf erstellen | Vorgefertigt, automatisch aktiviert |
| Alert-Regeln | PromQL-Regeln schreiben und pflegen | Intelligente Standardwerte + ML-Anomalie-Erkennung |
| Hochverfügbarkeit | Doppelte Stacks + Federation | Eingebaute Redundanz |
| Wartung | Upgrades, Skalierung, Fehlerbehebung | Keine — wir kümmern uns um alles |
| Netzwerkmodell | Pull-basiert: erfordert Netzwerkzugang zu allen Zielen | Push-basiert: Agents senden Daten ausgehend, keine eingehenden Ports nötig |
| Kardinalitäts-Management | Hohe Kardinalität verursacht Speicherdruck und OOM-Kills | Serverseitig verwaltet mit automatischer Kardinalitätskontrolle |
| Log-Management | Nicht enthalten — erfordert Loki oder separaten Stack | Integrierte Log-Erfassung und -Suche neben Metriken |
| PromQL-Kompatibilität | Nativ | Prometheus-kompatible Metriken |
| Open-Source-Agent | Prometheus-Exporter | Glouton (Apache 2.0) |
Echter Kostenvergleich
Für eine typische 100-Server-Infrastruktur mit selbst gehostetem Prometheus gehen die wahren Kosten weit über Compute und Speicher hinaus — sie umfassen die Ingenieurstunden für Wartung, Fehlerbehebung und Skalierung Ihres Monitoring-Stacks anstelle der Entwicklung von Produktfunktionen.
Prometheus (selbst gehostet)
*Plus versteckte Kosten: Bereitschafts-Ermüdung, Wissens-Silos und Opportunitätskosten durch Ingenieure, die nicht am Produkt arbeiten
Bleemeo
*Mit 1-Jahres-Reservierung. Keine Infrastrukturkosten.
Warum Teams Bleemeo wählen
Keine Infrastruktur
Keine Prometheus-Server zu warten, keine Thanos-Cluster zu betreuen, keine Grafana-Instanzen zu aktualisieren und keine Object-Storage-Buckets zu verwalten. Bleemeo übernimmt die gesamte Infrastruktur, damit Ihr Team sich auf die Produktentwicklung konzentrieren kann. Sie müssen sich nie wieder um Speicherplatz, Speicherdruck oder OOM-Kills in Ihrer Observability-Schicht sorgen.
Prometheus-kompatibel
Glouton scrapt Prometheus-Exporter direkt und lässt Ihre bestehenden Exporter und Instrumentierungscode unverändert. Bleemeo unterstützt dieselben Prometheus-kompatiblen Metrik-Formate und Labels, die Sie bereits verwenden, und ist damit ein direkter Ersatz für Ihr Prometheus-Backend ohne eine einzige Recording-Regel oder Relabeling-Konfiguration umzuschreiben.
Automatische Erkennung
Anders als Prometheus, das manuelle Scrape-Konfiguration für jedes neue Ziel erfordert, erkennt Bleemeos Agent Glouton automatisch laufende Services — Datenbanken, Webserver, Message Broker und mehr — und beginnt sofort mit der Erfassung der richtigen Metriken. Kein YAML bearbeiten, keine Service-Discovery-Plugins, keine Relabeling-Regeln zu pflegen.
Alles vorgefertigt
Während Prometheus Ihnen nur einen einfachen Expression-Browser bietet, liefert Bleemeo umfangreiche vorgefertigte Dashboards, intelligente Alerting-Schwellenwerte und ML-basierte Anomalie-Erkennung, die sich automatisch aktivieren, sobald ein Service erkannt wird. Kein tagelanger Aufwand mehr für Grafana-Panels oder das Schreiben von PromQL-Alerting-Regeln von Grund auf.
Open-Source-Agent
Glouton, unser Monitoring-Agent, ist vollständig Open Source unter der Apache 2.0 Lizenz. Sie können jede Codezeile auf Ihren Servern prüfen, Verbesserungen beitragen und sicher sein, dass kein Vendor Lock-in besteht. Ihre Metrikdaten gehören Ihnen, und Sie können sie jederzeit im Standard-Prometheus-Format exportieren.
Europäische Datenresidenz
Alle Ihre Monitoring-Daten werden in europäischen Rechenzentren gespeichert, mit voller DSGVO-Konformität von Anfang an. Anders als US-basierte SaaS-Alternativen ist Bleemeo ein europäisches Unternehmen, das Ihre Infrastruktur-Telemetrie unter EU-Gerichtsbarkeit hält, was die Einhaltung von Datenresidenz-Anforderungen vereinfacht.
Feature-Parität wo es zählt
Infrastruktur-Monitoring
Umfassende CPU-, Speicher-, Festplatten-, Netzwerk- und Prozess-Überwachung mit automatischer Service-Erkennung, die Datenbanken, Webserver und Anwendungs-Laufzeiten ohne jegliche Konfiguration erkennt. Erhalten Sie tiefere Einblicke als Standard-Prometheus-node_exporter-Metriken direkt nach der Installation.
Container & Kubernetes
Native Docker- und Kubernetes-Unterstützung mit Pod-Level-Metriken, Node-Health-Monitoring und clusterweiten Übersichten. Anders als Prometheus, das kube-state-metrics, cAdvisor und komplexe Relabeling-Regeln erfordert, bietet Bleemeo Container-Monitoring, das sofort nach der Agent-Installation funktioniert.
Log-Management
Erfassen, indizieren und durchsuchen Sie Logs neben Ihren Metriken in einer einzigen vereinheitlichten Plattform. Prometheus hat keinerlei Log-Management — Teams nutzen typischerweise Loki, Elasticsearch oder Splunk als weiteres zu verwaltendes System. Mit Bleemeo leben Logs und Metriken zusammen, was die Ursachenanalyse schneller und einfacher macht.
Intelligentes Alerting
Machine-Learning-basierte Anomalie-Erkennung identifiziert ungewöhnliche Muster bevor sie zu Ausfällen werden, ergänzt durch vorkonfigurierte Alert-Schwellenwerte für jeden erkannten Service. Kein manuelles Schreiben und Tunen von PromQL-Alerting-Regeln oder Pflegen von Alertmanager-Routing-Bäumen mehr.
Benutzerdefinierte Dashboards
Erstellen Sie genau die Ansichten, die Ihr Team braucht, mit intuitiven Drag-and-Drop-Widgets, oder starten Sie mit der umfangreichen Bibliothek vorgefertigter Dashboards, die sich automatisch aktivieren. Anders als bei Grafana, wo jedes Panel manuelle PromQL-Abfragen und JSON-Konfiguration erfordert, sind Bleemeo-Dashboards sofort einsatzbereit.
Uptime-Monitoring
HTTP-, TCP- und ICMP-Uptime-Checks von mehreren globalen Standorten, mit SSL-Zertifikats-Ablaufüberwachung und Antwortzeit-Tracking. Prometheus blackbox_exporter bietet grundlegendes Probing, aber Bleemeo bietet einen vollständig verwalteten, Multi-Standort-Ansatz mit integriertem Alerting und Statusseiten ohne eigene Infrastruktur.
Migration von Prometheus
Die meisten Teams betreiben beide Systeme einige Wochen parallel, bevor sie vollständig wechseln. Die Migration ist unkompliziert und unterbrechungsfrei — Bleemeo-Agents laufen neben Ihrem bestehenden Prometheus-Setup ohne Konflikte. Unser Team steht bei jedem Schritt für Migrationsplanung und Validierung zur Verfügung.
Bleemeo-Agents bereitstellen
Installieren Sie den Bleemeo-Agent neben Ihren bestehenden Prometheus-Exportern mit einem einzigen Befehl. Der Agent läuft unabhängig und stört Ihren aktuellen Monitoring-Stack nicht, sodass es während der Übergangsphase kein Risiko gibt:
wget -qO- 'https://get.bleemeo.com?accountId=...' | sudo bashErkennung verifizieren
Öffnen Sie das Bleemeo-Dashboard und überprüfen Sie, ob alle Ihre Server und Services automatisch erkannt wurden. Vergleichen Sie die erkannten Services mit Ihren Prometheus-Scrape-Targets, um die vollständige Abdeckung zu bestätigen. Glouton erkennt Datenbanken, Webserver, Message Broker und Anwendungs-Laufzeiten ohne Konfigurationsdateien.
Benutzerdefinierte Exporter konfigurieren (optional)
Wenn Sie benutzerdefinierte Prometheus-Exporter oder Anwendungs-Instrumentierung haben, konfigurieren Sie Glouton, deren Endpoints direkt zu scrapen. Dies gibt Ihnen eine vereinheitlichte Ansicht von Agent-erfassten und Exporter-gescrappten Metriken in einer einzigen Plattform, unter Beibehaltung Ihrer bestehenden Labels und Metrik-Namen.
Dashboards validieren
Überprüfen Sie die vorgefertigten Bleemeo-Dashboards und vergleichen Sie sie Seite an Seite mit Ihren bestehenden Grafana-Panels. Bestätigen Sie, dass Metriken, Zeitbereiche und Granularität Ihren betrieblichen Anforderungen entsprechen. Die meisten Teams stellen fest, dass Bleemeos automatische Dashboards ihre wichtigsten Anwendungsfälle ohne Anpassung abdecken.
Benachrichtigungen einrichten
Richten Sie Ihre bevorzugten Benachrichtigungskanäle ein — Slack, PagerDuty, E-Mail, Microsoft Teams oder benutzerdefinierte Webhooks — um Ihre Alertmanager-Routing-Konfiguration zu ersetzen. Bleemeos Alerting kommt mit sinnvollen Standard-Schwellenwerten, die bereits für jeden erkannten Service aktiv sind.
Prometheus-Stack außer Betrieb nehmen
Sobald Sie bestätigt haben, dass Bleemeo vollständige Abdeckung bietet und Ihr Team mit den neuen Dashboards und Alerting vertraut ist, nehmen Sie Ihre selbst gehosteten Prometheus-Server, Alertmanager-Cluster, Grafana-Instanzen und Thanos- oder Mimir-Storage-Backends außer Betrieb. Gewinnen Sie die Rechenressourcen zurück und befreien Sie Ihr Engineering-Team dauerhaft von der Monitoring-Stack-Wartung.
Was unsere Kunden sagen
Ingenieure und CTOs vertrauen auf Bleemeo für ihr Infrastruktur-Monitoring
Während einer kurzen Mittagspause haben wir Bleemeo installiert, eine benutzerdefinierte Metrik erstellt, Alerts getestet und waren produktionsbereit. Die Geschwindigkeit der Bereitstellung ist bemerkenswert.

Der Bleemeo-Support ist schlicht legendär — schnell, kompetent und immer da, wenn wir ihn brauchen.
Bleemeo war unglaublich schnell einzurichten. In etwa einer Stunde haben wir es auf über 100 Servern ausgerollt und sofort volle Sicht auf unsere Infrastruktur erhalten.

Wir haben das Monitoring für alle unsere Server in nur wenigen Stunden eingerichtet. Das Dashboard ist übersichtlich, leistungsstark und macht wirklich Freude in der Nutzung.

Wir haben Bleemeo in nur wenigen Stunden auf unserer gesamten Server-Infrastruktur ausgerollt. Das Uptime-Monitoring benachrichtigt uns jetzt sofort, wenn ein Dienst ein Problem hat.

Unser Prometheus + Grafana-Stack war zu einem Wartungsprojekt geworden. Mit Bleemeo haben wir den Agenten in Minuten ausgerollt und uns endlich auf die Nutzung des Monitorings statt auf dessen Wartung konzentriert.
Nach der Installation des Agenten hat Bleemeo automatisch unsere Datenbanken, Container und Services erkannt. Innerhalb einer Stunde hatten wir volle Infrastruktur-Sichtbarkeit — ohne Dashboards oder Exporter bauen zu müssen.
Bleemeo hat mehrere Monitoring-Tools durch eine einzige Plattform ersetzt. Metriken, Alerts und Logs sind jetzt an einem Ort, was unserem Team erheblich Zeit spart.
Bleemeo gab uns sofortigen Einblick in unsere Infrastruktur ohne die übliche Komplexität. Innerhalb weniger Stunden liefen Metriken, Alerts und Dashboards reibungslos.
Die Einrichtung von Bleemeo war erfrischend einfach. Das Agent-Deployment dauerte Minuten und die automatische Erkennung ersparte uns Tage an Konfiguration.
Dank Bleemeo erkennt unser Team Probleme jetzt, bevor unsere Nutzer sie bemerken. Die Alerting-Funktion ist zuverlässig und die Oberfläche macht die Fehlersuche deutlich schneller.
Der Wechsel zu Bleemeo hat unseren Monitoring-Stack dramatisch vereinfacht. Statt mehrere Tools zu verwalten, ist alles, was wir brauchen, auf einer einzigen Plattform verfügbar.
Die Zentralisierung unserer Logs in Bleemeo hat die Fehlersuche drastisch vereinfacht. Statt zwischen Tools zu wechseln, können wir jetzt Metriken und Logs sofort korrelieren, um zu verstehen, was passiert.
Bleemeo hat das Kubernetes-Monitoring überraschend einfach gemacht. Innerhalb von Minuten hatten wir Einblick in unsere Cluster, Pods und Workloads, ohne komplexe Dashboards selbst bauen zu müssen.
Bleemeo in Aktion sehen
Sehen Sie, wie Teams in unter 5 Minuten von der Installation zum vollständigen Monitoring gelangen
Häufig gestellte Fragen
Kann Bleemeo einen selbst gehosteten Prometheus-Stack ersetzen?
Ja. Bleemeo erfasst dieselben Infrastruktur-Metriken, scrapt nativ Prometheus-Exporter für benutzerdefinierte Metriken und beinhaltet Dashboards, Alerting und 13 Monate Speicherung — ohne eigene Server zu betreiben.
Unterstützt Bleemeo PromQL?
Glouton, der Bleemeo-Agent, scrapt Prometheus-Exporter nativ im Standard-Exposition-Format. Ihre bestehenden Exporter und Instrumentierung funktionieren sofort.
Was ist mit Langzeitspeicherung?
Bleemeo speichert Metriken in voller Auflösung für 13 Monate, im Basispreis enthalten. Kein Thanos, Cortex oder Mimir nötig.
Ist der Bleemeo-Agent Open Source?
Ja. Glouton ist Apache 2.0 lizenziert und unterstützt automatische Service-Erkennung für über 100 Services — keine Scrape-Konfigurationen nötig.
Unterstützt Bleemeo benutzerdefinierte Metriken von Prometheus-Exportern?
Ja. Glouton scrapt nativ jeden Prometheus-Exporter-Endpoint. Ihre bestehenden Exporter und benutzerdefinierte Instrumentierung funktionieren ohne Änderungen.
Was ist mit Alerting ohne Alertmanager?
Bleemeo enthält vorkonfigurierte Alert-Schwellenwerte für jeden erkannten Service, plus ML-basierte Anomalie-Erkennung. Benachrichtigungen per E-Mail, Slack, PagerDuty und Webhooks — kein Alertmanager zu konfigurieren.
Gibt es ein kostenloses Angebot?
Ja. Überwachen Sie bis zu 3 Server kostenlos ohne Zeitlimit. Alle Funktionen enthalten — Dashboards, Alerts, Service-Erkennung.
Kann ich einige Prometheus-Instanzen neben Bleemeo weiterlaufen lassen?
Ja. Viele Teams betreiben beide während der Migration. Glouton arbeitet unabhängig und stört das bestehende Prometheus-Scraping nicht.
Bereit, Ihren Monitoring-Stack nicht mehr zu warten?
Hören Sie auf, Ingenieurstunden für Prometheus-Upgrades, Thanos-Compaction-Probleme und Grafana-Dashboard-Wartung aufzuwenden. Erhalten Sie produktionsbereites Monitoring mit 13 Monaten Aufbewahrung, automatischer Service-Erkennung und intelligentem Alerting — alles ohne einen einzigen Server zu verwalten.
Keine Kreditkarte erforderlich · Kostenloses Angebot verfügbar · Jederzeit kündbar