Un'Alternativa Gestita a Prometheus Self-Hosted
Prometheus e lo standard per le metriche, ma eseguirlo in produzione significa gestire Alertmanager, Grafana, storage a lungo termine e pianificazione della capacita. Bleemeo ti offre la stessa visibilita con zero server da provisioning e zero pagine notturne sul tuo stack di monitoraggio.
15 giorni di prova gratuita • Nessuna carta di credito richiesta • Prezzi sempre prevedibili
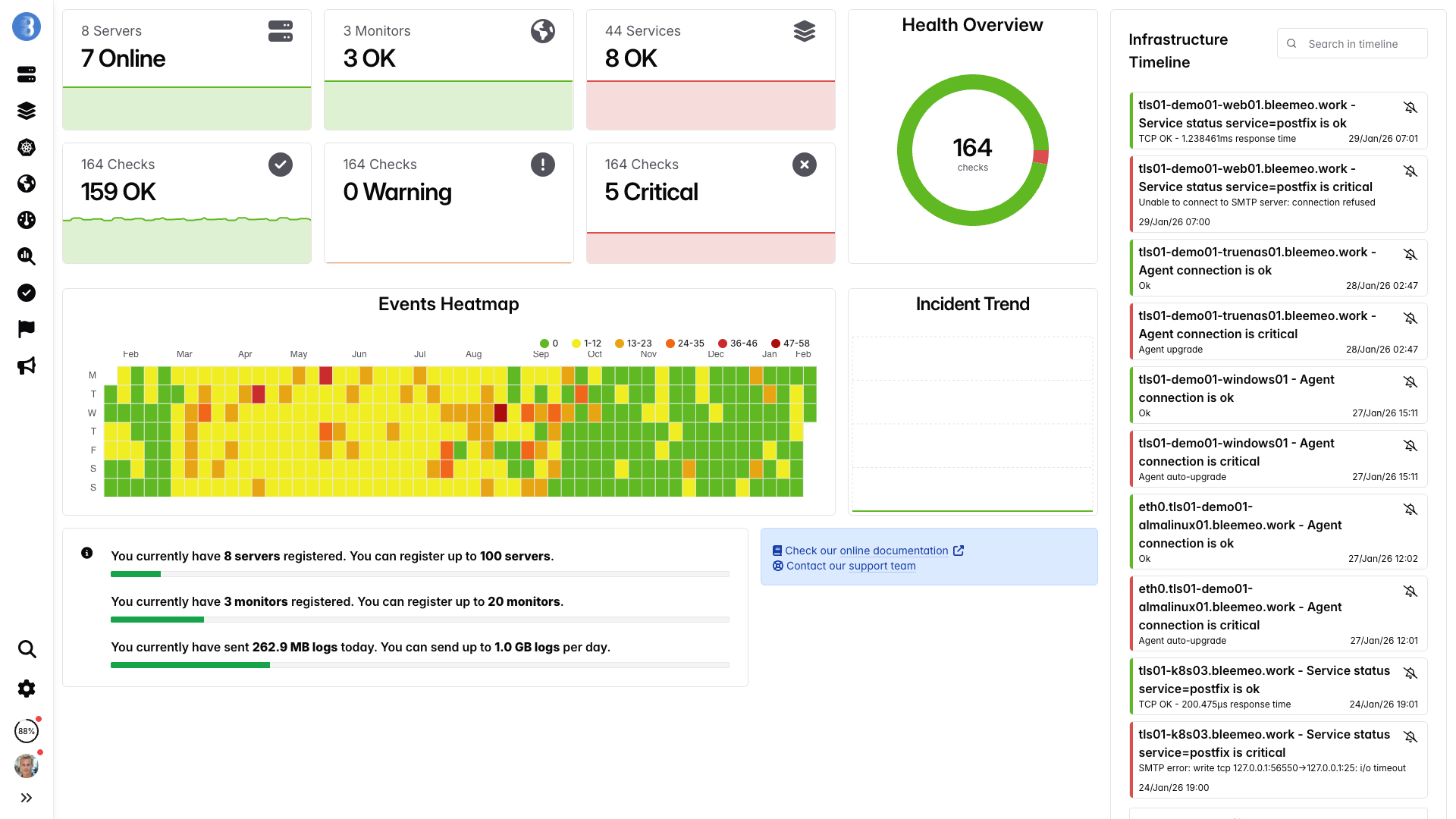
Dashboard in tempo reale, pronti in pochi minuti — nessuna configurazione necessaria
Sfide Comuni con Prometheus
Overhead Infrastrutturale
Eseguire Prometheus su larga scala significa mantenere piu istanze Prometheus, configurare federation o sharding, e costruire pipeline per spostare dati tra componenti. Ogni istanza aggiuntiva richiede la propria allocazione di risorse, configurazione di scraping e recording rules — creando un onere operativo che cresce linearmente con la tua infrastruttura.
Complessita dello Storage
Prometheus ha un default di soli 15 giorni di retention, il che significa che qualsiasi analisi storica o pianificazione della capacita richiede una soluzione di storage a lungo termine separata. Thanos, Cortex e Mimir risolvono ciascuno questo problema ma introducono la propria architettura, dipendenze di object storage e processi di compaction che richiedono tuning e monitoraggio attenti.
Setup di Dashboard e Alert
Prometheus include solo un browser di espressioni basilare — nessuna dashboard integrata o interfaccia curata. Servono Grafana per la visualizzazione e Alertmanager per le notifiche, entrambi richiedono setup manuale. Ogni pannello dashboard, ogni regola di alerting e ogni recording rule deve essere scritta a mano in PromQL e mantenuta nel version control man mano che la tua infrastruttura evolve.
Sfide di Scalabilita
Le metriche ad alta cardinalita da ambienti dinamici come Kubernetes possono causare picchi di memoria improvvisi e OOM kill che bloccano l'intero stack di monitoraggio. Scalare Prometheus richiede sharding su piu istanze o configurare gerarchie di federation, e le policy di retention devono essere bilanciate attentamente rispetto allo spazio disco disponibile. La pianificazione della capacita diventa un compito ricorrente che allontana gli ingegneri dal lavoro sul prodotto.
Prometheus vs Bleemeo
| Funzionalita | Prometheus (self-hosted) | Bleemeo |
|---|---|---|
| Tempo di Setup | Ore o giorni di configurazione | 5 minuti, un comando |
| Infrastruttura Necessaria | Prometheus + Alertmanager + Grafana + storage | Nessuna — SaaS completamente gestito |
| Storage a Lungo Termine | Thanos/Cortex/Mimir necessario | 13 mesi inclusi |
| Rilevamento Servizi | Configurazione scrape manuale per ogni target | Automatico, zero configurazione |
| Dashboard | Costruzione da zero in Grafana | Pre-costruite, auto-attivate |
| Regole di Alert | Scrivere e mantenere regole PromQL | Default intelligenti + rilevamento anomalie ML |
| Alta Disponibilita | Stack duplicati + federation | Ridondanza integrata |
| Manutenzione | Aggiornamenti, scaling, troubleshooting | Zero — gestiamo tutto noi |
| Modello di Rete | Pull-based: richiede accesso di rete a tutti i target | Push-based: gli agenti inviano dati in uscita, nessuna porta in ingresso necessaria |
| Gestione Cardinalita | L'alta cardinalita causa pressione sulla memoria e OOM kill | Gestita lato server con controlli automatici della cardinalita |
| Gestione Log | Non inclusa — richiede Loki o stack separato | Raccolta e ricerca log integrata insieme alle metriche |
| Compatibilita PromQL | Nativo | Metriche compatibili con Prometheus |
| Agente Open Source | Exporter Prometheus | Glouton (Apache 2.0) |
Confronto Reale dei Costi
Per un'infrastruttura tipica di 100 server con Prometheus self-hosted, il costo reale va ben oltre compute e storage — include le ore di ingegneria spese per mantenere, risolvere problemi e scalare il tuo stack di monitoraggio invece di sviluppare funzionalita del prodotto.
Prometheus (self-hosted)
*Piu costi nascosti: fatica da reperibilita, silos di conoscenza e costo-opportunita degli ingegneri che non lavorano sul prodotto
Bleemeo
*Con prenotazione 1 anno. Nessun costo infrastrutturale.
Perche i Team Scelgono Bleemeo
Zero Infrastruttura
Nessun server Prometheus da mantenere, nessun cluster Thanos da sorvegliare, nessuna istanza Grafana da aggiornare e nessun bucket di object storage da gestire. Bleemeo gestisce tutta l'infrastruttura cosi il tuo team puo concentrarsi sullo sviluppo delle funzionalita del prodotto invece di tenere in vita lo stack di monitoraggio. Non dovrai piu preoccuparti di spazio disco, pressione sulla memoria o OOM kill nel tuo layer di osservabilita.
Compatibile con Prometheus
Glouton esegue lo scraping degli exporter Prometheus direttamente e mantiene i tuoi exporter e il codice di strumentazione esistenti intatti. Bleemeo supporta gli stessi formati di metriche e label compatibili con Prometheus che gia utilizzi, rendendolo un sostituto diretto per il tuo backend Prometheus senza riscrivere una singola recording rule o configurazione di relabeling.
Rilevamento Automatico
A differenza di Prometheus, che richiede configurazione manuale dello scraping per ogni nuovo target, l'agente Glouton di Bleemeo rileva automaticamente i servizi in esecuzione — database, web server, message broker e altro — e inizia a raccogliere le metriche giuste immediatamente. Nessuna modifica YAML, nessun plugin di service discovery, nessuna regola di relabeling da mantenere.
Tutto Pre-costruito
Mentre Prometheus ti offre un browser di espressioni vuoto, Bleemeo fornisce dashboard pre-costruite ricche, soglie di alerting intelligenti e rilevamento anomalie basato su ML che si attivano automaticamente nel momento in cui un servizio viene scoperto. Non dovrai piu passare giorni a creare pannelli Grafana o scrivere regole di alerting PromQL da zero per ogni nuova applicazione che distribuisci.
Agente Open Source
Glouton, il nostro agente di monitoraggio, e completamente open source con licenza Apache 2.0. Puoi verificare ogni riga di codice in esecuzione sui tuoi server, contribuire con miglioramenti e stare tranquillo che non c'e vendor lock-in. I tuoi dati di metriche restano tuoi e puoi esportarli in qualsiasi momento utilizzando formati Prometheus standard.
Residenza Dati in Europa
Tutti i tuoi dati di monitoraggio sono archiviati in data center europei con piena conformita GDPR integrata fin dal primo giorno. A differenza delle alternative SaaS basate negli USA, Bleemeo e un'azienda europea che mantiene la telemetria della tua infrastruttura sotto la giurisdizione UE, offrendoti una conformita semplice per i requisiti di residenza dei dati.
Parita di Funzionalita Dove Conta
Monitoraggio Infrastruttura
Monitoraggio completo di CPU, memoria, disco, rete e processi con rilevamento automatico dei servizi che individua database, web server e runtime applicativi senza alcuna configurazione. Ottieni una visibilita piu approfondita rispetto alle metriche standard di node_exporter di Prometheus immediatamente.
Container e Kubernetes
Supporto nativo per Docker e Kubernetes con metriche a livello di pod, monitoraggio della salute dei nodi e panoramiche dell'intero cluster. A differenza di Prometheus, che richiede kube-state-metrics, cAdvisor e regole di relabeling complesse, Bleemeo offre monitoraggio dei container che funziona immediatamente dopo l'installazione dell'agente.
Gestione Log
Raccogli, indicizza e cerca i log insieme alle tue metriche in un'unica piattaforma unificata. Prometheus non ha alcuna gestione log — i team tipicamente aggiungono Loki, Elasticsearch o Splunk come ennesimo sistema da gestire. Con Bleemeo, log e metriche vivono insieme, rendendo l'analisi delle cause piu rapida e semplice.
Alerting Intelligente
Il rilevamento anomalie basato su machine learning identifica pattern insoliti prima che diventino interruzioni, completando le soglie di alert preconfigurate per ogni servizio scoperto. Niente piu scrittura e tuning manuale di regole di alerting PromQL o manutenzione degli alberi di routing di Alertmanager — i default intelligenti coprono i casi comuni mentre tu personalizzi cio che conta di piu.
Dashboard Personalizzate
Costruisci le viste esatte di cui il tuo team ha bisogno con widget drag-and-drop intuitivi, o parti dalla ricca libreria di dashboard pre-costruite che si attivano automaticamente. A differenza di Grafana, dove ogni pannello richiede query PromQL manuali e configurazione JSON, le dashboard Bleemeo sono pronte all'uso nel momento in cui i tuoi agenti si connettono.
Monitoraggio Uptime
Controlli di uptime HTTP, TCP e ICMP da piu localita globali, con monitoraggio della scadenza dei certificati SSL e tracciamento dei tempi di risposta. Il blackbox_exporter di Prometheus fornisce probing di base, ma Bleemeo offre un approccio completamente gestito e multi-localita con alerting integrato e status page che non richiedono infrastruttura da parte tua.
Migrazione da Prometheus
La maggior parte dei team utilizza entrambi i sistemi in parallelo per alcune settimane prima di passare completamente. La migrazione e semplice e non invasiva — gli agenti Bleemeo funzionano insieme al tuo setup Prometheus esistente senza conflitti. Il nostro team e disponibile per aiutare con la pianificazione e la validazione della migrazione a ogni passo.
Distribuisci gli Agenti Bleemeo
Installa l'agente Bleemeo insieme ai tuoi exporter Prometheus esistenti con un singolo comando. L'agente funziona in modo indipendente e non interferisce con il tuo stack di monitoraggio attuale, quindi c'e zero rischio durante il periodo di transizione:
wget -qO- 'https://get.bleemeo.com?accountId=...' | sudo bashVerifica il Rilevamento
Apri la dashboard Bleemeo e verifica che tutti i tuoi server e servizi siano stati rilevati automaticamente. Confronta la lista dei servizi scoperti con i tuoi target di scraping Prometheus per confermare la copertura completa. Glouton identifica database, web server, message broker e runtime applicativi senza alcun file di configurazione.
Configura Exporter Personalizzati (opzionale)
Se hai exporter Prometheus personalizzati o strumentazione a livello applicativo, configura Glouton per eseguire lo scraping dei loro endpoint direttamente. Questo ti offre una vista unificata sia delle metriche raccolte dall'agente che di quelle da scraping in un'unica piattaforma, preservando le tue label e nomi delle metriche esistenti.
Valida le Dashboard
Rivedi le dashboard pre-costruite di Bleemeo e confrontale fianco a fianco con i tuoi pannelli Grafana esistenti. Conferma che le metriche, gli intervalli temporali e la granularita corrispondano alle tue esigenze operative. La maggior parte dei team trova che le dashboard automatiche di Bleemeo coprono i loro casi d'uso principali senza alcuna personalizzazione necessaria.
Configura le Notifiche
Configura i tuoi canali di notifica preferiti — Slack, PagerDuty, email, Microsoft Teams o webhook personalizzati — per sostituire la tua configurazione di routing di Alertmanager. L'alerting di Bleemeo include soglie di default sensate gia attive per ogni servizio scoperto, cosi sei coperto fin dall'inizio mentre regoli le preferenze di notifica.
Disattiva lo Stack Prometheus
Una volta validato che Bleemeo fornisce copertura completa e il tuo team e a suo agio con le nuove dashboard e l'alerting, disattiva i tuoi server Prometheus self-hosted, i cluster Alertmanager, le istanze Grafana e i backend di storage Thanos o Mimir. Recupera le risorse di calcolo e libera il tuo team di ingegneria dalla manutenzione dello stack di monitoraggio permanentemente.
Cosa dicono i nostri clienti
Ingegneri e CTO si affidano a Bleemeo per monitorare la loro infrastruttura
Durante una breve pausa pranzo abbiamo installato Bleemeo, creato una metrica personalizzata, testato gli alert ed eravamo pronti per la produzione. La velocità di deployment è notevole.

Il supporto di Bleemeo è semplicemente leggendario: rapido, competente e sempre presente quando ne abbiamo bisogno.
Il deployment di Bleemeo è stato incredibilmente veloce. In circa un'ora lo abbiamo distribuito su più di 100 server e abbiamo immediatamente ottenuto piena visibilità sulla nostra infrastruttura.

Abbiamo configurato il monitoraggio di tutti i nostri server in poche ore. La dashboard è chiara, potente e davvero piacevole da usare.

Abbiamo distribuito Bleemeo su tutta la nostra infrastruttura server in poche ore. Il monitoraggio dell'uptime ci avvisa istantaneamente ogni volta che un servizio riscontra un problema.

Il nostro stack Prometheus + Grafana era diventato un progetto di manutenzione. Con Bleemeo abbiamo distribuito l'agente in pochi minuti e finalmente ci siamo concentrati sull'uso del monitoraggio anziché sulla sua manutenzione.
Dopo aver installato l'agente, Bleemeo ha scoperto automaticamente i nostri database, container e servizi. In un'ora avevamo piena visibilità sull'infrastruttura — senza dashboard o exporter da costruire.
Bleemeo ha sostituito diversi strumenti di monitoraggio con un'unica piattaforma. Metriche, alert e log sono ora in un unico posto, facendo risparmiare al nostro team un tempo significativo.
Bleemeo ci ha dato una visibilità immediata sulla nostra infrastruttura senza la complessità abituale. In un paio d'ore avevamo metriche, alert e dashboard perfettamente funzionanti.
Configurare Bleemeo è stato sorprendentemente semplice. Il deployment dell'agente ha richiesto pochi minuti e la scoperta automatica ci ha fatto risparmiare giorni di configurazione.
Grazie a Bleemeo, il nostro team ora rileva i problemi prima che gli utenti li notino. Gli alert sono affidabili e l'interfaccia rende la risoluzione dei problemi molto più rapida.
Il passaggio a Bleemeo ha semplificato drasticamente il nostro stack di monitoraggio. Invece di gestire più strumenti, tutto ciò di cui abbiamo bisogno è disponibile in un'unica piattaforma.
Centralizzare i nostri log in Bleemeo ha semplificato drasticamente la risoluzione dei problemi. Invece di saltare tra gli strumenti, ora possiamo correlare metriche e log istantaneamente per capire cosa sta succedendo.
Bleemeo ha reso il monitoraggio di Kubernetes sorprendentemente facile. In pochi minuti avevamo visibilità sui nostri cluster, pod e workload senza dover costruire dashboard complessi da soli.
Vedi Bleemeo in azione
Guarda come i team passano dall'installazione al monitoraggio completo in meno di 5 minuti
Domande frequenti
Bleemeo puo sostituire uno stack Prometheus self-hosted?
Si. Bleemeo raccoglie le stesse metriche infrastrutturali, esegue nativamente lo scraping degli exporter Prometheus per le metriche personalizzate e include dashboard, alerting e 13 mesi di archiviazione — senza gestire alcun server.
Bleemeo supporta PromQL?
Glouton, l'agente Bleemeo, esegue lo scraping degli exporter Prometheus nativamente utilizzando il formato di esposizione standard. I tuoi exporter e la tua strumentazione esistenti funzionano immediatamente.
E per l'archiviazione a lungo termine?
Bleemeo archivia le metriche a piena risoluzione per 13 mesi, inclusi nel prezzo base. Non servono Thanos, Cortex o Mimir.
L'agente Bleemeo e open source?
Si. Glouton e rilasciato con licenza Apache 2.0 e supporta il rilevamento automatico dei servizi per oltre 100 servizi — nessuna configurazione di scraping necessaria.
Bleemeo supporta metriche personalizzate da exporter Prometheus?
Si. Glouton esegue nativamente lo scraping di qualsiasi endpoint exporter Prometheus. I tuoi exporter e la strumentazione personalizzata esistenti funzionano senza modifiche.
E per l'alerting senza Alertmanager?
Bleemeo include soglie di alert preconfigurate per ogni servizio scoperto, piu rilevamento anomalie basato su ML. Notifiche via email, Slack, PagerDuty e webhook — nessun Alertmanager da configurare.
Esiste un piano gratuito?
Si. Monitora fino a 3 server gratuitamente senza limiti di tempo. Tutte le funzionalita incluse — dashboard, alert, rilevamento servizi.
Posso mantenere alcune istanze Prometheus in funzione insieme a Bleemeo?
Si. Molti team utilizzano entrambi durante la migrazione. Glouton funziona in modo indipendente e non interferisce con lo scraping Prometheus esistente.
Pronto a Smettere di Mantenere il Tuo Stack di Monitoraggio?
Smetti di spendere ore di ingegneria per aggiornamenti di Prometheus, problemi di compaction di Thanos e manutenzione delle dashboard Grafana. Ottieni monitoraggio pronto per la produzione con 13 mesi di retention, rilevamento automatico dei servizi e alerting intelligente — tutto senza un singolo server da gestire.
Nessuna carta di credito richiesta • Piano gratuito disponibile • Cancella quando vuoi