Un'Alternativa Completa a Grafana
Grafana eccelle nella visualizzazione, ma non è una soluzione di monitoraggio completa. Hai ancora bisogno di Prometheus, Loki, Alertmanager e Mimir — ognuno con il proprio carico operativo. Bleemeo sostituisce l'intero stack LGTM con un'unica piattaforma gestita.
15 giorni gratis • Nessuna carta di credito • Nessuna infrastruttura da gestire
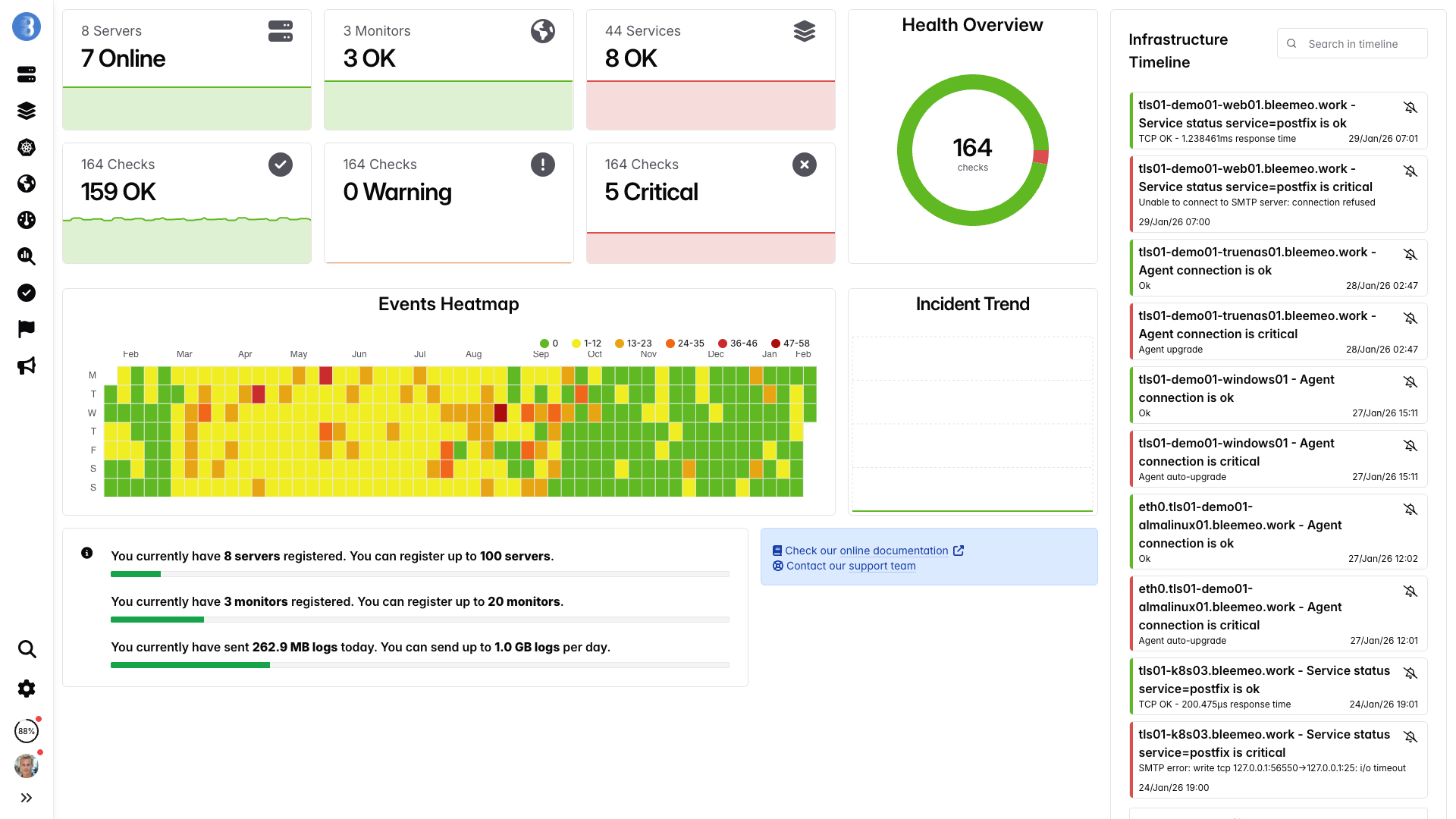
Dashboard in tempo reale, pronte in pochi minuti — nessuna configurazione necessaria
Le Sfide con lo Stack Grafana
Più Strumenti da Gestire
Grafana è puramente un layer di visualizzazione e non può raccogliere una singola metrica da solo. Per costruire uno stack di monitoraggio funzionante, devi distribuire Prometheus per lo scraping delle metriche, Loki e Promtail per l'ingestione dei log, Alertmanager per il routing delle notifiche, e potenzialmente Mimir o Thanos per lo storage a lungo termine. Ognuno di questi componenti ha la propria sintassi di configurazione, ciclo di aggiornamento e modalità di errore, il che significa che il tuo team passa più tempo a mantenere la piattaforma di monitoraggio che ad usarla per migliorare l'affidabilità.
Overhead dell'Infrastruttura
Eseguire lo stack LGTM su larga scala è un lavoro a tempo pieno. I server Prometheus richiedono un'attenta pianificazione della capacità per memoria e disco, e le metriche ad alta cardinalità possono causare crash out-of-memory che disattivano l'intero sistema di monitoraggio nel momento peggiore possibile. Aggiungere lo storage a lungo termine con Thanos o Cortex introduce job di compattazione, gestione object storage e complessità di query federation che cresce con ogni nuovo cluster che integri.
Configurazione Complessa
Configurare il service discovery di Prometheus, gli intervalli di scrape, le regole di relabeling, le recording rules e le alerting rules richiede competenze approfondite in PromQL e configurazione YAML. La gestione degli alert è divisa tra le regole di alerting di Prometheus e gli alberi di routing di Alertmanager, rendendo difficile capire chi viene notificato, quando e perché. Una singola regola di relabel o silence mal configurata può causare la perdita silenziosa di alert critici, lasciando il tuo team cieco durante un incidente.
Nessun Agent Integrato
Grafana dipende interamente da collector di terze parti per l'ingestione dei dati. Devi distribuire node_exporter su ogni server Linux, windows_exporter su macchine Windows, blackbox_exporter per i check degli endpoint, e decine di exporter specifici per applicazioni come database, code messaggi e server web. Ogni exporter deve essere installato, configurato con i flag corretti, registrato come servizio systemd e aggiunto ai target di scrape di Prometheus. Gestire questa flotta di exporter su centinaia di server diventa un significativo onere operativo che scala male.
Stack Grafana vs Bleemeo
| Funzionalità | Stack Grafana | Bleemeo |
|---|---|---|
| Raccolta Metriche | Richiede il deployment del server Prometheus più node_exporter su ogni host | Agent leggero integrato con rilevamento automatico dei servizi e zero configurazione |
| Gestione Log | Richiede il deployment di Loki per lo storage più agent Promtail su ogni server per la spedizione dei log | Aggregazione e ricerca log integrata, raccolta dallo stesso agent che raccoglie le metriche |
| Alerting | Richiede Alertmanager separato con alberi di routing e regole di inibizione complessi | Alerting integrato con routing intelligente, rilevamento anomalie e politiche di escalation |
| Infrastruttura | Componenti self-hosted che richiedono server dedicati, storage e manutenzione continua | Piattaforma SaaS completamente gestita senza server da provisioning o mantenere |
| Service Discovery | Configurazione manuale del service discovery basata su YAML per ogni tipo di target | Rilevamento automatico di servizi in esecuzione, container e processi senza configurazione |
| App Mobile | Solo interfaccia web, nessuna esperienza mobile nativa per il monitoraggio in mobilità | App native iOS e Android con notifiche push per alerting in tempo reale su mobile |
| Monitoraggio Uptime | Richiede il deployment e la configurazione di blackbox_exporter con moduli probe | Monitoraggio HTTP, TCP e ICMP integrato da 7 location globali con tracciamento latenza |
| Scalabilità | Federation complessa o deployment Thanos/Cortex necessario per scaling multi-cluster | Scaling orizzontale automatico, basta aggiungere agent e la piattaforma gestisce il resto |
| Manutenzione | Aggiornamenti manuali, strategie di backup, politiche di retention e patch di sicurezza per ogni componente | Zero manutenzione richiesta, aggiornamenti automatici e backup gestiti con uptime garantito |
| Creazione Dashboard | Query PromQL manuali, ore di configurazione pannelli e variabili per ogni dashboard | Dashboard predefinite per tutti i servizi rilevati, pronte in secondi senza scrivere query |
| Compatibilità Prometheus | Prometheus nativo, ma richiede un deployment Prometheus self-managed completo | Fa lo scrape degli exporter Prometheus nativamente, nessun server Prometheus separato necessario |
| Retention Dati | Default 15 giorni, long-term richiede Thanos o Mimir con object storage | Un anno di retention incluso, nessuna infrastruttura o configurazione storage aggiuntiva |
| Curva di Apprendimento | Ripida: PromQL, LogQL, routing Alertmanager, regole di relabeling e configurazione YAML | Interfaccia web intuitiva, produttivo in ore senza necessità di linguaggio di query |
Costo Totale di Proprietà
Stack Grafana
Bleemeo
*Con prenotazione 1 anno. Log fatturati separatamente a 0,50€/GiB.
Perché Scegliere Bleemeo
Piattaforma All-in-One
Smetti di destreggiarti tra Prometheus, Loki, Alertmanager, Thanos e Grafana come componenti separati. Bleemeo offre raccolta metriche, aggregazione log, monitoraggio uptime, alerting intelligente e dashboard in tempo reale in un'unica piattaforma integrata. Tutto funziona insieme immediatamente, eliminando derive di configurazione e incompatibilità di versione tra componenti.
Agent Intelligente
L'agent Bleemeo rileva automaticamente servizi in esecuzione, container, database e server web su ogni host. Raccoglie metriche di sistema, metriche specifiche delle applicazioni e log senza richiedere l'installazione o la configurazione di exporter separati. Un agent sostituisce node_exporter, process-exporter e decine di exporter specifici, riducendo drasticamente la superficie di deployment.
Zero Infrastruttura
Nessun server Prometheus da scalare, nessun cluster Loki da gestire, nessun compattatore Thanos da regolare e nessun componente da patchare o aggiornare. Bleemeo gestisce tutta l'infrastruttura backend, inclusa alta disponibilità, replica dei dati e storage a lungo termine. Il tuo team recupera le ore di engineering precedentemente dedicate a mantenere in funzione lo stack di monitoraggio stesso.
Compatibile con Prometheus
Hai già investito in exporter Prometheus e metriche personalizzate? Glouton, l'agent Bleemeo, supporta nativamente il formato di esposizione Prometheus e può fare lo scrape degli endpoint dei tuoi exporter esistenti direttamente. Nessun server Prometheus separato necessario, rendendo la migrazione graduale e senza rischi. Le tue conoscenze PromQL e metriche personalizzate sono completamente preservate.
Alert Intelligenti
Bleemeo include il rilevamento anomalie integrato che apprende i pattern di comportamento normali della tua infrastruttura e ti avvisa quando qualcosa devia. Il routing intelligente degli alert invia notifiche tramite email, Slack, PagerDuty o notifiche push mobile senza richiedere alberi di routing Alertmanager complessi. Gli alert basati su soglie sono preconfigurati per i servizi comuni, così ricevi alert significativi dal primo giorno.
Dashboard Bellissime
Bleemeo fornisce dashboard moderne e responsive generate automaticamente per ogni servizio rilevato. A differenza di Grafana dove passi ore a creare query PromQL e configurare pannelli, le dashboard Bleemeo sono pronte immediatamente con impostazioni predefinite sensate. Puoi comunque creare viste personalizzate e approfondire metriche specifiche, ma l'esperienza out-of-the-box copre la maggior parte delle esigenze di monitoraggio senza alcuna configurazione manuale.
Transizione Facile dallo Stack Grafana
La migrazione dallo stack Grafana non deve essere un taglio netto. Puoi eseguire Bleemeo insieme alla tua configurazione Prometheus e Grafana esistente, validare la copertura e disattivare gradualmente i componenti che non ti servono più. L'intero processo richiede tipicamente meno di una settimana per la maggior parte dei team.
Distribuisci gli Agent Bleemeo
Installa l'agent Bleemeo su ogni server con un singolo comando. L'agent funziona insieme ai tuoi exporter Prometheus esistenti senza conflitti e inizia immediatamente a raccogliere metriche di sistema, rilevare servizi e inviare dati alla piattaforma Bleemeo:
wget -qO- 'https://get.bleemeo.com?accountId=...' | sudo bashVerifica la Copertura
Accedi alla console Bleemeo e verifica che tutti i tuoi server, container e servizi appaiano automaticamente. L'agent rileva database come MySQL e PostgreSQL, server web come Nginx e Apache, code messaggi come RabbitMQ e Kafka, e molti altri servizi senza alcuna configurazione manuale. Confronta i servizi rilevati con i tuoi target di scrape Prometheus esistenti per assicurare la copertura completa.
Connetti Exporter Esistenti
Se hai exporter Prometheus personalizzati o metriche strumentate dalle applicazioni, configura Glouton per fare lo scrape dei loro endpoint direttamente. Glouton supporta nativamente il formato standard di esposizione Prometheus, quindi le tue metriche personalizzate esistenti vengono preservate senza modifiche.
Configura gli Alert
Configura i canali di notifica come email, Slack, PagerDuty o integrazioni webhook. Bleemeo viene fornito con soglie di alert predefinite sensate per CPU, memoria, disco e disponibilità dei servizi. Rivedi queste impostazioni predefinite, regola le soglie in base ai tuoi SLO e aggiungi regole di alert personalizzate per metriche specifiche delle applicazioni. Molti team scoprono che il rilevamento anomalie integrato di Bleemeo cattura problemi che le loro regole Alertmanager create a mano non rilevavano.
Valida in Parallelo
Esegui Bleemeo insieme al tuo stack Grafana esistente per un periodo di validazione. Confronta alert, dashboard e copertura delle metriche tra i due sistemi. Questa operazione in parallelo assicura piena fiducia in Bleemeo prima di apportare modifiche alla configurazione esistente. La maggior parte dei team esegue entrambi i sistemi per una o due settimane.
Disattiva e Semplifica
Una volta validato, disattiva gradualmente i componenti dello stack Grafana che non ti servono più. Rimuovi server Prometheus, cluster Loki, istanze Alertmanager e la flotta di exporter dalla tua infrastruttura. Questo libera risorse di calcolo, riduce la superficie di attacco ed elimina il carico di reperibilità per la manutenzione della piattaforma di monitoraggio stessa. Il tuo team può ora concentrarsi interamente sulla costruzione e gestione del prodotto reale.
Cosa dicono i nostri clienti
Ingegneri e CTO si affidano a Bleemeo per monitorare la loro infrastruttura
Durante una breve pausa pranzo abbiamo installato Bleemeo, creato una metrica personalizzata, testato gli alert ed eravamo pronti per la produzione. La velocità di deployment è notevole.

Il supporto di Bleemeo è semplicemente leggendario: rapido, competente e sempre presente quando ne abbiamo bisogno.
Il deployment di Bleemeo è stato incredibilmente veloce. In circa un'ora lo abbiamo distribuito su più di 100 server e abbiamo immediatamente ottenuto piena visibilità sulla nostra infrastruttura.

Abbiamo configurato il monitoraggio di tutti i nostri server in poche ore. La dashboard è chiara, potente e davvero piacevole da usare.

Abbiamo distribuito Bleemeo su tutta la nostra infrastruttura server in poche ore. Il monitoraggio dell'uptime ci avvisa istantaneamente ogni volta che un servizio riscontra un problema.

Il nostro stack Prometheus + Grafana era diventato un progetto di manutenzione. Con Bleemeo abbiamo distribuito l'agente in pochi minuti e finalmente ci siamo concentrati sull'uso del monitoraggio anziché sulla sua manutenzione.
Dopo aver installato l'agente, Bleemeo ha scoperto automaticamente i nostri database, container e servizi. In un'ora avevamo piena visibilità sull'infrastruttura — senza dashboard o exporter da costruire.
Bleemeo ha sostituito diversi strumenti di monitoraggio con un'unica piattaforma. Metriche, alert e log sono ora in un unico posto, facendo risparmiare al nostro team un tempo significativo.
Bleemeo ci ha dato una visibilità immediata sulla nostra infrastruttura senza la complessità abituale. In un paio d'ore avevamo metriche, alert e dashboard perfettamente funzionanti.
Configurare Bleemeo è stato sorprendentemente semplice. Il deployment dell'agente ha richiesto pochi minuti e la scoperta automatica ci ha fatto risparmiare giorni di configurazione.
Grazie a Bleemeo, il nostro team ora rileva i problemi prima che gli utenti li notino. Gli alert sono affidabili e l'interfaccia rende la risoluzione dei problemi molto più rapida.
Il passaggio a Bleemeo ha semplificato drasticamente il nostro stack di monitoraggio. Invece di gestire più strumenti, tutto ciò di cui abbiamo bisogno è disponibile in un'unica piattaforma.
Centralizzare i nostri log in Bleemeo ha semplificato drasticamente la risoluzione dei problemi. Invece di saltare tra gli strumenti, ora possiamo correlare metriche e log istantaneamente per capire cosa sta succedendo.
Bleemeo ha reso il monitoraggio di Kubernetes sorprendentemente facile. In pochi minuti avevamo visibilità sui nostri cluster, pod e workload senza dover costruire dashboard complessi da soli.
Vedi Bleemeo in azione
Scopri come i team passano dall'installazione al monitoraggio completo in meno di 5 minuti
Domande frequenti
Bleemeo può sostituire l'intero stack Grafana?
Sì. Bleemeo sostituisce Grafana, Prometheus, Loki, Alertmanager e Mimir con un'unica piattaforma gestita. Metriche, log, dashboard e alerting sono tutti inclusi.
Devo creare le dashboard da zero?
No. Bleemeo crea automaticamente dashboard per ogni servizio rilevato. Dashboard personalizzate sono disponibili anche se hai bisogno di viste specifiche.
Bleemeo supporta le metriche Prometheus?
Sì. Glouton, l'agent di Bleemeo, fa lo scrape degli exporter Prometheus nativamente, quindi gli exporter esistenti e la strumentazione personalizzata funzionano immediatamente.
E Grafana Cloud?
I prezzi di Grafana Cloud scalano con l'utilizzo (metriche, log, trace). Il prezzo per agent di Bleemeo è prevedibile indipendentemente dal volume di dati — nessun costo per serie o per GB.
Posso usare Bleemeo insieme alla mia configurazione Grafana esistente?
Sì. Puoi eseguire gli agent Bleemeo insieme al tuo stack Grafana attuale durante la migrazione. Glouton opera in modo indipendente e non interferisce con Prometheus o altri collector.
Bleemeo supporta dashboard personalizzate?
Sì. Mentre Bleemeo crea automaticamente dashboard per ogni servizio rilevato, puoi anche creare dashboard personalizzate con widget drag-and-drop per le viste specifiche di cui il tuo team ha bisogno.
Esiste un piano gratuito?
Sì. Monitora fino a 3 server gratis senza limiti di tempo. Tutte le funzionalità incluse — dashboard, alert, log, rilevamento servizi.
Come si confronta la gestione log con Loki?
Bleemeo include raccolta e ricerca centralizzata dei log a 0,50€/GiB ingeriti. Nessun deployment Loki separato, nessun agent Promtail, nessun backend di storage da gestire.
Pronto a Lasciarti alle Spalle la Complessità dello Stack LGTM?
Unisciti a centinaia di team di engineering che sono passati dalla gestione separata di Prometheus, Loki, Alertmanager e Grafana a un'unica piattaforma che funziona e basta. Inizia la prova gratuita oggi e sperimenta il monitoraggio completo dell'infrastruttura senza overhead operativo. Distribuisci il tuo primo agent in meno di cinque minuti e vedi le metriche fluire immediatamente.
Nessuna carta di credito • 15 giorni di prova gratuita • Funziona insieme allo stack Grafana esistente • Accesso completo alle funzionalità