Une Alternative Complète à Grafana
Grafana excelle dans la visualisation, mais ce n'est pas une solution de monitoring complète. Vous avez toujours besoin de Prometheus, Loki, Alertmanager et Mimir — chacun avec sa propre charge opérationnelle. Bleemeo remplace l'ensemble de la stack LGTM par une seule plateforme managée.
Essai gratuit 15 jours • Sans carte bancaire • Aucune infrastructure à gérer
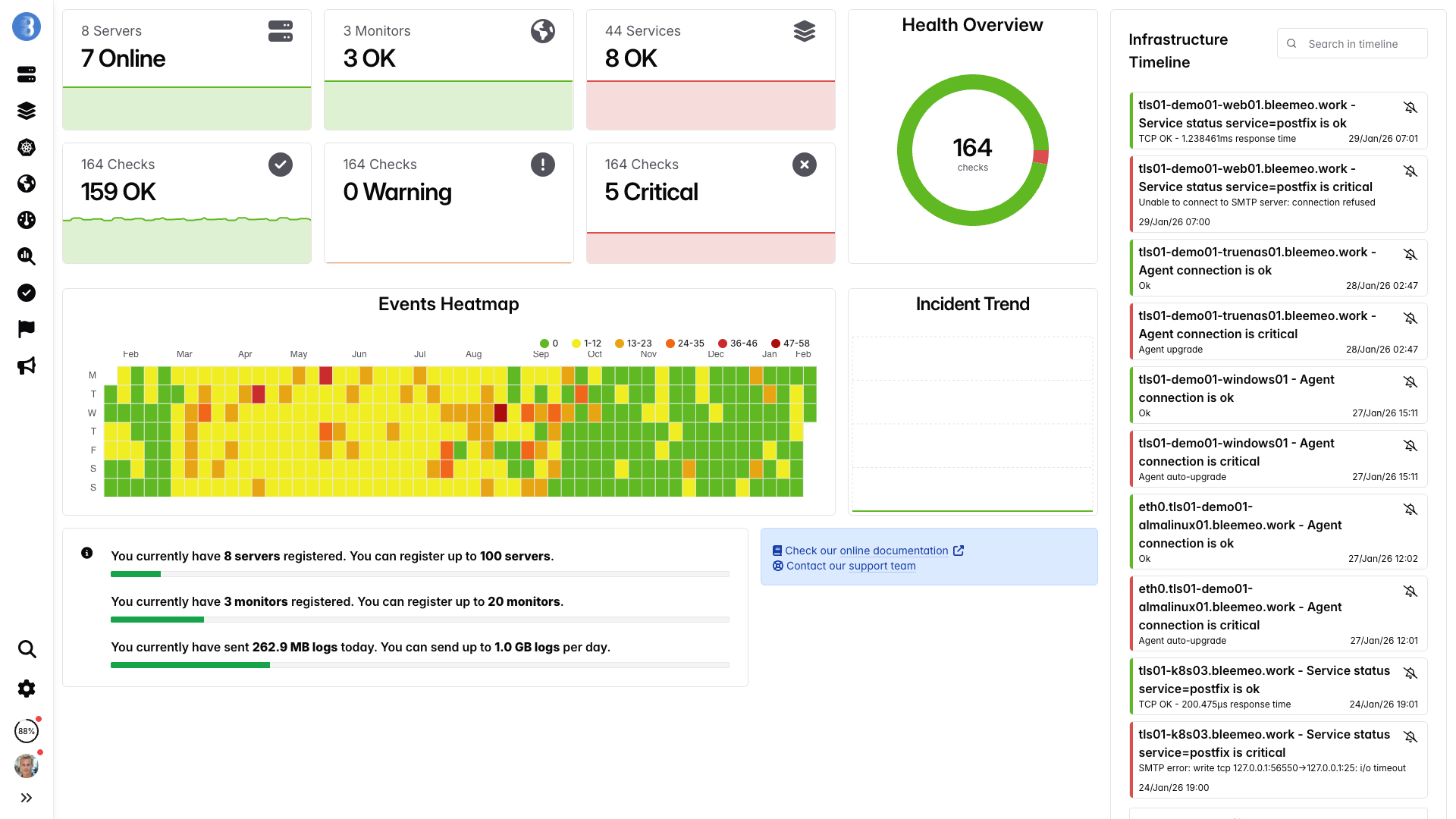
Tableaux de bord en temps réel, prêts en minutes — aucune configuration nécessaire
Les Défis avec la Stack Grafana
Plusieurs Outils à Gérer
Grafana n'est qu'une couche de visualisation et ne peut collecter aucune métrique par elle-même. Pour construire une stack de monitoring fonctionnelle, vous devez déployer Prometheus pour le scraping de métriques, Loki et Promtail pour l'ingestion de logs, Alertmanager pour le routage des notifications, et potentiellement Mimir ou Thanos pour le stockage long terme. Chacun de ces composants a sa propre syntaxe de configuration, son cycle de mise à jour et ses modes de défaillance, ce qui signifie que votre équipe passe plus de temps à maintenir la plateforme de monitoring qu'à l'utiliser réellement pour améliorer la fiabilité.
Charge d'Infrastructure
Faire tourner la stack LGTM à l'échelle est un travail à plein temps. Les serveurs Prometheus nécessitent une planification de capacité soigneuse pour la mémoire et le disque, et les métriques à haute cardinalité peuvent provoquer des crashs par manque de mémoire qui mettent à terre tout votre système de monitoring au pire moment. L'ajout de stockage long terme avec Thanos ou Cortex introduit des jobs de compaction, la gestion du stockage objet et une complexité de fédération de requêtes qui croît avec chaque nouveau cluster intégré.
Configuration Complexe
Configurer la découverte de services Prometheus, les intervalles de scrape, les règles de relabeling, les recording rules et les alerting rules nécessite une expertise approfondie en PromQL et configuration YAML. La gestion des alertes est partagée entre les règles d'alerte Prometheus et les arbres de routage Alertmanager, rendant difficile de comprendre qui est notifié, quand et pourquoi. Une seule règle de relabeling mal configurée ou un silence incorrect peut entraîner la suppression silencieuse d'alertes critiques, laissant votre équipe aveugle pendant un incident.
Pas d'Agent Intégré
Grafana repose entièrement sur des collecteurs tiers pour l'ingestion de données. Vous devez déployer node_exporter sur chaque serveur Linux, windows_exporter sur les machines Windows, blackbox_exporter pour les checks d'endpoints, et des dizaines d'exporters spécifiques aux applications pour les bases de données, files de messages et serveurs web. Chaque exporter doit être installé, configuré avec les bons flags, enregistré comme service systemd et ajouté aux targets de scrape Prometheus. Gérer cette flotte d'exporters sur des centaines de serveurs devient une charge opérationnelle significative qui ne passe pas à l'échelle.
Stack Grafana vs Bleemeo
| Fonctionnalité | Stack Grafana | Bleemeo |
|---|---|---|
| Collecte de Métriques | Nécessite le déploiement d'un serveur Prometheus plus node_exporter sur chaque host | Agent léger intégré avec découverte automatique des services et zéro configuration |
| Gestion des Logs | Nécessite le déploiement de Loki pour le stockage plus des agents Promtail sur chaque serveur pour l'envoi des logs | Agrégation et recherche de logs intégrées, collectées par le même agent qui récupère les métriques |
| Alertes | Nécessite un Alertmanager séparé avec des arbres de routage complexes et des règles d'inhibition | Alertes intégrées avec routage intelligent, détection d'anomalies et politiques d'escalade |
| Infrastructure | Composants auto-hébergés nécessitant des serveurs dédiés, du stockage et une maintenance continue | Plateforme SaaS entièrement managée sans serveurs à provisionner ni maintenir |
| Découverte de Services | Configuration manuelle de découverte de services en YAML pour chaque type de cible | Détection automatique des services en cours, conteneurs et processus sans configuration |
| Applications Mobiles | Interface web uniquement, pas d'expérience mobile native pour le monitoring en déplacement | Apps natives iOS et Android avec notifications push pour les alertes en temps réel sur mobile |
| Monitoring de Disponibilité | Nécessite le déploiement et la configuration de blackbox_exporter avec des modules de probe | Monitoring HTTP, TCP et ICMP intégré depuis 7 emplacements mondiaux avec suivi de latence |
| Scalabilité | Fédération complexe ou déploiement Thanos/Cortex requis pour le scaling multi-cluster | Scaling horizontal automatique, ajoutez simplement des agents et la plateforme gère le reste |
| Maintenance | Mises à jour manuelles, stratégies de sauvegarde, politiques de rétention et patchs de sécurité pour chaque composant | Zéro maintenance requise, mises à jour automatiques et sauvegardes managées avec disponibilité garantie |
| Création de Tableaux de Bord | Requêtes PromQL manuelles, des heures de configuration de panneaux et de variables par tableau de bord | Tableaux de bord pré-construits pour tous les services détectés, prêts en secondes sans écriture de requêtes |
| Compatibilité Prometheus | Prometheus natif, mais nécessite un déploiement Prometheus auto-géré complet | Scrape les exporters Prometheus nativement, pas besoin de serveur Prometheus séparé |
| Rétention des Données | Par défaut 15 jours, le long terme nécessite Thanos ou Mimir avec stockage objet | Un an de rétention inclus, sans infrastructure ni configuration de stockage supplémentaire |
| Courbe d'Apprentissage | Raide : PromQL, LogQL, routage Alertmanager, règles de relabeling et configuration YAML | Interface web intuitive, productif en quelques heures sans langage de requête requis |
Coût Total de Possession
Stack Grafana
Bleemeo
*Avec réservation 1 an. Logs facturés séparément à 0,50€/Gio.
Pourquoi Choisir Bleemeo
Plateforme Tout-en-Un
Arrêtez de jongler avec Prometheus, Loki, Alertmanager, Thanos et Grafana comme composants séparés. Bleemeo fournit la collecte de métriques, l'agrégation de logs, le monitoring de disponibilité, les alertes intelligentes et les tableaux de bord en temps réel dans une seule plateforme intégrée. Tout fonctionne ensemble directement, éliminant la dérive de configuration et les incompatibilités de versions entre composants.
Agent Intelligent
L'agent Bleemeo découvre automatiquement les services en cours d'exécution, les conteneurs, les bases de données et les serveurs web sur chaque host. Il collecte les métriques système, les métriques spécifiques aux applications et les logs sans que vous ayez besoin d'installer ou de configurer des exporters séparés. Un seul agent remplace node_exporter, process-exporter et des dizaines d'exporters spécifiques aux applications, réduisant drastiquement votre surface de déploiement.
Zéro Infrastructure
Pas de serveurs Prometheus à scaler, pas de clusters Loki à gérer, pas de compacteurs Thanos à régler, et pas de composants à patcher ou mettre à jour. Bleemeo gère toute l'infrastructure backend, incluant la haute disponibilité, la réplication des données et le stockage long terme. Votre équipe récupère les heures d'ingénierie précédemment consacrées à maintenir la stack de monitoring elle-même opérationnelle.
Compatible Prometheus
Vous avez déjà investi dans des exporters Prometheus et des métriques personnalisées ? Glouton, l'agent Bleemeo, supporte nativement le format d'exposition Prometheus et peut scraper directement vos endpoints d'exporters existants. Aucun serveur Prometheus séparé n'est nécessaire, rendant la migration graduelle et sans risque. Vos connaissances PromQL existantes et vos métriques personnalisées sont entièrement préservées.
Alertes Intelligentes
Bleemeo inclut une détection d'anomalies intégrée qui apprend les comportements normaux de votre infrastructure et vous alerte quand quelque chose dévie. Le routage intelligent des alertes délivre les notifications par email, Slack, PagerDuty ou notifications push mobiles sans nécessiter d'arbres de routage Alertmanager complexes. Les alertes à seuil viennent pré-configurées pour les services courants, vous obtenez donc des alertes significatives dès le premier jour.
Beaux Tableaux de Bord
Bleemeo fournit des tableaux de bord modernes et responsives automatiquement générés pour chaque service découvert. Contrairement à Grafana où vous passez des heures à écrire des requêtes PromQL et configurer des panneaux, les tableaux de bord Bleemeo sont prêts immédiatement avec des paramètres par défaut pertinents. Vous pouvez toujours créer des vues personnalisées et explorer des métriques spécifiques, mais l'expérience par défaut couvre la plupart des besoins de monitoring sans aucune configuration manuelle.
Transition Facile depuis la Stack Grafana
La migration depuis la stack Grafana n'a pas besoin d'être un big-bang. Vous pouvez faire tourner Bleemeo en parallèle de votre installation Prometheus et Grafana existante, valider la couverture et désactiver progressivement les composants dont vous n'avez plus besoin. Le processus complet prend généralement moins d'une semaine pour la plupart des équipes.
Déployer les Agents Bleemeo
Installez l'agent Bleemeo sur chaque serveur avec une seule commande. L'agent fonctionne aux côtés de vos exporters Prometheus existants sans conflit et commence immédiatement à collecter les métriques système, découvrir les services et envoyer les données à la plateforme Bleemeo :
wget -qO- 'https://get.bleemeo.com?accountId=...' | sudo bashVérifier la Couverture
Connectez-vous à la console Bleemeo et vérifiez que tous vos serveurs, conteneurs et services apparaissent automatiquement. L'agent détecte les bases de données comme MySQL et PostgreSQL, les serveurs web comme Nginx et Apache, les files de messages comme RabbitMQ et Kafka, et bien d'autres services sans aucune configuration manuelle. Comparez les services découverts avec vos scrape targets Prometheus existants pour garantir une couverture complète.
Connecter les Exporters Existants
Si vous avez des exporters Prometheus personnalisés ou des métriques instrumentées par l'application, configurez Glouton pour scraper directement leurs endpoints. Glouton supporte nativement le format d'exposition Prometheus standard, vos métriques personnalisées existantes sont donc préservées sans modification.
Configurer les Alertes
Configurez vos canaux de notification comme email, Slack, PagerDuty ou intégrations webhook. Bleemeo est livré avec des seuils d'alerte par défaut sensibles pour le CPU, la mémoire, le disque et la disponibilité des services. Revoyez ces paramètres par défaut, ajustez les seuils en fonction de vos SLO et ajoutez des règles d'alerte personnalisées pour les métriques spécifiques aux applications. De nombreuses équipes constatent que la détection d'anomalies intégrée de Bleemeo détecte des problèmes que leurs règles Alertmanager artisanales manquaient.
Valider en Parallèle
Faites tourner Bleemeo en parallèle de votre stack Grafana existante pendant une période de validation. Comparez les alertes, tableaux de bord et couverture de métriques entre les deux systèmes. Cette opération en parallèle garantit que vous avez une confiance totale dans Bleemeo avant d'apporter des modifications à votre installation existante. La plupart des équipes font tourner les deux systèmes pendant une à deux semaines.
Désactiver et Simplifier
Une fois la validation terminée, désactivez progressivement les composants de la stack Grafana dont vous n'avez plus besoin. Supprimez les serveurs Prometheus, les clusters Loki, les instances Alertmanager et la flotte d'exporters de votre infrastructure. Cela libère des ressources de calcul, réduit votre surface d'attaque et élimine la charge d'astreinte liée à la maintenance de la plateforme de monitoring elle-même. Votre équipe peut désormais se concentrer entièrement sur la construction et l'exploitation de votre produit réel.
Ce que disent nos clients
Ingénieurs et CTO font confiance à Bleemeo pour surveiller leur infrastructure
Pendant une courte pause déjeuner, nous avons installé Bleemeo, créé une métrique personnalisée, testé les alertes et étions prêts pour la production. La rapidité de déploiement est remarquable.

Le support Bleemeo est tout simplement légendaire — rapide, compétent et toujours présent quand on en a besoin.
Le déploiement de Bleemeo a été incroyablement rapide. En environ une heure, nous l'avons déployé sur plus de 100 serveurs et avons immédiatement obtenu une visibilité complète sur notre infrastructure.

Nous avons mis en place le monitoring de tous nos serveurs en quelques heures seulement. Le tableau de bord est clair, puissant et véritablement agréable à utiliser.

Nous avons déployé Bleemeo sur l'ensemble de notre infrastructure serveur en quelques heures seulement. Le monitoring de disponibilité nous alerte désormais instantanément dès qu'un service rencontre un problème.

Notre stack Prometheus + Grafana était devenu un projet de maintenance. Avec Bleemeo, nous avons déployé l'agent en quelques minutes et avons enfin pu nous concentrer sur l'utilisation du monitoring au lieu de sa maintenance.
Après l'installation de l'agent, Bleemeo a automatiquement découvert nos bases de données, conteneurs et services. En une heure, nous avions une visibilité complète sur l'infrastructure — sans tableaux de bord ni exporters à créer.
Bleemeo a remplacé plusieurs outils de monitoring par une plateforme unique. Métriques, alertes et logs sont désormais au même endroit, ce qui fait gagner un temps considérable à notre équipe.
Bleemeo nous a donné une visibilité immédiate sur notre infrastructure sans la complexité habituelle. En quelques heures, nous avions des métriques, des alertes et des tableaux de bord pleinement opérationnels.
La mise en place de Bleemeo a été d'une simplicité rafraîchissante. Le déploiement de l'agent a pris quelques minutes et la découverte automatique nous a fait économiser des jours de configuration.
Grâce à Bleemeo, notre équipe détecte désormais les problèmes avant que nos utilisateurs ne les remarquent. Les alertes sont fiables et l'interface rend le dépannage bien plus rapide.
Le passage à Bleemeo a considérablement simplifié notre stack de monitoring. Au lieu de gérer plusieurs outils, tout ce dont nous avons besoin est disponible sur une seule plateforme.
La centralisation de nos logs dans Bleemeo a drastiquement simplifié le dépannage. Au lieu de jongler entre les outils, nous pouvons désormais corréler métriques et logs instantanément pour comprendre ce qui se passe.
Bleemeo a rendu le monitoring Kubernetes étonnamment simple. En quelques minutes, nous avions une visibilité sur nos clusters, pods et workloads sans avoir à construire des tableaux de bord complexes nous-mêmes.
Voir Bleemeo en action
Découvrez comment les équipes passent de l'installation au monitoring complet en moins de 5 minutes
Questions fréquentes
Bleemeo peut-il remplacer la stack Grafana complète ?
Oui. Bleemeo remplace Grafana, Prometheus, Loki, Alertmanager et Mimir par une seule plateforme managée. Métriques, logs, tableaux de bord et alertes sont tous inclus.
Dois-je construire les tableaux de bord à partir de zéro ?
Non. Bleemeo pré-construit des tableaux de bord pour chaque service auto-découvert. Des tableaux de bord personnalisés sont également disponibles si vous avez besoin de vues spécifiques.
Bleemeo supporte-t-il les métriques Prometheus ?
Oui. Glouton, l'agent Bleemeo, scrape les exporters Prometheus nativement, donc les exporters existants et l'instrumentation personnalisée fonctionnent directement.
Qu'en est-il de Grafana Cloud ?
La tarification de Grafana Cloud évolue avec l'usage (métriques, logs, traces). La tarification par agent de Bleemeo est prévisible quel que soit le volume de données — pas de frais par série ou par Go.
Puis-je utiliser Bleemeo en parallèle de mon installation Grafana existante ?
Oui. Vous pouvez faire tourner les agents Bleemeo en parallèle de votre stack Grafana actuelle pendant la migration. Glouton fonctionne de manière indépendante et n'interférera pas avec Prometheus ou d'autres collecteurs.
Bleemeo supporte-t-il les tableaux de bord personnalisés ?
Oui. Bien que Bleemeo pré-construise des tableaux de bord pour chaque service découvert, vous pouvez également créer des tableaux de bord personnalisés avec des widgets glisser-déposer pour les vues spécifiques dont votre équipe a besoin.
Y a-t-il une offre gratuite ?
Oui. Surveillez jusqu'à 3 serveurs gratuitement sans limite de temps. Toutes les fonctionnalités incluses — tableaux de bord, alertes, logs, découverte de services.
Comment la gestion des logs se compare-t-elle à Loki ?
Bleemeo inclut la collecte et la recherche centralisées de logs à 0,50€/Gio ingéré. Pas de déploiement Loki séparé, pas d'agents Promtail, pas de backend de stockage à gérer.
Prêt à Laisser la Complexité de la Stack LGTM Derrière Vous ?
Rejoignez des centaines d'équipes d'ingénierie qui sont passées de la gestion séparée de Prometheus, Loki, Alertmanager et Grafana à une plateforme unique qui fonctionne simplement. Commencez votre essai gratuit aujourd'hui et découvrez le monitoring d'infrastructure complet sans la charge opérationnelle. Déployez votre premier agent en moins de cinq minutes et voyez les métriques arriver immédiatement.
Sans carte bancaire • Essai gratuit 15 jours • Fonctionne avec votre stack Grafana existante • Accès complet aux fonctionnalités