Una alternativa gestionada a Prometheus autoalojado
Prometheus es el estándar para métricas, pero ejecutarlo en producción implica gestionar Alertmanager, Grafana, almacenamiento a largo plazo y planificación de capacidad. Bleemeo le ofrece la misma visibilidad con cero servidores que aprovisionar y cero alertas nocturnas sobre su stack de monitorización.
Prueba gratuita de 15 días • Sin tarjeta de crédito • Precios predecibles siempre
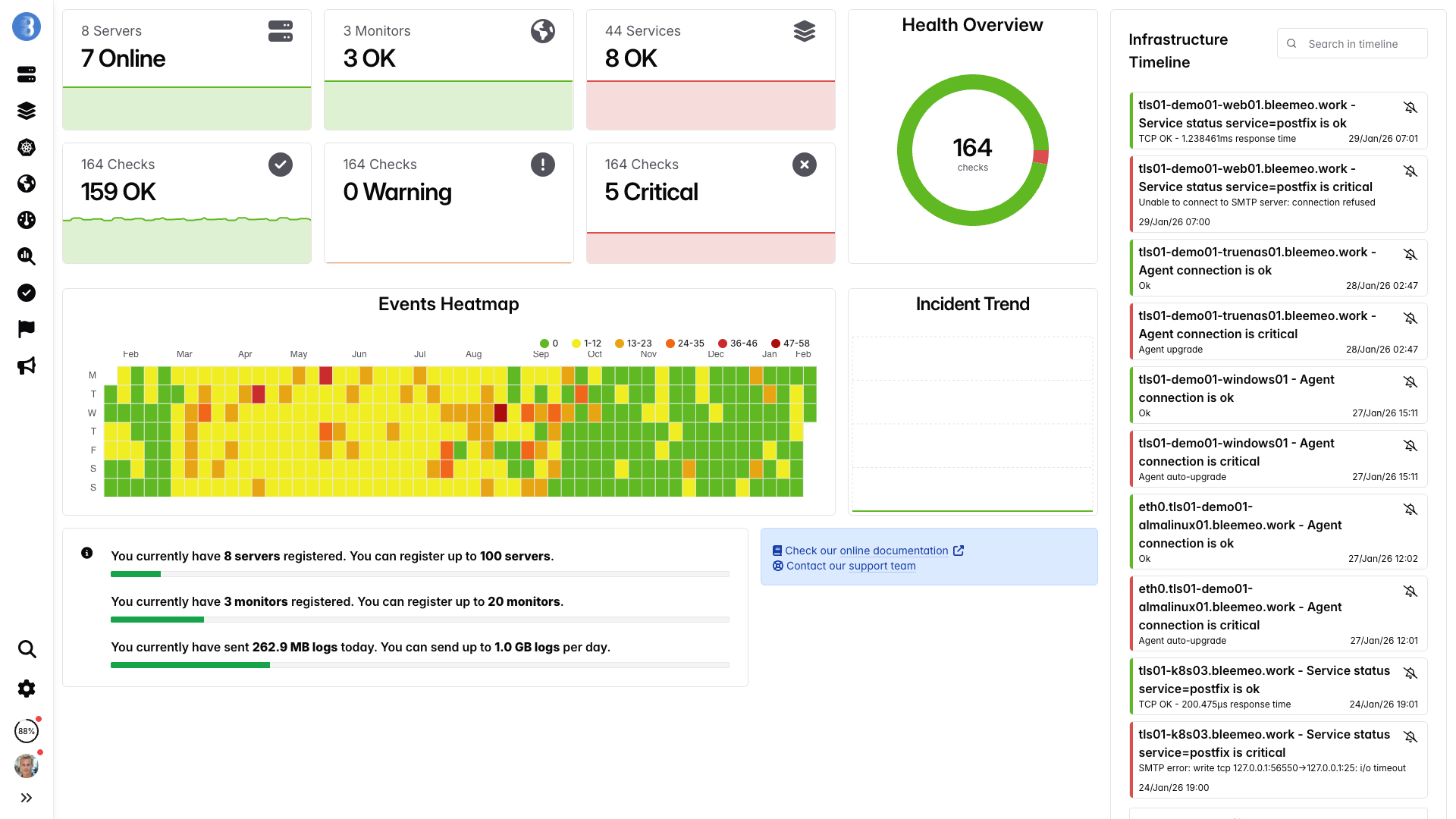
Dashboards en tiempo real, listos en minutos — sin configuración necesaria
Desafíos comunes de Prometheus
Sobrecarga de infraestructura
Ejecutar Prometheus a escala implica mantener múltiples instancias, configurar federación o sharding, y construir pipelines para mover datos entre componentes. Cada instancia adicional requiere su propia asignación de recursos, configuración de scraping y reglas de grabación — creando una carga operativa que crece linealmente con su infraestructura.
Complejidad de almacenamiento
Prometheus tiene por defecto solo 15 días de retención, lo que significa que cualquier análisis histórico o planificación de capacidad requiere una solución de almacenamiento a largo plazo separada. Thanos, Cortex y Mimir resuelven este problema pero introducen su propia arquitectura, dependencias de almacenamiento de objetos y procesos de compactación que necesitan ajuste y monitorización cuidadosos.
Configuración de dashboards y alertas
Prometheus viene solo con un navegador de expresiones básico — sin dashboards integrados ni interfaz pulida. Necesita Grafana para visualización y Alertmanager para notificaciones, ambos requieren configuración manual. Cada panel de dashboard, cada regla de alerta y cada regla de grabación debe escribirse a mano en PromQL y mantenerse mediante control de versiones a medida que su infraestructura evoluciona.
Desafíos de escalabilidad
Las métricas de alta cardinalidad de entornos dinámicos como Kubernetes pueden causar picos repentinos de memoria y OOM kills que deriban todo su stack de monitorización. Escalar Prometheus requiere sharding entre múltiples instancias o configurar jerarquías de federación, y las políticas de retención deben equilibrarse cuidadosamente contra el espacio en disco disponible. La planificación de capacidad se convierte en una tarea recurrente que aleja a los ingenieros del trabajo productivo.
Prometheus vs Bleemeo
| Característica | Prometheus (autoalojado) | Bleemeo |
|---|---|---|
| Tiempo de configuración | Horas a días de configuración | 5 minutos, un solo comando |
| Infraestructura requerida | Prometheus + Alertmanager + Grafana + almacenamiento | Ninguna — SaaS totalmente gestionado |
| Almacenamiento a largo plazo | Thanos/Cortex/Mimir requerido | 13 meses incluidos |
| Descubrimiento de servicios | Configuración manual de scraping por objetivo | Automático, sin configuración |
| Dashboards | Construir en Grafana desde cero | Preconstruidos, auto-activados |
| Reglas de alerta | Escribir y mantener reglas PromQL | Valores predeterminados inteligentes + detección de anomalías ML |
| Alta disponibilidad | Stacks duplicados + federación | Redundancia integrada |
| Mantenimiento | Actualizaciones, escalado, resolución de problemas | Cero — nosotros nos encargamos de todo |
| Modelo de red | Basado en pull: requiere acceso de red a todos los objetivos | Basado en push: los agentes envían datos salientes, sin puertos entrantes necesarios |
| Gestión de cardinalidad | La alta cardinalidad causa presión de memoria y OOM kills | Gestionada del lado del servidor con controles automáticos de cardinalidad |
| Gestión de logs | No incluido — requiere Loki o stack separado | Recopilación y búsqueda de logs integradas junto a las métricas |
| Compatibilidad PromQL | Nativo | Métricas compatibles con Prometheus |
| Agente open source | Exporters Prometheus | Glouton (Apache 2.0) |
Comparación real de costes
Para una infraestructura típica de 100 servidores con Prometheus autoalojado, el coste real va mucho más allá del cómputo y almacenamiento — incluye las horas de ingeniería dedicadas a mantener, resolver problemas y escalar su stack de monitorización en lugar de construir funcionalidades de producto.
Prometheus (autoalojado)
*Más costes ocultos: fatiga de guardia, silos de conocimiento y coste de oportunidad de ingenieros que no trabajan en producto
Bleemeo
*Con reserva de 1 año. Sin costes de infraestructura.
Por qué los equipos eligen Bleemeo
Cero infraestructura
Sin servidores Prometheus que mantener, sin clústeres Thanos que vigilar, sin instancias Grafana que actualizar y sin buckets de almacenamiento de objetos que gestionar. Bleemeo se encarga de toda la infraestructura para que su equipo pueda concentrarse en construir funcionalidades de producto en lugar de mantener vivo el stack de monitorización. Nunca más tendrá que preocuparse por el espacio en disco, la presión de memoria o los OOM kills en su capa de observabilidad.
Compatible con Prometheus
Glouton hace scraping de exporters Prometheus directamente y mantiene sus exporters y código de instrumentación existentes intactos. Bleemeo soporta los mismos formatos de métricas y etiquetas compatibles con Prometheus que ya usa, haciéndolo un reemplazo directo para su backend Prometheus sin reescribir una sola regla de grabación o configuración de relabeling.
Descubrimiento automático
A diferencia de Prometheus, que requiere configuración manual de scraping para cada nuevo objetivo, el agente Glouton de Bleemeo detecta automáticamente los servicios en ejecución — bases de datos, servidores web, brokers de mensajería y más — y comienza a recopilar las métricas correctas inmediatamente. Sin editar YAML, sin plugins de descubrimiento de servicios, sin reglas de relabeling que mantener.
Todo preconstruido
Mientras Prometheus le da un navegador de expresiones en blanco, Bleemeo proporciona dashboards preconstruidos, umbrales de alerta inteligentes y detección de anomalías con ML que se activan automáticamente en el momento en que se descubre un servicio. No más pasar días creando paneles en Grafana o escribiendo reglas de alerta PromQL desde cero para cada nueva aplicación que despliegue.
Agente open source
Glouton, nuestro agente de monitorización, es completamente open source bajo la licencia Apache 2.0. Puede auditar cada línea de código que se ejecuta en sus servidores, contribuir mejoras y tener la tranquilidad de que no hay dependencia de proveedor. Sus datos de métricas siguen siendo suyos, y puede exportarlos en cualquier momento usando formatos estándar de Prometheus.
Residencia de datos en Europa
Todos sus datos de monitorización se almacenan en centros de datos europeos con cumplimiento total del RGPD integrado desde el primer día. A diferencia de alternativas SaaS con sede en EE.UU., Bleemeo es una empresa europea que mantiene su telemetría de infraestructura bajo jurisdicción de la UE, ofreciéndole un cumplimiento sencillo para los requisitos de residencia de datos.
Paridad de funciones donde importa
Monitorización de infraestructura
Monitorización completa de CPU, memoria, disco, red y procesos con descubrimiento automático de servicios que detecta bases de datos, servidores web y runtimes de aplicaciones sin ninguna configuración. Obtenga mayor visibilidad que las métricas estándar de node_exporter de Prometheus desde el primer momento.
Contenedores y Kubernetes
Soporte nativo de Docker y Kubernetes con métricas a nivel de pod, monitorización de salud de nodos y vistas generales de todo el clúster. A diferencia de Prometheus, que requiere kube-state-metrics, cAdvisor y reglas de relabeling complejas, Bleemeo proporciona monitorización de contenedores que funciona inmediatamente después de instalar el agente.
Gestión de logs
Recopile, indexe y busque logs junto a sus métricas en una plataforma unificada. Prometheus no tiene gestión de logs en absoluto — los equipos típicamente agregan Loki, Elasticsearch o Splunk como otro sistema más que gestionar. Con Bleemeo, logs y métricas conviven, haciendo el análisis de causa raíz más rápido y sencillo.
Alertas inteligentes
La detección de anomalías basada en machine learning identifica patrones inusuales antes de que se conviertan en incidencias, complementando umbrales de alerta preconfigurados para cada servicio descubierto. No más escribir y ajustar manualmente reglas de alerta PromQL o mantener árboles de enrutamiento de Alertmanager — los valores predeterminados inteligentes cubren los casos comunes mientras usted personaliza lo que más importa.
Dashboards personalizados
Construya las vistas exactas que su equipo necesita con widgets intuitivos de arrastrar y soltar, o comience desde la rica biblioteca de dashboards preconstruidos que se activan automáticamente. A diferencia de Grafana, donde cada panel requiere consultas PromQL manuales y configuración JSON, los dashboards de Bleemeo están listos para usar en el momento en que sus agentes se conectan.
Monitorización de uptime
Verificaciones de uptime HTTP, TCP e ICMP desde múltiples ubicaciones globales, con monitorización de expiración de certificados SSL y seguimiento del tiempo de respuesta. El blackbox_exporter de Prometheus ofrece sondeos básicos, pero Bleemeo ofrece un enfoque totalmente gestionado y multiubicación con alertas integradas y páginas de estado que no requieren infraestructura de su parte.
Migrar desde Prometheus
La mayoría de los equipos ejecutan ambos sistemas en paralelo durante unas semanas antes de cambiar completamente. La migración es directa y no disruptiva — los agentes de Bleemeo funcionan junto a su configuración existente de Prometheus sin conflictos. Nuestro equipo está disponible para ayudar con la planificación y validación de la migración en cada paso.
Desplegar agentes Bleemeo
Instale el agente Bleemeo junto a sus exporters Prometheus existentes con un solo comando. El agente funciona de forma independiente y no interfiere con su stack de monitorización actual, por lo que hay cero riesgo durante el período de transición:
wget -qO- 'https://get.bleemeo.com?accountId=...' | sudo bashVerificar descubrimiento
Abra el dashboard de Bleemeo y verifique que todos sus servidores y servicios han sido detectados automáticamente. Compare la lista de servicios descubiertos con sus objetivos de scraping de Prometheus para confirmar la cobertura completa. Glouton identifica bases de datos, servidores web, brokers de mensajería y runtimes de aplicaciones sin ningún archivo de configuración.
Configurar exporters personalizados (opcional)
Si tiene exporters Prometheus personalizados o instrumentación a nivel de aplicación, configure Glouton para hacer scraping de sus endpoints directamente. Esto le da una vista unificada de métricas recopiladas por el agente y por scraping de exporters en una sola plataforma, mientras conserva sus etiquetas y nombres de métricas existentes.
Validar dashboards
Revise los dashboards preconstruidos de Bleemeo y compárelos lado a lado con sus paneles existentes de Grafana. Confirme que las métricas, rangos de tiempo y granularidad satisfacen sus necesidades operativas. La mayoría de los equipos descubren que los dashboards automáticos de Bleemeo cubren sus casos de uso clave sin necesidad de personalización.
Configurar notificaciones
Configure sus canales de notificación preferidos — Slack, PagerDuty, email, Microsoft Teams o webhooks personalizados — para reemplazar su configuración de enrutamiento de Alertmanager. Las alertas de Bleemeo vienen con umbrales predeterminados sensatos ya activos para cada servicio descubierto, así que está cubierto desde el inicio mientras ajusta las preferencias de notificación.
Desmantelar el stack Prometheus
Una vez que haya validado que Bleemeo proporciona cobertura completa y su equipo está cómodo con los nuevos dashboards y alertas, desmantele sus servidores Prometheus autoalojados, clústeres de Alertmanager, instancias de Grafana y backends de almacenamiento Thanos o Mimir. Recupere los recursos de cómputo y libere a su equipo de ingeniería del mantenimiento del stack de monitorización de forma permanente.
Lo que dicen nuestros clientes
Ingenieros y CTOs confían en Bleemeo para monitorear su infraestructura
Durante una breve pausa para almorzar, instalamos Bleemeo, creamos una métrica personalizada, probamos las alertas y estábamos listos para producción. La velocidad de despliegue es notable.

El soporte de Bleemeo es simplemente legendario: rápido, competente y siempre disponible cuando lo necesitamos.
Bleemeo fue increíblemente rápido de desplegar. En aproximadamente una hora lo implementamos en más de 100 servidores y obtuvimos visibilidad completa de nuestra infraestructura de inmediato.

Configuramos el monitoreo de todos nuestros servidores en solo unas pocas horas. El dashboard es claro, potente y realmente agradable de usar.

Desplegamos Bleemeo en toda nuestra infraestructura de servidores en solo unas pocas horas. El monitoreo de disponibilidad ahora nos alerta instantáneamente cuando un servicio tiene un problema.

Nuestra pila de Prometheus + Grafana se había convertido en un proyecto de mantenimiento. Con Bleemeo desplegamos el agente en minutos y finalmente nos enfocamos en usar el monitoreo en lugar de mantenerlo.
Después de instalar el agente, Bleemeo descubrió automáticamente nuestras bases de datos, contenedores y servicios. En una hora teníamos visibilidad completa de la infraestructura, sin dashboards ni exporters que construir.
Bleemeo reemplazó varias herramientas de monitoreo con una sola plataforma. Métricas, alertas y logs están ahora en un solo lugar, ahorrando a nuestro equipo un tiempo significativo.
Bleemeo nos dio una visión inmediata de nuestra infraestructura sin la complejidad habitual. En un par de horas teníamos métricas, alertas y dashboards funcionando sin problemas.
Configurar Bleemeo fue sorprendentemente simple. El despliegue del agente tomó minutos y el descubrimiento automático nos ahorró días de configuración.
Gracias a Bleemeo, nuestro equipo ahora detecta problemas antes de que los usuarios los noten. Las alertas son fiables y la interfaz hace que la resolución de problemas sea mucho más rápida.
Migrar a Bleemeo simplificó drásticamente nuestra pila de monitoreo. En lugar de gestionar múltiples herramientas, todo lo que necesitamos está disponible en una sola plataforma.
Centralizar nuestros logs en Bleemeo simplificó drásticamente la resolución de problemas. En lugar de saltar entre herramientas, ahora podemos correlacionar métricas y logs instantáneamente para entender qué está pasando.
Bleemeo hizo que el monitoreo de Kubernetes fuera sorprendentemente fácil. En minutos teníamos visibilidad de nuestros clusters, pods y cargas de trabajo sin tener que construir dashboards complejos nosotros mismos.
Vea Bleemeo en acción
Descubra cómo los equipos pasan de la instalación a la monitorización completa en menos de 5 minutos
Preguntas frecuentes
¿Puede Bleemeo reemplazar un stack Prometheus autoalojado?
Sí. Bleemeo recopila las mismas métricas de infraestructura, hace scraping nativo de exporters Prometheus para métricas personalizadas, e incluye dashboards, alertas y 13 meses de almacenamiento — sin ejecutar ningún servidor.
¿Bleemeo soporta PromQL?
Glouton, el agente de Bleemeo, hace scraping de exporters Prometheus de forma nativa usando el formato de exposición estándar. Sus exporters e instrumentación existentes funcionan directamente.
¿Qué pasa con el almacenamiento a largo plazo?
Bleemeo almacena métricas a resolución completa durante 13 meses, incluido en el precio base. No necesita Thanos, Cortex ni Mimir.
¿El agente de Bleemeo es open source?
Sí. Glouton tiene licencia Apache 2.0 y soporta descubrimiento automático de servicios para más de 100 servicios — sin configuraciones de scraping necesarias.
¿Bleemeo soporta métricas personalizadas de exporters Prometheus?
Sí. Glouton hace scraping nativo de cualquier endpoint de exporter Prometheus. Sus exporters e instrumentación personalizada existentes funcionan sin modificación.
¿Qué pasa con las alertas sin Alertmanager?
Bleemeo incluye umbrales de alerta preconfigurados para cada servicio descubierto, además de detección de anomalías basada en ML. Notificaciones por email, Slack, PagerDuty y webhooks — sin Alertmanager que configurar.
¿Hay un plan gratuito?
Sí. Monitorice hasta 3 servidores gratis sin límite de tiempo. Todas las funciones incluidas — dashboards, alertas, descubrimiento de servicios.
¿Puedo mantener algunas instancias de Prometheus funcionando junto a Bleemeo?
Sí. Muchos equipos ejecutan ambos durante la migración. Glouton opera de forma independiente y no interfiere con el scraping existente de Prometheus.
¿Listo para dejar de mantener su stack de monitorización?
Deje de gastar horas de ingeniería en actualizaciones de Prometheus, problemas de compactación de Thanos y mantenimiento de dashboards de Grafana. Obtenga monitorización lista para producción con 13 meses de retención, descubrimiento automático de servicios y alertas inteligentes — todo sin un solo servidor que gestionar.
Sin tarjeta de crédito • Plan gratuito disponible • Cancele cuando quiera