Una alternativa moderna a Nagios
Nagios fue pionero en monitoreo en los años 2000, pero su arquitectura basada en plugins y sus archivos de configuración manual no han seguido el ritmo de la infraestructura moderna. Bleemeo le ofrece descubrimiento automático, dashboards integrados y alertas impulsadas por ML — sin plugins, sin NRPE, sin objects.cfg.
Prueba gratuita de 15 días · Sin tarjeta de crédito · Migre en minutos
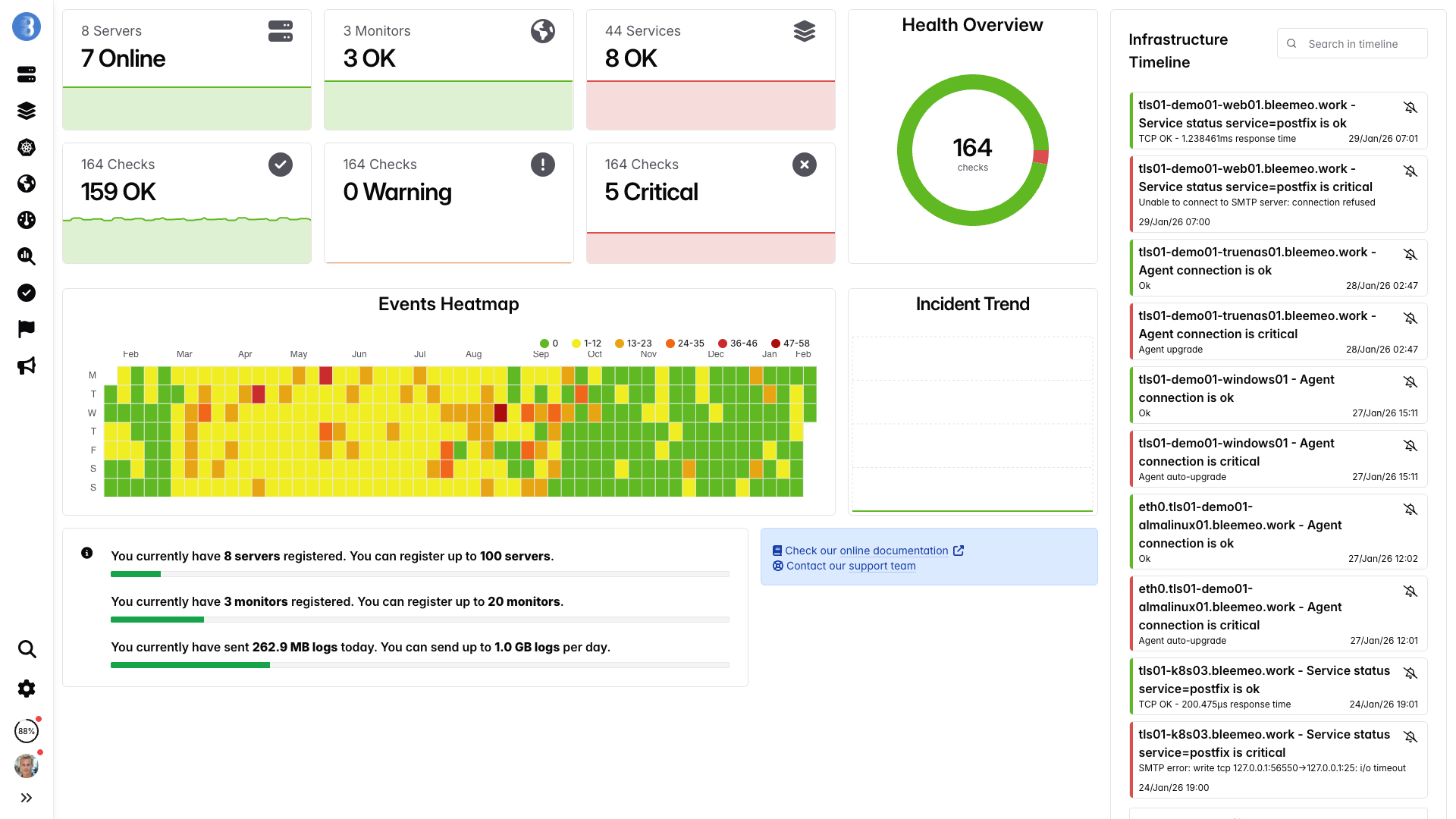
Dashboards en tiempo real, listos en minutos — sin configuración necesaria
Por qué los equipos están dejando Nagios
Configuración que consume tiempo
Configurar Nagios requiere editar archivos de texto complejos como hosts.cfg, services.cfg y commands.cfg, y luego recargar el demonio por cada cambio. Cada nuevo host o servicio debe definirse manualmente con comandos de verificación, intervalos, períodos de notificación, grupos de contacto y umbrales — a menudo decenas de líneas por objeto. Un solo error de sintaxis puede impedir que el demonio de Nagios reinicie, dejando su monitoreo ciego hasta que se encuentre y corrija el problema. Lo que lleva días o semanas con Nagios, toma solo minutos con el descubrimiento automático de Bleemeo, que detecta servicios, contenedores y componentes de infraestructura en cuanto se instala el agente.
Carga de mantenimiento
Ejecutar Nagios significa que usted es responsable del propio servidor de monitoreo: parches del SO, actualizaciones de Apache o PHP, compatibilidad de plugins, espacio en disco para datos de rendimiento y actualizaciones del agente NRPE en cada servidor de su flota. Cada agente NRPE debe configurarse individualmente con comandos de verificación permitidos y reglas de firewall, creando una superficie de mantenimiento que crece linealmente con su infraestructura. La comunidad de Nagios se ha fragmentado en forks como Icinga 2, Naemon y Shinken, dificultando encontrar plugins actualizados, add-ons compatibles y documentación fiable. Bleemeo es una plataforma SaaS totalmente gestionada — sin servidores que parchear, sin agentes que configurar manualmente y sin repositorios de plugins que auditar — para que su equipo pueda enfocarse en resolver incidentes en lugar de cuidar el stack de monitoreo.
No es cloud-native
Nagios fue diseñado para centros de datos estáticos on-premise donde los hosts rara vez cambian y las direcciones IP son fijas. No tiene soporte nativo para contenedores, pods de Kubernetes, grupos de autoescalado ni funciones serverless. Cada vez que una instancia cloud escala hacia arriba o abajo, la definición del host correspondiente debe agregarse o eliminarse manualmente — o mediante scripts externos frágiles — generando alertas obsoletas, desviación de configuración y notificaciones fantasma de hosts que ya no existen. Bleemeo fue construido desde el primer día para entornos efímeros y cloud-native donde la infraestructura cambia constantemente.
Interfaz anticuada
La interfaz web predeterminada de Nagios — conocida como interfaz CGI — apenas ha cambiado en más de una década. Solo ofrece tablas básicas de estado de hosts y servicios, sin dashboards en tiempo real, gráficos interactivos de series temporales ni diseño responsive para móviles. La mayoría de equipos terminan instalando frontends de terceros como Thruk, Adagios, o añadiendo Grafana con PNP4Nagios solo para obtener visualizaciones utilizables, agregando aún más componentes que mantener y asegurar. Bleemeo proporciona dashboards modernos y personalizables con streaming de métricas en tiempo real y apps nativas para iOS y Android listas para usar, sin necesidad de combinar múltiples herramientas para obtener visibilidad básica.
Nagios vs Bleemeo
| Característica | Nagios | Bleemeo |
|---|---|---|
| Tiempo de configuración | Días a semanas de definiciones manuales de hosts y servicios | Minutos con un solo comando de instalación del agente |
| Configuración | Edición manual de objects.cfg, commands.cfg y contacts.cfg | Descubrimiento automático de servicios, contenedores e infraestructura |
| Cloud-Native | Sin soporte para contenedores ni Kubernetes; solo modelo de hosts estático | Integración nativa con Kubernetes, Docker y proveedores cloud |
| Apps móviles | Sin aplicación móvil oficial disponible | Apps nativas iOS y Android con notificaciones push |
| Alertas | Notificaciones básicas por email y pager mediante scripts personalizados | Enrutamiento inteligente con SMS, Slack, Teams, PagerDuty y webhooks |
| Mantenimiento | Servidor auto-alojado que requiere parches del SO, actualizaciones de plugins y gestión de NRPE | Plataforma SaaS totalmente gestionada con cero mantenimiento de servidor |
| Dashboards | UI integrada anticuada; requiere Thruk o Grafana para dashboards utilizables | Dashboards modernos y personalizables |
| Gestión de logs | No incluida; requiere desplegar un stack ELK o Graylog aparte | Recopilación, búsqueda y análisis de logs integrados en la misma plataforma |
| Detección de anomalías | Solo umbrales estáticos; sin machine learning ni análisis de tendencias | Detección de anomalías impulsada por ML con aprendizaje automático de líneas base |
| Prometheus y OpenTelemetry | Sin soporte nativo; arquitectura basada en checks incompatible | Scraping nativo de exporters Prometheus y soporte de colector OpenTelemetry |
| Escalabilidad | Arquitectura de servidor único; configuraciones distribuidas requieren add-ons complejos como Mod Gearman o DNX | SaaS cloud-native que escala automáticamente de 10 a más de 10.000 agentes |
| API | Interfaz de comandos externos limitada vía command pipe; sin API REST en Core | API REST completa para automatización, integración y flujos de trabajo personalizados |
| Monitoreo de disponibilidad | Plugin check_http básico; sin sondeo multi-ubicación ni reportes SLA | Verificaciones de disponibilidad globales desde múltiples ubicaciones con dashboards SLA |
| Precios | Core es gratuito pero Nagios XI desde $2.495; más infraestructura, tiempo de sysadmin y herramientas de terceros | Precio simple por agente a 10,99 EUR/mes, todas las funciones incluidas, sin costos ocultos |
Costo total de propiedad: Nagios vs Bleemeo
Nagios Core puede ser open source, pero el costo real reside en la infraestructura, el tiempo de ingeniería y las herramientas de terceros necesarias para ejecutar un stack de monitoreo de nivel producción. Aquí tiene una comparación realista para un entorno de 100 servidores durante un año.
Stack Nagios — Costo anual estimado
- Licencia Nagios XI Standard (100 nodos): $4.495
- Servidor de monitoreo dedicado (hosting + mantenimiento): $3.600/año
- Tiempo de sysadmin para mantenimiento de Nagios (~8 hrs/mes): $9.600/año
- Despliegue de agentes NRPE y mantenimiento de plugins: $2.400/año
- Stack ELK o Graylog para gestión de logs: $6.000/año
- Grafana + PNP4Nagios para dashboards: $1.200/año
- Servicio externo de monitoreo de disponibilidad: $1.800/año
Total: ~$29.095/año
Bleemeo — Costo anual
- 100 agentes a 10,99 EUR/mes cada uno: 13.188 EUR/año
- Con reserva anual (10% de descuento): 11.869 EUR/año
- Métricas, logs, disponibilidad, dashboards, apps móviles: incluido
- Descubrimiento automático y alertas inteligentes: incluido
- Soporte Prometheus y OpenTelemetry: incluido
- Sin servidor que mantener, sin plugins que gestionar: $0
- Tiempo de sysadmin para mantenimiento de monitoreo: casi cero
Total: ~11.869 EUR/año
Qué hace mejor a Bleemeo
Descubrimiento automático
Instale nuestro agente ligero y descubre automáticamente servicios como MySQL, PostgreSQL, Redis, Nginx, Apache, contenedores Docker y pods Kubernetes. No hay archivos de configuración que escribir, ni comandos de verificación que definir, ni recargas de demonio que ejecutar. Los nuevos servicios se detectan y monitorean en segundos tras aparecer en el host, eliminando las definiciones manuales de objetos que consumen tanto tiempo con Nagios.
Arquitectura cloud-native
Construida desde cero para infraestructura moderna y dinámica. Bleemeo soporta nativamente clusters Kubernetes, runtimes Docker y containerd, instancias AWS, Azure y GCP. Las cargas de trabajo efímeras que escalan arriba y abajo se rastrean automáticamente — sin definiciones de hosts obsoletas, sin alertas fantasma y sin scripts de limpieza manual requeridos.
Alertas inteligentes
La detección de anomalías impulsada por machine learning aprende automáticamente líneas base de comportamiento normal para cada métrica, para que reciba alertas sobre problemas reales en lugar de umbrales estáticos superados. La agrupación inteligente de alertas correlaciona incidentes relacionados para reducir el ruido, y el enrutamiento flexible de notificaciones envía alertas al equipo correcto vía Slack, Microsoft Teams, PagerDuty, SMS o webhooks — previniendo la fatiga de alertas que afecta a los despliegues de Nagios.
Dashboards impresionantes
Dashboards modernos y responsive con streaming de métricas en tiempo real proporcionan visibilidad instantánea de toda su infraestructura. Cree vistas personalizadas en minutos con widgets drag-and-drop, gráficos interactivos de series temporales y mapas de topología. A diferencia de Nagios, no necesita instalar Thruk, Grafana ni PNP4Nagios para obtener visualizaciones utilizables.
Móvil primero
Las aplicaciones nativas para iOS y Android le permiten monitorear toda su infraestructura y responder a incidentes desde cualquier lugar. Reciba notificaciones push en cuanto se detecte un problema, confirme alertas, vea dashboards y profundice en detalles de métricas — todo desde su teléfono o tablet, sin necesidad de VPN para alcanzar un servidor Nagios on-premise.
Plataforma unificada
Métricas, logs, monitoreo de disponibilidad y detección de anomalías unificados en una sola plataforma. Con Nagios, los equipos típicamente combinan herramientas separadas para gestión de logs (ELK o Graylog), dashboards (Grafana) y verificaciones de disponibilidad (servicios externos), creando un stack fragmentado costoso de ejecutar y difícil de correlacionar. Bleemeo reúne todo para que pueda ir de la alerta a la causa raíz en una sola interfaz.
Migrar desde Nagios es fácil
Regístrese e instale el agente
Cree su cuenta gratuita de Bleemeo e instale el agente ligero en cada servidor con un solo comando. El agente soporta Debian, Ubuntu, RHEL, CentOS, Alpine y la mayoría de distribuciones Linux principales. La instalación toma menos de un minuto por host:
wget -qO- 'https://get.bleemeo.com?accountId=...'Verifique el descubrimiento automático
En segundos tras la instalación, el agente descubre automáticamente servicios en ejecución como MySQL, PostgreSQL, Redis, Nginx, Apache, Elasticsearch, contenedores Docker y pods Kubernetes. Inicie sesión en el dashboard de Bleemeo para verificar que todos sus servicios críticos están detectados y las métricas fluyen. Para aplicaciones personalizadas, puede agregar endpoints compatibles con Prometheus o verificaciones personalizadas en minutos.
Configure alertas y notificaciones
Configure canales de notificación — Slack, Microsoft Teams, PagerDuty, SMS, email o webhooks — a través de la interfaz web intuitiva. Bleemeo viene con umbrales predeterminados sensatos para todos los servicios descubiertos, por lo que obtiene alertas significativas de inmediato. Personalice umbrales y reglas de enrutamiento para que coincidan con la estructura de guardia y las políticas de escalado de su equipo sin editar un solo archivo de configuración.
Construya sus dashboards
Cree dashboards personalizados para replicar y mejorar las vistas que tenía en Nagios, Thruk o Grafana. El constructor de dashboards de Bleemeo le permite arrastrar y soltar widgets para CPU, memoria, disco, red y métricas específicas de aplicaciones. Comparta dashboards con su equipo o muéstrelos en pantallas montadas en la pared para conciencia operativa en tiempo real.
Ejecute en paralelo y valide
Mantenga Nagios ejecutándose junto a Bleemeo durante una o dos semanas para validar la cobertura, precisión de alertas y flujos de trabajo del equipo. Compare las alertas generadas por ambos sistemas para ganar confianza en que Bleemeo captura todo lo que Nagios detecta — y más, gracias a la detección de anomalías y la agrupación inteligente de alertas. Este período en paralelo también da tiempo a su equipo para familiarizarse con la nueva interfaz y las apps móviles.
Desactive Nagios
Una vez que su equipo esté seguro con la cobertura y las alertas de Bleemeo, conviértalo en su plataforma de monitoreo principal y desactive Nagios. Elimine el servidor Nagios, desinstale los agentes NRPE de sus hosts y retire la infraestructura asociada. Liberará inmediatamente tiempo de sysadmin que antes se dedicaba al mantenimiento de plugins, gestión de archivos de configuración y mantenimiento del servidor Nagios.
Lo que dicen nuestros clientes
Ingenieros y CTOs confían en Bleemeo para monitorear su infraestructura
Durante una breve pausa para almorzar, instalamos Bleemeo, creamos una métrica personalizada, probamos las alertas y estábamos listos para producción. La velocidad de despliegue es notable.

El soporte de Bleemeo es simplemente legendario: rápido, competente y siempre disponible cuando lo necesitamos.
Bleemeo fue increíblemente rápido de desplegar. En aproximadamente una hora lo implementamos en más de 100 servidores y obtuvimos visibilidad completa de nuestra infraestructura de inmediato.

Configuramos el monitoreo de todos nuestros servidores en solo unas pocas horas. El dashboard es claro, potente y realmente agradable de usar.

Desplegamos Bleemeo en toda nuestra infraestructura de servidores en solo unas pocas horas. El monitoreo de disponibilidad ahora nos alerta instantáneamente cuando un servicio tiene un problema.

Nuestra pila de Prometheus + Grafana se había convertido en un proyecto de mantenimiento. Con Bleemeo desplegamos el agente en minutos y finalmente nos enfocamos en usar el monitoreo en lugar de mantenerlo.
Después de instalar el agente, Bleemeo descubrió automáticamente nuestras bases de datos, contenedores y servicios. En una hora teníamos visibilidad completa de la infraestructura, sin dashboards ni exporters que construir.
Bleemeo reemplazó varias herramientas de monitoreo con una sola plataforma. Métricas, alertas y logs están ahora en un solo lugar, ahorrando a nuestro equipo un tiempo significativo.
Bleemeo nos dio una visión inmediata de nuestra infraestructura sin la complejidad habitual. En un par de horas teníamos métricas, alertas y dashboards funcionando sin problemas.
Configurar Bleemeo fue sorprendentemente simple. El despliegue del agente tomó minutos y el descubrimiento automático nos ahorró días de configuración.
Gracias a Bleemeo, nuestro equipo ahora detecta problemas antes de que los usuarios los noten. Las alertas son fiables y la interfaz hace que la resolución de problemas sea mucho más rápida.
Migrar a Bleemeo simplificó drásticamente nuestra pila de monitoreo. En lugar de gestionar múltiples herramientas, todo lo que necesitamos está disponible en una sola plataforma.
Centralizar nuestros logs en Bleemeo simplificó drásticamente la resolución de problemas. En lugar de saltar entre herramientas, ahora podemos correlacionar métricas y logs instantáneamente para entender qué está pasando.
Bleemeo hizo que el monitoreo de Kubernetes fuera sorprendentemente fácil. En minutos teníamos visibilidad de nuestros clusters, pods y cargas de trabajo sin tener que construir dashboards complejos nosotros mismos.
Vea Bleemeo en acción
Descubra cómo los equipos pasan de la instalación al monitoreo completo en menos de 5 minutos
Preguntas frecuentes
¿Puede Bleemeo reemplazar a Nagios para el monitoreo de servidores?
Sí. Bleemeo monitorea todo lo que Nagios puede — servidores, servicios, red — además de contenedores y Kubernetes. Con el descubrimiento automático, no necesita escribir plugins de verificación ni definiciones de hosts.
¿Necesito instalar plugins con Bleemeo?
No. El agente de Bleemeo (Glouton) detecta y monitorea más de 100 servicios automáticamente. Sin NRPE, sin scripts de plugins, sin objects.cfg.
¿Cómo funcionan las alertas en comparación con Nagios?
Bleemeo incluye umbrales de alerta preconfigurados para cada servicio descubierto, además de detección de anomalías basada en ML. Notificaciones por email, Slack, PagerDuty o webhooks — sin necesidad de escribir reglas manualmente.
¿Existe una ruta de migración desde Nagios?
Sí. Instale el agente Bleemeo junto a Nagios, verifique la cobertura y luego desactive Nagios cuando esté seguro. La mayoría de equipos migran en menos de una semana.
¿Bleemeo soporta contenedores y Kubernetes?
Sí. A diferencia de Nagios, que no tiene soporte nativo para contenedores, Bleemeo monitorea Docker y Kubernetes de forma nativa con descubrimiento automático de pods y servicios.
¿Bleemeo incluye gestión de logs?
Sí. Recopilación y búsqueda centralizada de logs incluida a 0,50€/GiB. Sin necesidad de un stack ELK separado junto a su monitoreo.
¿Existe un plan gratuito?
Sí. Monitoree hasta 3 servidores gratis, para siempre. Todas las funciones incluidas — sin división comunidad vs. empresa como Nagios Core vs. Nagios XI.
¿Bleemeo soporta SNMP y monitoreo de red?
Sí. Bleemeo monitorea dispositivos de red y soporta SNMP junto con el monitoreo de servidores y aplicaciones — todo en una plataforma.
¿Listo para dejar Nagios atrás?
Únase a cientos de equipos de ingeniería que han reemplazado su infraestructura Nagios obsoleta con la plataforma de monitoreo moderna y cloud-native de Bleemeo. Deje de dedicar horas a archivos de configuración, mantenimiento de plugins y gestión de agentes NRPE. Comience su prueba gratuita de 15 días hoy y experimente la diferencia que el descubrimiento automático, las alertas inteligentes y una plataforma unificada de métricas-logs-disponibilidad pueden hacer por sus operaciones.
Sin tarjeta de crédito · Acceso completo a funciones · Soporte de migración disponible