Una Alternativa Completa a Grafana
Grafana es excelente para visualización, pero no es una solución completa de monitorización. Aún necesitas Prometheus, Loki, Alertmanager y Mimir — cada uno con su propia carga operacional. Bleemeo reemplaza todo el stack LGTM con una sola plataforma gestionada.
15 días gratis · Sin tarjeta de crédito · Sin infraestructura que gestionar
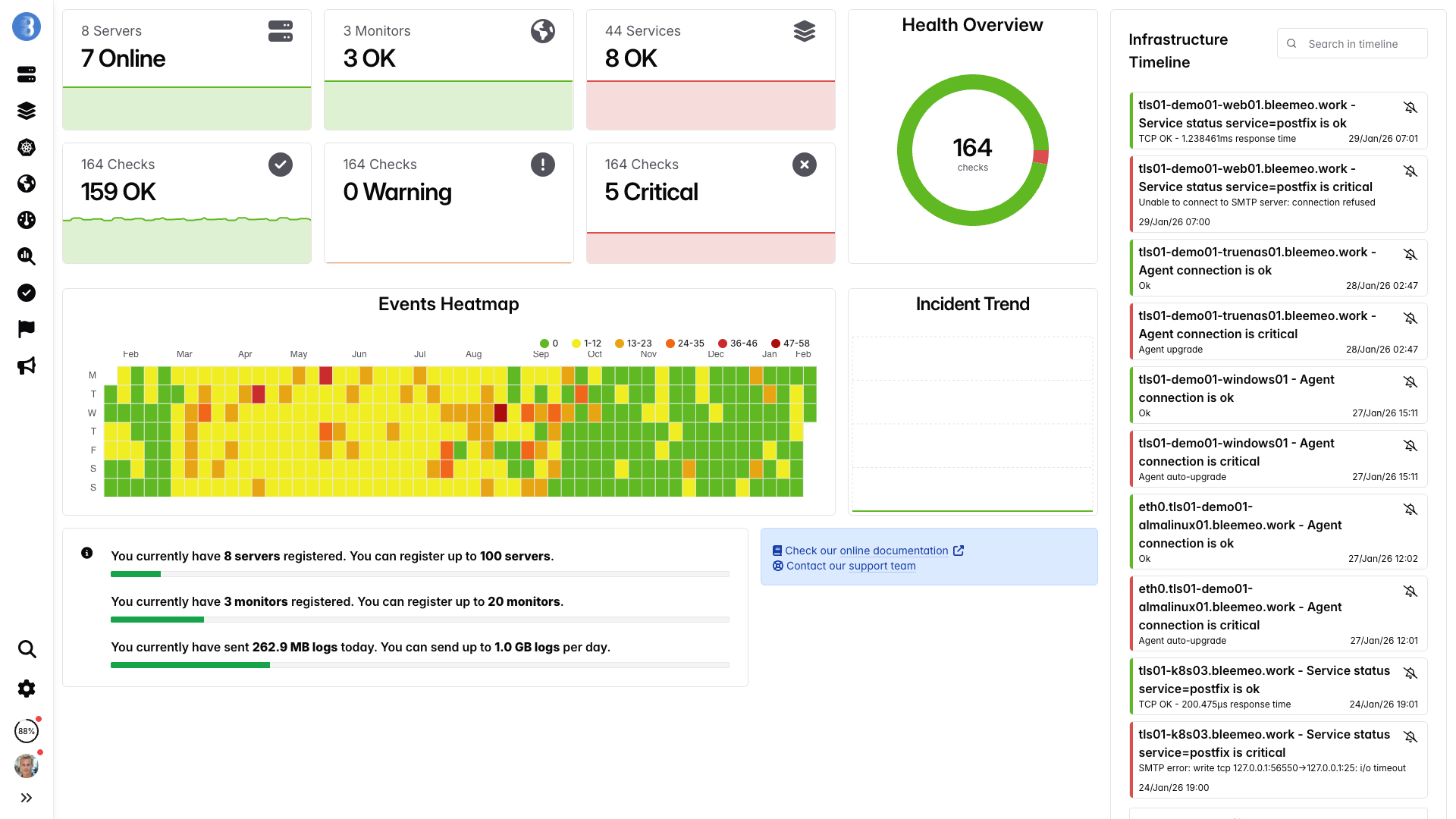
Dashboards en tiempo real, listos en minutos — sin configuración necesaria
El Desafío con el Stack de Grafana
Múltiples Herramientas que Gestionar
Grafana es puramente una capa de visualización y no puede recopilar una sola métrica por sí misma. Para construir un stack de monitorización funcional, necesitas desplegar Prometheus para el scraping de métricas, Loki y Promtail para la ingestión de logs, Alertmanager para el enrutamiento de notificaciones, y potencialmente Mimir o Thanos para almacenamiento a largo plazo. Cada uno de estos componentes tiene su propia sintaxis de configuración, ciclo de actualizaciones y modos de fallo, lo que significa que tu equipo pasa más tiempo manteniendo la plataforma de monitorización que usándola para mejorar la fiabilidad.
Sobrecarga de Infraestructura
Ejecutar el stack LGTM a escala es un trabajo a tiempo completo. Los servidores Prometheus requieren una planificación cuidadosa de capacidad para memoria y disco, y las métricas de alta cardinalidad pueden causar crashes de out-of-memory que tumban todo tu sistema de monitorización en el peor momento posible. Añadir almacenamiento a largo plazo con Thanos o Cortex introduce trabajos de compactación, gestión de almacenamiento de objetos y complejidad de federación de consultas que crece con cada nuevo clúster que incorporas.
Configuración Compleja
Configurar service discovery de Prometheus, intervalos de scrape, reglas de relabeling, recording rules y reglas de alertas requiere experiencia profunda en PromQL y configuración YAML. La gestión de alertas se divide entre las reglas de alertas de Prometheus y los árboles de enrutamiento de Alertmanager, lo que dificulta entender quién es notificado, cuándo y por qué. Una sola regla de relabel o silencio mal configurado puede hacer que alertas críticas se descarten silenciosamente, dejando a tu equipo ciego durante un incidente.
Sin Agente Integrado
Grafana depende completamente de colectores de terceros para la ingestión de datos. Debes desplegar node_exporter en cada servidor Linux, windows_exporter en máquinas Windows, blackbox_exporter para verificaciones de endpoints, y docenas de exporters específicos de aplicaciones para bases de datos, colas de mensajes y servidores web. Cada exporter debe instalarse, configurarse con los flags correctos, registrarse como servicio systemd y añadirse a los scrape targets de Prometheus. Gestionar esta flota de exporters a través de cientos de servidores se convierte en una carga operacional significativa que escala mal.
Stack Grafana vs Bleemeo
| Característica | Stack Grafana | Bleemeo |
|---|---|---|
| Recopilación de Métricas | Requiere desplegar servidor Prometheus más node_exporter en cada host | Agente ligero integrado con descubrimiento automático de servicios y cero configuración |
| Gestión de Logs | Requiere desplegar Loki para almacenamiento más agentes Promtail en cada servidor para el envío de logs | Agregación y búsqueda de logs integrada, recopilada por el mismo agente que recoge métricas |
| Alertas | Requiere Alertmanager separado con árboles de enrutamiento complejos y reglas de inhibición | Alertas integradas con enrutamiento inteligente, detección de anomalías y políticas de escalado |
| Infraestructura | Componentes auto-alojados que requieren servidores dedicados, almacenamiento y mantenimiento continuo | Plataforma SaaS completamente gestionada sin servidores que aprovisionar o mantener |
| Descubrimiento de Servicios | Configuración manual de service discovery basada en YAML para cada tipo de target | Detección automática de servicios en ejecución, contenedores y procesos sin configuración |
| Apps Móviles | Solo interfaz web, sin experiencia móvil nativa para monitorización en movimiento | Apps nativas iOS y Android con notificaciones push para alertas en tiempo real en el móvil |
| Monitorización de Uptime | Requiere desplegar y configurar blackbox_exporter con módulos de sondeo | Monitorización HTTP, TCP e ICMP integrada desde 7 ubicaciones globales con seguimiento de latencia |
| Escalabilidad | Federación compleja o despliegue de Thanos/Cortex requerido para escalado multi-clúster | Escalado horizontal automático, solo añade agentes y la plataforma se encarga del resto |
| Mantenimiento | Actualizaciones manuales, estrategias de backup, políticas de retención y parches de seguridad para cada componente | Cero mantenimiento requerido, actualizaciones automáticas y backups gestionados con uptime garantizado |
| Creación de Dashboards | Consultas PromQL manuales, horas de configuración de paneles y variables por dashboard | Dashboards pre-construidos para todos los servicios detectados, listos en segundos sin escribir consultas |
| Compatibilidad Prometheus | Prometheus nativo, pero requiere un despliegue completo de Prometheus auto-gestionado | Hace scrape de exporters Prometheus de forma nativa, sin necesidad de servidor Prometheus separado |
| Retención de Datos | 15 días por defecto, largo plazo requiere Thanos o Mimir con almacenamiento de objetos | Un año de retención incluido, sin infraestructura adicional ni configuración de almacenamiento |
| Curva de Aprendizaje | Pronunciada: PromQL, LogQL, enrutamiento Alertmanager, reglas de relabeling y configuración YAML | Interfaz web intuitiva, productivo en horas sin lenguaje de consulta requerido |
Coste Total de Propiedad
Stack Grafana
Bleemeo
*Con reserva de 1 año. Logs facturados por separado a 0,50€/GiB.
Por Qué Elegir Bleemeo
Plataforma Todo-en-Uno
Deja de hacer malabares con Prometheus, Loki, Alertmanager, Thanos y Grafana como componentes separados. Bleemeo ofrece recopilación de métricas, agregación de logs, monitorización de uptime, alertas inteligentes y dashboards en tiempo real en una sola plataforma integrada. Todo funciona junto desde el primer momento, eliminando la deriva de configuración y las incompatibilidades de versiones entre componentes.
Agente Inteligente
El agente Bleemeo descubre automáticamente servicios en ejecución, contenedores, bases de datos y servidores web en cada host. Recopila métricas del sistema, métricas específicas de aplicaciones y logs sin requerir que instales o configures exporters separados. Un solo agente reemplaza node_exporter, process-exporter y docenas de exporters específicos de aplicaciones, reduciendo dramáticamente tu superficie de despliegue.
Cero Infraestructura
Sin servidores Prometheus que escalar, sin clústeres Loki que gestionar, sin compactadores Thanos que ajustar, y sin componentes que parchear o actualizar. Bleemeo se encarga de toda la infraestructura backend, incluyendo alta disponibilidad, replicación de datos y almacenamiento a largo plazo. Tu equipo recupera las horas de ingeniería anteriormente dedicadas a mantener el stack de monitorización en funcionamiento.
Compatible con Prometheus
¿Ya invertiste en exporters Prometheus y métricas personalizadas? Glouton, el agente de Bleemeo, soporta nativamente el formato de exposición de Prometheus y puede hacer scrape de tus endpoints de exporters existentes directamente. No se necesita servidor Prometheus separado, haciendo la migración gradual y sin riesgo. Tu conocimiento existente de PromQL y métricas personalizadas se preservan completamente.
Alertas Inteligentes
Bleemeo incluye detección de anomalías integrada que aprende los patrones de comportamiento normal de tu infraestructura y te alerta cuando algo se desvía. El enrutamiento inteligente de alertas entrega notificaciones por email, Slack, PagerDuty o notificaciones push móviles sin requerir árboles de enrutamiento complejos de Alertmanager. Las alertas basadas en umbrales vienen pre-configuradas para servicios comunes, así que obtienes alertas significativas desde el primer día.
Dashboards Hermosos
Bleemeo proporciona dashboards modernos y responsivos que se generan automáticamente para cada servicio descubierto. A diferencia de Grafana donde pasas horas creando consultas PromQL y configurando paneles, los dashboards de Bleemeo están listos inmediatamente con valores predeterminados sensatos. Aún puedes crear vistas personalizadas y profundizar en métricas específicas, pero la experiencia lista para usar cubre la mayoría de las necesidades de monitorización sin configuración manual.
Transición Fácil desde el Stack Grafana
Migrar desde el stack Grafana no tiene que ser un cambio radical. Puedes ejecutar Bleemeo junto a tu configuración existente de Prometheus y Grafana, validar la cobertura y descomisionar gradualmente los componentes que ya no necesitas. El proceso completo suele tomar menos de una semana para la mayoría de los equipos.
Desplegar Agentes Bleemeo
Instala el agente Bleemeo en cada servidor con un solo comando. El agente se ejecuta junto a tus exporters Prometheus existentes sin conflictos y comienza inmediatamente a recopilar métricas del sistema, descubrir servicios y enviar datos a la plataforma Bleemeo:
wget -qO- 'https://get.bleemeo.com?accountId=...' | sudo bashVerificar Cobertura
Accede a la consola de Bleemeo y verifica que todos tus servidores, contenedores y servicios aparecen automáticamente. El agente detecta bases de datos como MySQL y PostgreSQL, servidores web como Nginx y Apache, colas de mensajes como RabbitMQ y Kafka, y muchos más servicios sin configuración manual. Compara los servicios descubiertos con tus scrape targets existentes de Prometheus para asegurar cobertura completa.
Conectar Exporters Existentes
Si tienes exporters Prometheus personalizados o métricas instrumentadas de aplicaciones, configura Glouton para hacer scrape de sus endpoints directamente. Glouton soporta el formato de exposición estándar de Prometheus de forma nativa, así que tus métricas personalizadas existentes se preservan sin modificación.
Configurar Alertas
Configura tus canales de notificación como email, Slack, PagerDuty o integraciones webhook. Bleemeo viene con umbrales de alerta predeterminados sensatos para CPU, memoria, disco y disponibilidad de servicios. Revisa estos valores predeterminados, ajusta los umbrales para que coincidan con tus SLOs y añade reglas de alerta personalizadas para métricas específicas de aplicaciones. Muchos equipos descubren que la detección de anomalías integrada de Bleemeo captura problemas que sus reglas manuales de Alertmanager pasaban por alto.
Validar en Paralelo
Ejecuta Bleemeo junto a tu stack Grafana existente durante un período de validación. Compara alertas, dashboards y cobertura de métricas entre ambos sistemas. Esta operación en paralelo asegura que tengas total confianza en Bleemeo antes de hacer cambios en tu configuración existente. La mayoría de los equipos ejecutan ambos sistemas durante una a dos semanas.
Descomisionar y Simplificar
Una vez validado, descomisiona gradualmente los componentes del stack Grafana que ya no necesitas. Elimina servidores Prometheus, clústeres Loki, instancias de Alertmanager y la flota de exporters de tu infraestructura. Esto libera recursos de cómputo, reduce tu superficie de ataque y elimina la carga de guardia de mantener la plataforma de monitorización en sí. Tu equipo ahora puede concentrarse completamente en construir y operar tu producto real.
Lo que dicen nuestros clientes
Ingenieros y CTOs confían en Bleemeo para monitorear su infraestructura
Durante una breve pausa para almorzar, instalamos Bleemeo, creamos una métrica personalizada, probamos las alertas y estábamos listos para producción. La velocidad de despliegue es notable.

El soporte de Bleemeo es simplemente legendario: rápido, competente y siempre disponible cuando lo necesitamos.
Bleemeo fue increíblemente rápido de desplegar. En aproximadamente una hora lo implementamos en más de 100 servidores y obtuvimos visibilidad completa de nuestra infraestructura de inmediato.

Configuramos el monitoreo de todos nuestros servidores en solo unas pocas horas. El dashboard es claro, potente y realmente agradable de usar.

Desplegamos Bleemeo en toda nuestra infraestructura de servidores en solo unas pocas horas. El monitoreo de disponibilidad ahora nos alerta instantáneamente cuando un servicio tiene un problema.

Nuestra pila de Prometheus + Grafana se había convertido en un proyecto de mantenimiento. Con Bleemeo desplegamos el agente en minutos y finalmente nos enfocamos en usar el monitoreo en lugar de mantenerlo.
Después de instalar el agente, Bleemeo descubrió automáticamente nuestras bases de datos, contenedores y servicios. En una hora teníamos visibilidad completa de la infraestructura, sin dashboards ni exporters que construir.
Bleemeo reemplazó varias herramientas de monitoreo con una sola plataforma. Métricas, alertas y logs están ahora en un solo lugar, ahorrando a nuestro equipo un tiempo significativo.
Bleemeo nos dio una visión inmediata de nuestra infraestructura sin la complejidad habitual. En un par de horas teníamos métricas, alertas y dashboards funcionando sin problemas.
Configurar Bleemeo fue sorprendentemente simple. El despliegue del agente tomó minutos y el descubrimiento automático nos ahorró días de configuración.
Gracias a Bleemeo, nuestro equipo ahora detecta problemas antes de que los usuarios los noten. Las alertas son fiables y la interfaz hace que la resolución de problemas sea mucho más rápida.
Migrar a Bleemeo simplificó drásticamente nuestra pila de monitoreo. En lugar de gestionar múltiples herramientas, todo lo que necesitamos está disponible en una sola plataforma.
Centralizar nuestros logs en Bleemeo simplificó drásticamente la resolución de problemas. En lugar de saltar entre herramientas, ahora podemos correlacionar métricas y logs instantáneamente para entender qué está pasando.
Bleemeo hizo que el monitoreo de Kubernetes fuera sorprendentemente fácil. En minutos teníamos visibilidad de nuestros clusters, pods y cargas de trabajo sin tener que construir dashboards complejos nosotros mismos.
Vea Bleemeo en acción
Descubre cómo los equipos pasan de la instalación a una monitorización completa en menos de 5 minutos
Preguntas frecuentes
¿Puede Bleemeo reemplazar el stack completo de Grafana?
Sí. Bleemeo reemplaza Grafana, Prometheus, Loki, Alertmanager y Mimir con una sola plataforma gestionada. Métricas, logs, dashboards y alertas están incluidos.
¿Necesito crear dashboards desde cero?
No. Bleemeo pre-construye dashboards para cada servicio auto-descubierto. Los dashboards personalizados también están disponibles si necesitas vistas específicas.
¿Bleemeo soporta métricas de Prometheus?
Sí. Glouton, el agente de Bleemeo, hace scrape de exporters Prometheus de forma nativa, así que los exporters existentes y la instrumentación personalizada funcionan directamente.
¿Qué pasa con Grafana Cloud?
El precio de Grafana Cloud escala con el uso (métricas, logs, trazas). El precio por agente de Bleemeo es predecible independientemente del volumen de datos — sin cargos por serie ni por GB.
¿Puedo usar Bleemeo junto a mi configuración actual de Grafana?
Sí. Puedes ejecutar agentes Bleemeo junto a tu stack actual de Grafana durante la migración. Glouton opera de forma independiente y no interferirá con Prometheus u otros colectores.
¿Bleemeo soporta dashboards personalizados?
Sí. Aunque Bleemeo pre-construye dashboards para cada servicio descubierto, también puedes crear dashboards personalizados con widgets de arrastrar y soltar para las vistas específicas que tu equipo necesita.
¿Hay un nivel gratuito?
Sí. Monitoriza hasta 3 servidores gratis sin límite de tiempo. Todas las funciones incluidas — dashboards, alertas, logs, descubrimiento de servicios.
¿Cómo se compara la gestión de logs con Loki?
Bleemeo incluye recopilación y búsqueda centralizada de logs a 0,50€/GiB ingerido. Sin despliegue de Loki separado, sin agentes Promtail, sin backend de almacenamiento que gestionar.
¿Listo para Dejar Atrás la Complejidad del Stack LGTM?
Únete a cientos de equipos de ingeniería que pasaron de gestionar Prometheus, Loki, Alertmanager y Grafana por separado a una sola plataforma que simplemente funciona. Comienza tu prueba gratuita hoy y experimenta la monitorización completa de infraestructura sin la sobrecarga operacional. Despliega tu primer agente en menos de cinco minutos y ve las métricas fluir inmediatamente.
Sin tarjeta de crédito · 15 días de prueba gratuita · Funciona junto a tu stack Grafana existente · Acceso completo a funciones