Eine moderne Alternative zu Nagios
Nagios hat das Monitoring in den 2000ern revolutioniert, aber seine Plugin-basierte Architektur und
manuelle Konfigurationsdateien haben nicht mit moderner Infrastruktur Schritt gehalten. Bleemeo bietet
automatische Erkennung, integrierte Dashboards und ML-gestutzte Alarmierung -- keine Plugins, kein NRPE, keine objects.cfg.
15 Tage kostenlose Testversion • Keine Kreditkarte erforderlich • Migration in Minuten
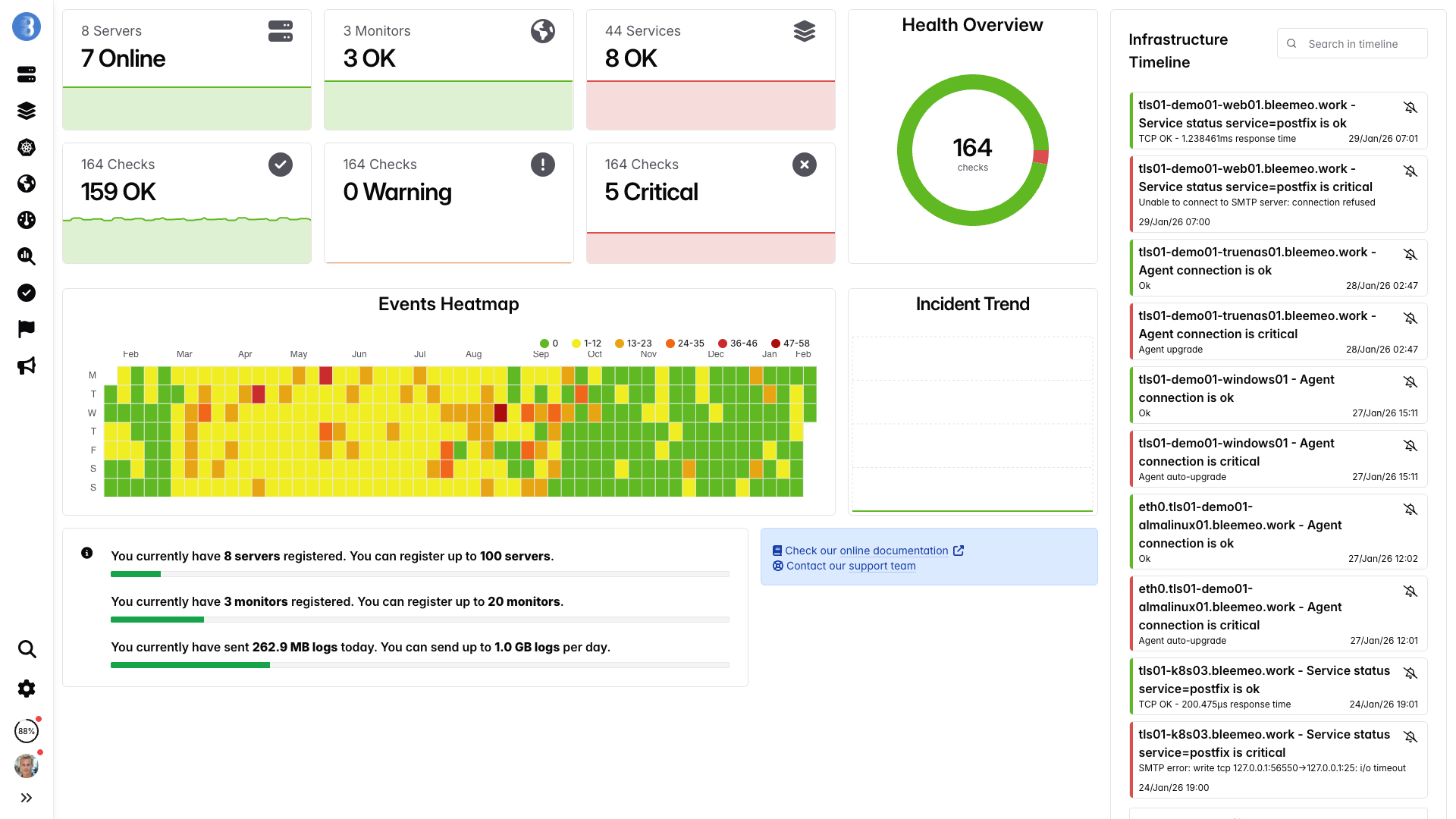
Echtzeit-Dashboards, in Minuten einsatzbereit -- keine Konfiguration noetig
Warum Teams von Nagios wechseln
Zeitaufwaendige Einrichtung
Die Konfiguration von Nagios erfordert die Bearbeitung komplexer Textdateien wie hosts.cfg, services.cfg und commands.cfg, gefolgt vom Neuladen des Daemons bei jeder einzelnen Aenderung. Jeder neue Host oder Dienst muss manuell mit Check-Befehlen, Intervallen, Benachrichtigungszeitraeumen, Kontaktgruppen und Schwellenwerten definiert werden -- oft ueber Dutzende von Zeilen pro Objekt. Ein einziger Syntaxfehler in diesen Flat-File-Definitionen kann den Neustart des gesamten Nagios-Daemons verhindern und Ihr Monitoring blind lassen, bis das Problem gefunden und behoben ist. Was mit Nagios Tage oder sogar Wochen dauert, dauert mit Bleemeos automatischer Erkennung nur Minuten.
Wartungslast
Den Betrieb von Nagios bedeutet, dass Sie fuer den Monitoring-Server selbst verantwortlich sind: OS-Patches, Apache- oder PHP-Upgrades, Plugin-Kompatibilitaet, Speicherplatz fuer Leistungsdaten und NRPE-Agent-Updates auf jedem Server Ihrer Flotte. Jeder NRPE-Agent muss individuell mit erlaubten Check-Befehlen und Firewall-Regeln konfiguriert werden, was eine wachsende Wartungsflaeche schafft. Die Nagios-Community hat sich in konkurrierende Forks wie Icinga 2, Naemon und Shinken aufgespalten, was es schwieriger macht, aktuelle Plugins und zuverlaessige Dokumentation zu finden. Bleemeo ist eine vollstaendig verwaltete SaaS-Plattform -- keine Server zu patchen, keine Agents manuell zu konfigurieren und keine Plugin-Repositories zu pruefen.
Nicht cloud-native
Nagios wurde fuer statische, lokale Rechenzentren entwickelt, in denen sich Hosts selten aendern und IP-Adressen fest sind. Es bietet keine native Unterstutzung fuer Container, Kubernetes-Pods, Auto-Scaling-Gruppen oder serverlose Funktionen. Jedes Mal, wenn eine Cloud-Instanz hoch- oder herunterskaliert, muss die entsprechende Host-Definition manuell hinzugefuegt oder entfernt werden -- was zu veralteten Alarmen, Konfigurationsdrift und Phantom-Benachrichtigungen fuehrt. Bleemeo wurde von Anfang an fuer ephemere, cloud-native Umgebungen entwickelt.
Veraltete Oberflaeche
Die Standard-Web-UI von Nagios -- bekannt als CGI-Interface -- hat sich seit ueber einem Jahrzehnt kaum veraendert. Sie bietet nur einfache Host- und Service-Statustabellen ohne Echtzeit-Dashboards, interaktive Zeitreihen-Diagramme oder mobile Responsivitaet. Die meisten Teams installieren letztendlich Drittanbieter-Frontends wie Thruk, Adagios oder koppeln Grafana mit PNP4Nagios an, nur um nutzbare Visualisierungen zu erhalten. Bleemeo bietet moderne, anpassbare Dashboards mit Echtzeit-Metriken und nativen iOS- und Android-Apps sofort einsatzbereit.
Nagios vs Bleemeo
| Funktion | Nagios | Bleemeo |
|---|---|---|
| Einrichtungszeit | Tage bis Wochen manueller Host- und Dienst-Definitionen | Minuten mit einem einzigen Agent-Installationsbefehl |
| Konfiguration | Manuelle Bearbeitung von objects.cfg, commands.cfg und contacts.cfg | Automatische Erkennung von Diensten, Containern und Infrastruktur |
| Cloud-Native | Keine Container- oder Kubernetes-Unterstutzung; nur statisches Host-Modell | Native Kubernetes-, Docker- und Cloud-Provider-Integration |
| Mobile Apps | Keine offizielle mobile Anwendung verfuegbar | Native iOS- und Android-Apps mit Push-Benachrichtigungen |
| Alarmierung | Einfache E-Mail- und Pager-Benachrichtigungen ueber benutzerdefinierte Skripte | Intelligentes Routing mit SMS, Slack, Teams, PagerDuty und Webhooks |
| Wartung | Selbst gehosteter Server mit OS-Patches, Plugin-Updates und NRPE-Verwaltung | Vollstaendig verwaltete SaaS-Plattform mit null Server-Wartung |
| Dashboards | Veraltete integrierte UI; erfordert Thruk oder Grafana fuer nutzbare Dashboards | Moderne, anpassbare Dashboards |
| Log-Management | Nicht enthalten; erfordert separaten ELK-Stack oder Graylog | Integrierte Log-Sammlung, -Suche und -Analyse in einer Plattform |
| Anomalieerkennung | Nur statische Schwellenwerte; kein maschinelles Lernen oder Trendanalyse | ML-gestuetzte Anomalieerkennung mit automatischem Baseline-Lernen |
| Prometheus & OpenTelemetry | Keine native Unterstutzung; inkompatible check-basierte Architektur | Natives Prometheus-Exporter-Scraping und OpenTelemetry-Collector-Unterstutzung |
| Skalierbarkeit | Einzelserver-Architektur; verteilte Setups erfordern komplexe Mod Gearman oder DNX Add-ons | Cloud-native SaaS, skaliert automatisch von 10 bis 10.000+ Agents |
| API | Eingeschraenkte externe Befehlsschnittstelle; keine REST-API in Core | Vollstaendige REST-API fuer Automatisierung, Integration und Workflows |
| Verfuegbarkeits-Monitoring | Einfaches check_http-Plugin; kein Multi-Standort-Pruefung oder SLA-Reporting | Globale Verfuegbarkeitspruefungen von mehreren Standorten mit SLA-Dashboards |
| Preisgestaltung | Core ist kostenlos, aber Nagios XI ab $2.495; plus Infrastruktur, Sysadmin-Zeit und Drittanbieter-Tools | Einfache Pro-Agent-Preisgestaltung ab 10,99 EUR/Monat, alle Funktionen inklusive, keine versteckten Kosten |
Gesamtbetriebskosten: Nagios vs Bleemeo
Nagios Core mag Open Source sein, aber die wahren Kosten liegen in der Infrastruktur, der Engineering-Zeit und den Drittanbieter-Tools, die fuer einen produktionsreifen Monitoring-Stack erforderlich sind. Hier ist ein realistischer Vergleich fuer eine 100-Server-Umgebung ueber ein Jahr.
Nagios Stack -- Geschaetzte jaehrliche Kosten
- Nagios XI Standard-Lizenz (100 Knoten): $4.495
- Dedizierter Monitoring-Server (Hosting + Wartung): $3.600/Jahr
- Sysadmin-Zeit fuer Nagios-Wartung (~8 Std./Monat): $9.600/Jahr
- NRPE-Agent-Bereitstellung und Plugin-Wartung: $2.400/Jahr
- ELK-Stack oder Graylog fuer Log-Management: $6.000/Jahr
- Grafana + PNP4Nagios fuer Dashboards: $1.200/Jahr
- Drittanbieter-Verfuegbarkeits-Monitoring-Dienst: $1.800/Jahr
Gesamt: ~$29.095/Jahr
Bleemeo -- Jaehrliche Kosten
- 100 Agents zu je 10,99 EUR/Monat: 13.188 EUR/Jahr
- Mit Jahresreservierung (10% Rabatt): 11.869 EUR/Jahr
- Metriken, Logs, Verfuegbarkeit, Dashboards, Mobile Apps: inklusive
- Automatische Erkennung und intelligente Alarmierung: inklusive
- Prometheus- und OpenTelemetry-Unterstutzung: inklusive
- Kein Server zu warten, keine Plugins zu verwalten: $0
- Sysadmin-Zeit fuer Monitoring-Wartung: nahezu null
Gesamt: ~11.869 EUR/Jahr
Was Bleemeo besser macht
Automatische Erkennung
Installieren Sie unseren leichtgewichtigen Agent und er erkennt automatisch Dienste wie MySQL, PostgreSQL, Redis, Nginx, Apache, Docker-Container und Kubernetes-Pods. Es muessen keine Konfigurationsdateien geschrieben, keine Check-Befehle definiert und keine Daemon-Neuladevorgaenge ausgeloest werden. Neue Dienste werden innerhalb von Sekunden nach ihrem Erscheinen auf dem Host erkannt und ueberwacht, wodurch die manuellen Objekt-Definitionen entfallen, die bei Nagios so viel Zeit verbrauchen.
Cloud-Native Architektur
Von Grund auf fuer moderne, dynamische Infrastruktur gebaut. Bleemeo unterstuetzt nativ Kubernetes-Cluster, Docker- und containerd-Laufzeiten, AWS, Azure und GCP. Ephemere Workloads, die hoch- und herunterskalieren, werden automatisch verfolgt -- keine veralteten Host-Definitionen, keine Phantom-Alarme und keine manuellen Bereinigungsskripte erforderlich.
Intelligente Alarmierung
Auf maschinellem Lernen basierende Anomalieerkennung lernt automatisch normale Verhaltensbaselines fuer jede Metrik, sodass Sie bei echten Problemen alarmiert werden, anstatt bei statischen Schwellenwertueberschreitungen. Intelligente Alarm-Gruppierung korreliert zusammenhaengende Vorfaelle, um Rauschen zu reduzieren, und flexibles Benachrichtigungs-Routing sendet Alarme ueber Slack, Microsoft Teams, PagerDuty, SMS oder Webhooks an das richtige Team.
Ansprechende Dashboards
Moderne, responsive Dashboards mit Echtzeit-Metriken-Streaming bieten sofortige Sichtbarkeit Ihrer gesamten Infrastruktur. Erstellen Sie benutzerdefinierte Ansichten in Minuten mit Drag-and-Drop-Widgets, interaktiven Zeitreihen-Diagrammen und Topologie-Karten. Anders als bei Nagios muessen Sie kein Thruk, Grafana oder PNP4Nagios installieren, um nutzbare Visualisierungen zu erhalten.
Mobile First
Native iOS- und Android-Anwendungen ermoeglichen es Ihnen, Ihre gesamte Infrastruktur zu ueberwachen und von ueberall auf Vorfaelle zu reagieren. Erhalten Sie Push-Benachrichtigungen in dem Moment, in dem ein Problem erkannt wird, bestaetigen Sie Alarme, sehen Sie Dashboards ein und analysieren Sie Metrik-Details -- alles von Ihrem Telefon oder Tablet, ohne VPN fuer den Zugriff auf einen lokalen Nagios-Server.
Vereinheitlichte Plattform
Metriken, Logs, Verfuegbarkeits-Monitoring und Anomalieerkennung sind in einer einzigen Plattform vereint. Mit Nagios muessen Teams typischerweise separate Tools fuer Log-Management (ELK oder Graylog), Dashboards (Grafana) und Verfuegbarkeitspruefungen (externe Dienste) zusammenfuegen, was einen fragmentierten Stack schafft, der teuer im Betrieb und schwer zu korrelieren ist. Bleemeo bringt alles zusammen.
Die Migration von Nagios ist einfach
Anmelden und Agent installieren
Erstellen Sie Ihr kostenloses Bleemeo-Konto und installieren Sie den leichtgewichtigen Agent auf jedem Server mit einem einzigen Befehl. Der Agent unterstuetzt Debian, Ubuntu, RHEL, CentOS, Alpine und die meisten gaengigen Linux-Distributionen. Die Installation dauert weniger als eine Minute pro Host:
wget -qO- 'https://get.bleemeo.com?accountId=...'Automatische Erkennung ueberpruefen
Innerhalb von Sekunden nach der Installation erkennt der Agent automatisch laufende Dienste wie MySQL, PostgreSQL, Redis, Nginx, Apache, Elasticsearch, Docker-Container und Kubernetes-Pods. Melden Sie sich im Bleemeo-Dashboard an, um zu ueberpruefen, ob alle Ihre kritischen Dienste erkannt werden und Metriken fliessen.
Alarme und Benachrichtigungen konfigurieren
Richten Sie Benachrichtigungskanaele -- Slack, Microsoft Teams, PagerDuty, SMS, E-Mail oder Webhooks -- ueber die intuitive Web-Oberflaeche ein. Bleemeo kommt mit sinnvollen Standard-Schwellenwerten fuer alle erkannten Dienste, sodass Sie sofort aussagekraeftige Alarme erhalten.
Dashboards erstellen
Erstellen Sie benutzerdefinierte Dashboards, um die Ansichten aus Nagios, Thruk oder Grafana nachzubilden und zu verbessern. Bleemeos Dashboard-Builder ermoeglicht Drag-and-Drop-Widgets fuer CPU, Speicher, Festplatte, Netzwerk und anwendungsspezifische Metriken.
Parallel betreiben und validieren
Lassen Sie Nagios ein bis zwei Wochen lang neben Bleemeo laufen, um Abdeckung, Alarm-Genauigkeit und Team-Workflows zu validieren. Vergleichen Sie die von beiden Systemen generierten Alarme, um Vertrauen aufzubauen, dass Bleemeo alles erkennt, was Nagios erkennt -- und mehr.
Nagios abschalten
Sobald Ihr Team von Bleemeos Abdeckung und Alarmierung ueberzeugt ist, machen Sie es zu Ihrer primaeren Monitoring-Plattform und dekommissionieren Sie Nagios. Entfernen Sie den Nagios-Server, deinstallieren Sie NRPE-Agents und geben Sie die zugehoerige Infrastruktur frei.
Was unsere Kunden sagen
Ingenieure und CTOs vertrauen auf Bleemeo für ihr Infrastruktur-Monitoring
Während einer kurzen Mittagspause haben wir Bleemeo installiert, eine benutzerdefinierte Metrik erstellt, Alerts getestet und waren produktionsbereit. Die Geschwindigkeit der Bereitstellung ist bemerkenswert.

Der Bleemeo-Support ist schlicht legendär — schnell, kompetent und immer da, wenn wir ihn brauchen.
Bleemeo war unglaublich schnell einzurichten. In etwa einer Stunde haben wir es auf über 100 Servern ausgerollt und sofort volle Sicht auf unsere Infrastruktur erhalten.

Wir haben das Monitoring für alle unsere Server in nur wenigen Stunden eingerichtet. Das Dashboard ist übersichtlich, leistungsstark und macht wirklich Freude in der Nutzung.

Wir haben Bleemeo in nur wenigen Stunden auf unserer gesamten Server-Infrastruktur ausgerollt. Das Uptime-Monitoring benachrichtigt uns jetzt sofort, wenn ein Dienst ein Problem hat.

Unser Prometheus + Grafana-Stack war zu einem Wartungsprojekt geworden. Mit Bleemeo haben wir den Agenten in Minuten ausgerollt und uns endlich auf die Nutzung des Monitorings statt auf dessen Wartung konzentriert.
Nach der Installation des Agenten hat Bleemeo automatisch unsere Datenbanken, Container und Services erkannt. Innerhalb einer Stunde hatten wir volle Infrastruktur-Sichtbarkeit — ohne Dashboards oder Exporter bauen zu müssen.
Bleemeo hat mehrere Monitoring-Tools durch eine einzige Plattform ersetzt. Metriken, Alerts und Logs sind jetzt an einem Ort, was unserem Team erheblich Zeit spart.
Bleemeo gab uns sofortigen Einblick in unsere Infrastruktur ohne die übliche Komplexität. Innerhalb weniger Stunden liefen Metriken, Alerts und Dashboards reibungslos.
Die Einrichtung von Bleemeo war erfrischend einfach. Das Agent-Deployment dauerte Minuten und die automatische Erkennung ersparte uns Tage an Konfiguration.
Dank Bleemeo erkennt unser Team Probleme jetzt, bevor unsere Nutzer sie bemerken. Die Alerting-Funktion ist zuverlässig und die Oberfläche macht die Fehlersuche deutlich schneller.
Der Wechsel zu Bleemeo hat unseren Monitoring-Stack dramatisch vereinfacht. Statt mehrere Tools zu verwalten, ist alles, was wir brauchen, auf einer einzigen Plattform verfügbar.
Die Zentralisierung unserer Logs in Bleemeo hat die Fehlersuche drastisch vereinfacht. Statt zwischen Tools zu wechseln, können wir jetzt Metriken und Logs sofort korrelieren, um zu verstehen, was passiert.
Bleemeo hat das Kubernetes-Monitoring überraschend einfach gemacht. Innerhalb von Minuten hatten wir Einblick in unsere Cluster, Pods und Workloads, ohne komplexe Dashboards selbst bauen zu müssen.
Bleemeo in Aktion sehen
Sehen Sie, wie Teams in unter 5 Minuten von der Installation zum vollstaendigen Monitoring gelangen
Haeufig gestellte Fragen
Kann Bleemeo Nagios fuer das Server-Monitoring ersetzen?
Ja. Bleemeo ueberwacht alles, was Nagios kann -- Server, Dienste, Netzwerk -- plus Container und Kubernetes. Dank automatischer Erkennung muessen Sie keine Check-Plugins oder Host-Definitionen schreiben.
Muss ich mit Bleemeo Plugins installieren?
Nein. Bleemeos Agent (Glouton) erkennt und ueberwacht automatisch ueber 100 Dienste. Kein NRPE, keine Plugin-Skripte, keine objects.cfg.
Wie funktioniert die Alarmierung im Vergleich zu Nagios?
Bleemeo enthaelt vorkonfigurierte Alarmschwellenwerte fuer jeden erkannten Dienst, plus ML-basierte Anomalieerkennung. Benachrichtigungen per E-Mail, Slack, PagerDuty oder Webhooks -- ohne manuelle Regelerstellung.
Gibt es einen Migrationspfad von Nagios?
Ja. Installieren Sie den Bleemeo-Agent neben Nagios, ueberpruefen Sie die Abdeckung und dekommissionieren Sie Nagios, sobald Sie sicher sind. Die meisten Teams migrieren in weniger als einer Woche.
Unterstuetzt Bleemeo Container und Kubernetes?
Ja. Im Gegensatz zu Nagios, das keine native Container-Unterstutzung bietet, ueberwacht Bleemeo Docker und Kubernetes sofort einsatzbereit mit automatischer Pod- und Dienst-Erkennung.
Beinhaltet Bleemeo Log-Management?
Ja. Zentralisierte Log-Sammlung und -Suche fuer 0,50 EUR/GiB inklusive. Kein separater ELK-Stack neben Ihrem Monitoring noetig.
Gibt es eine kostenlose Stufe?
Ja. Ueberwachen Sie bis zu 3 Server kostenlos, fuer immer. Alle Funktionen inklusive -- keine Community- vs. Enterprise-Aufteilung wie bei Nagios Core vs. Nagios XI.
Unterstuetzt Bleemeo SNMP und Netzwerk-Monitoring?
Ja. Bleemeo ueberwacht Netzwerkgeraete und unterstuetzt SNMP neben Server- und Anwendungs-Monitoring -- alles in einer Plattform.
Bereit, Nagios hinter sich zu lassen?
Schliessen Sie sich Hunderten von Engineering-Teams an, die ihre veraltete Nagios-Infrastruktur durch Bleemeos moderne, cloud-native Monitoring-Plattform ersetzt haben. Hoeren Sie auf, Stunden mit Konfigurationsdateien, Plugin-Wartung und NRPE-Agent-Verwaltung zu verbringen. Starten Sie noch heute Ihre kostenlose 15-Tage-Testversion.
Keine Kreditkarte erforderlich • Voller Funktionsumfang • Migrations-Support verfuegbar