Eine Komplette Alternative zu Grafana
Grafana ist hervorragend für die Visualisierung, aber keine komplette Monitoring-Lösung. Sie benötigen immer noch Prometheus, Loki, Alertmanager und Mimir — jedes mit eigenem operativen Aufwand. Bleemeo ersetzt den gesamten LGTM-Stack durch eine einzige verwaltete Plattform.
15 Tage kostenlos testen · Keine Kreditkarte erforderlich · Keine Infrastruktur zu verwalten
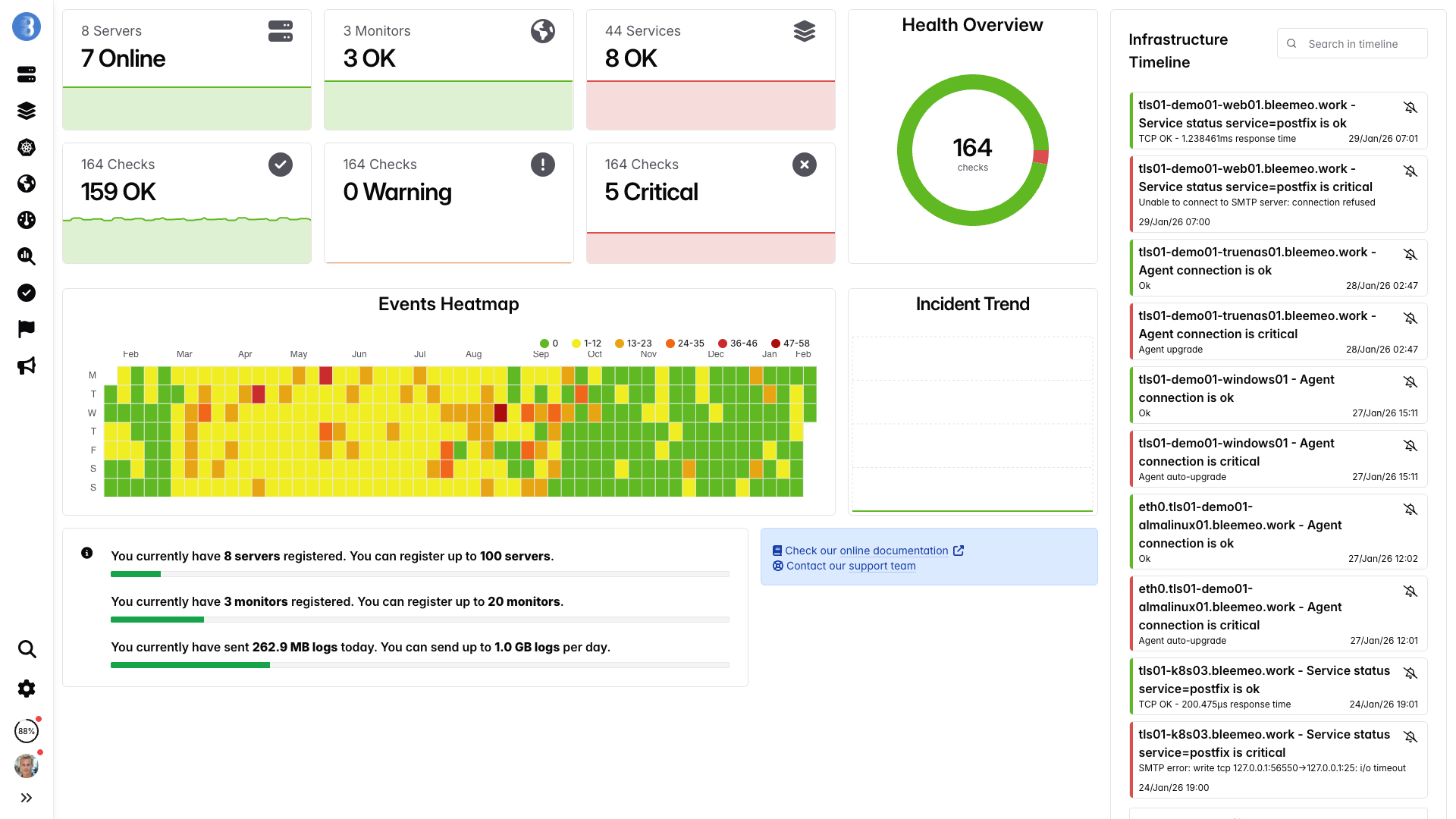
Echtzeit-Dashboards, in Minuten bereit — keine Konfiguration erforderlich
Die Herausforderung mit dem Grafana-Stack
Mehrere Tools zu verwalten
Grafana ist rein eine Visualisierungsschicht und kann keine einzige Metrik selbst erfassen. Um einen funktionierenden Monitoring-Stack aufzubauen, müssen Sie Prometheus für Metrik-Scraping, Loki und Promtail für Log-Aufnahme, Alertmanager für Benachrichtigungs-Routing und eventuell Mimir oder Thanos für Langzeitspeicherung bereitstellen. Jede dieser Komponenten hat eigene Konfigurationssyntax, Upgrade-Zyklen und Fehlermodi, sodass Ihr Team mehr Zeit mit der Wartung der Monitoring-Plattform verbringt als mit deren Nutzung.
Infrastruktur-Overhead
Den LGTM-Stack im großen Maßstab zu betreiben ist ein Vollzeitjob. Prometheus-Server erfordern sorgfältige Kapazitätsplanung für Speicher und Festplatte, und Metriken mit hoher Kardinalität können Out-of-Memory-Abstürze verursachen, die Ihr gesamtes Monitoring-System zum denkbar schlechtesten Zeitpunkt lahmlegen. Langzeitspeicherung mit Thanos oder Cortex bringt zusätzliche Kompaktierungsjobs, Object-Storage-Verwaltung und Abfrage-Föderations-Komplexität mit sich.
Komplexe Einrichtung
Die Konfiguration von Prometheus Service Discovery, Scrape-Intervallen, Relabeling-Regeln, Recording-Regeln und Alerting-Regeln erfordert tiefes Fachwissen in PromQL und YAML-Konfiguration. Das Alert-Management ist zwischen Prometheus-Alerting-Regeln und Alertmanager-Routing-Bäumen aufgeteilt, was es schwierig macht zu verstehen, wer wann und warum benachrichtigt wird. Eine einzige falsch konfigurierte Relabel-Regel kann dazu führen, dass kritische Alerts stillschweigend verworfen werden.
Kein integrierter Agent
Grafana verlässt sich vollständig auf Drittanbieter-Collectors für die Datenaufnahme. Sie müssen node_exporter auf jedem Linux-Server, windows_exporter auf Windows-Maschinen, blackbox_exporter für Endpoint-Checks und Dutzende anwendungsspezifischer Exporter für Datenbanken, Message-Queues und Webserver bereitstellen. Jeder Exporter muss installiert, konfiguriert, als systemd-Service registriert und zu Prometheus-Scrape-Targets hinzugefügt werden. Die Verwaltung dieser Exporter-Flotte über Hunderte von Servern wird zu einer erheblichen operativen Belastung.
Grafana Stack vs Bleemeo
| Funktion | Grafana Stack | Bleemeo |
|---|---|---|
| Metrikerfassung | Erfordert Bereitstellung von Prometheus-Server plus node_exporter auf jedem Host | Integrierter leichtgewichtiger Agent mit automatischer Service-Erkennung und Null-Konfiguration |
| Log-Management | Erfordert Bereitstellung von Loki für Speicherung plus Promtail-Agenten auf jedem Server für Log-Versand | Integrierte Log-Aggregation und -Suche, erfasst vom selben Agenten, der Metriken sammelt |
| Alerting | Erfordert separaten Alertmanager mit komplexen Routing-Bäumen und Inhibitionsregeln | Integriertes Alerting mit intelligentem Routing, Anomalie-Erkennung und Eskalationsrichtlinien |
| Infrastruktur | Selbst gehostete Komponenten, die dedizierte Server, Speicher und laufende Wartung erfordern | Vollständig verwaltete SaaS-Plattform ohne zu provisionierende oder zu wartende Server |
| Service Discovery | Manuelle YAML-basierte Service-Discovery-Konfiguration für jeden Zieltyp | Automatische Erkennung laufender Dienste, Container und Prozesse ohne Konfiguration |
| Mobile Apps | Nur Web-Interface, keine native mobile Erfahrung für Monitoring unterwegs | Native iOS- und Android-Apps mit Push-Benachrichtigungen für Echtzeit-Alerting auf dem Handy |
| Uptime-Monitoring | Erfordert Bereitstellung und Konfiguration von blackbox_exporter mit Probe-Modulen | Integriertes HTTP-, TCP- und ICMP-Monitoring von 7 globalen Standorten mit Latenz-Tracking |
| Skalierung | Komplexe Federation oder Thanos/Cortex-Bereitstellung für Multi-Cluster-Skalierung erforderlich | Automatische horizontale Skalierung, fügen Sie einfach Agenten hinzu, die Plattform erledigt den Rest |
| Wartung | Manuelle Updates, Backup-Strategien, Aufbewahrungsrichtlinien und Sicherheitspatches für jede Komponente | Keine Wartung erforderlich, automatische Updates und verwaltete Backups mit garantierter Uptime |
| Dashboard-Erstellung | Manuelle PromQL-Abfragen, stundenlange Panel-Konfiguration und Variablen-Setup pro Dashboard | Vorgefertigte Dashboards für alle erkannten Dienste, in Sekunden bereit ohne Abfragen schreiben |
| Prometheus-Kompatibilität | Natives Prometheus, erfordert jedoch vollständige selbstverwaltete Prometheus-Bereitstellung | Scrapt Prometheus-Exporter nativ, kein separater Prometheus-Server erforderlich |
| Datenaufbewahrung | Standard 15 Tage, Langzeitspeicherung erfordert Thanos oder Mimir mit Object Storage | Ein Jahr Aufbewahrung inklusive, keine zusätzliche Infrastruktur oder Speicherkonfiguration |
| Lernkurve | Steil: PromQL, LogQL, Alertmanager-Routing, Relabeling-Regeln und YAML-Konfiguration | Intuitive Weboberfläche, produktiv in Stunden ohne Abfragesprache erforderlich |
Gesamtbetriebskosten
Grafana Stack
Bleemeo
*Mit 1-Jahres-Reservierung. Logs separat berechnet: 0,50€/GiB.
Warum Bleemeo Wählen
All-in-One-Plattform
Schluss mit dem Jonglieren von Prometheus, Loki, Alertmanager, Thanos und Grafana als separate Komponenten. Bleemeo liefert Metrikerfassung, Log-Aggregation, Uptime-Monitoring, intelligentes Alerting und Echtzeit-Dashboards in einer einzigen integrierten Plattform. Alles funktioniert sofort zusammen und eliminiert Konfigurationsdrift und Versionsinkompatibilitäten zwischen Komponenten.
Intelligenter Agent
Der Bleemeo-Agent entdeckt automatisch laufende Dienste, Container, Datenbanken und Webserver auf jedem Host. Er sammelt System-Metriken, anwendungsspezifische Metriken und Logs, ohne dass Sie separate Exporter installieren oder konfigurieren müssen. Ein Agent ersetzt node_exporter, process-exporter und Dutzende anwendungsspezifischer Exporter und reduziert Ihre Bereitstellungsfläche drastisch.
Keine Infrastruktur
Keine Prometheus-Server zu skalieren, keine Loki-Cluster zu verwalten, keine Thanos-Kompaktierungsjobs zu optimieren und keine Komponenten zu patchen oder aktualisieren. Bleemeo verwaltet die gesamte Backend-Infrastruktur einschließlich Hochverfügbarkeit, Datenreplikation und Langzeitspeicherung. Ihr Team gewinnt die Engineering-Stunden zurück, die zuvor für den Betrieb des Monitoring-Stacks selbst aufgewendet wurden.
Prometheus-kompatibel
Bereits in Prometheus-Exporter und benutzerdefinierte Metriken investiert? Glouton, der Bleemeo-Agent, unterstützt nativ das Prometheus-Expositionsformat und kann Ihre bestehenden Exporter-Endpoints direkt scrapen. Kein separater Prometheus-Server nötig, was die Migration schrittweise und risikofrei macht. Ihr bestehendes PromQL-Wissen und Ihre benutzerdefinierten Metriken bleiben vollständig erhalten.
Intelligente Alerts
Bleemeo enthält integrierte Anomalie-Erkennung, die normale Verhaltensmuster Ihrer Infrastruktur erlernt und Sie bei Abweichungen alarmiert. Intelligentes Alert-Routing liefert Benachrichtigungen per E-Mail, Slack, PagerDuty oder mobile Push-Benachrichtigungen, ohne komplexe Alertmanager-Routing-Bäume. Schwellenwert-basierte Alerts sind für gängige Dienste vorkonfiguriert, sodass Sie vom ersten Tag an aussagekräftige Alerts erhalten.
Schöne Dashboards
Bleemeo bietet moderne, responsive Dashboards, die automatisch für jeden erkannten Dienst generiert werden. Im Gegensatz zu Grafana, wo Sie Stunden mit PromQL-Abfragen und Panel-Konfiguration verbringen, sind Bleemeo-Dashboards sofort mit sinnvollen Standardwerten bereit. Sie können weiterhin benutzerdefinierte Ansichten erstellen und in spezifische Metriken eintauchen, aber die Out-of-the-Box-Erfahrung deckt die meisten Monitoring-Bedürfnisse ohne manuelles Setup ab.
Einfacher Übergang vom Grafana-Stack
Die Migration vom Grafana-Stack muss kein Big-Bang-Umstieg sein. Sie können Bleemeo neben Ihrem bestehenden Prometheus- und Grafana-Setup betreiben, die Abdeckung validieren und schrittweise Komponenten stilllegen, die Sie nicht mehr benötigen. Der gesamte Prozess dauert bei den meisten Teams typischerweise weniger als eine Woche.
Bleemeo-Agenten bereitstellen
Installieren Sie den Bleemeo-Agenten auf jedem Server mit einem einzigen Befehl. Der Agent läuft neben Ihren bestehenden Prometheus-Exportern ohne Konflikte und beginnt sofort mit der Erfassung von System-Metriken, der Erkennung von Diensten und dem Versand von Daten an die Bleemeo-Plattform:
wget -qO- 'https://get.bleemeo.com?accountId=...' | sudo bashAbdeckung überprüfen
Melden Sie sich an der Bleemeo-Konsole an und überprüfen Sie, ob alle Ihre Server, Container und Dienste automatisch angezeigt werden. Der Agent erkennt Datenbanken wie MySQL und PostgreSQL, Webserver wie Nginx und Apache, Message-Queues wie RabbitMQ und Kafka und viele weitere Dienste ohne manuelle Konfiguration. Vergleichen Sie die erkannten Dienste mit Ihren bestehenden Prometheus-Scrape-Targets, um vollständige Abdeckung sicherzustellen.
Bestehende Exporter verbinden
Wenn Sie benutzerdefinierte Prometheus-Exporter oder anwendungsinstrumentierte Metriken haben, konfigurieren Sie Glouton, um deren Endpoints direkt zu scrapen. Glouton unterstützt das Standard-Prometheus-Expositionsformat nativ, sodass Ihre bestehenden benutzerdefinierten Metriken ohne Änderung erhalten bleiben.
Alerts einrichten
Konfigurieren Sie Ihre Benachrichtigungskanäle wie E-Mail, Slack, PagerDuty oder Webhook-Integrationen. Bleemeo kommt mit sinnvollen Standard-Alert-Schwellenwerten für CPU, Speicher, Festplatte und Service-Verfügbarkeit. Überprüfen Sie diese Standards, passen Sie Schwellenwerte an Ihre SLOs an und fügen Sie benutzerdefinierte Alert-Regeln für anwendungsspezifische Metriken hinzu. Viele Teams stellen fest, dass Bleemeos integrierte Anomalie-Erkennung Probleme erkennt, die ihre handgefertigten Alertmanager-Regeln übersehen haben.
Parallel validieren
Betreiben Sie Bleemeo neben Ihrem bestehenden Grafana-Stack während einer Validierungsphase. Vergleichen Sie Alerts, Dashboards und Metrik-Abdeckung zwischen beiden Systemen. Dieser Parallelbetrieb stellt sicher, dass Sie volles Vertrauen in Bleemeo haben, bevor Sie Änderungen an Ihrem bestehenden Setup vornehmen. Die meisten Teams betreiben beide Systeme ein bis zwei Wochen.
Stilllegen & vereinfachen
Sobald validiert, legen Sie schrittweise die Grafana-Stack-Komponenten still, die Sie nicht mehr benötigen. Entfernen Sie Prometheus-Server, Loki-Cluster, Alertmanager-Instanzen und die Flotte von Exportern aus Ihrer Infrastruktur. Das gibt Rechenressourcen frei, reduziert Ihre Angriffsfläche und eliminiert den Bereitschaftsdienst-Aufwand für die Wartung der Monitoring-Plattform selbst. Ihr Team kann sich nun vollständig auf den Aufbau und Betrieb Ihres eigentlichen Produkts konzentrieren.
Was unsere Kunden sagen
Ingenieure und CTOs vertrauen auf Bleemeo für ihr Infrastruktur-Monitoring
Während einer kurzen Mittagspause haben wir Bleemeo installiert, eine benutzerdefinierte Metrik erstellt, Alerts getestet und waren produktionsbereit. Die Geschwindigkeit der Bereitstellung ist bemerkenswert.

Der Bleemeo-Support ist schlicht legendär — schnell, kompetent und immer da, wenn wir ihn brauchen.
Bleemeo war unglaublich schnell einzurichten. In etwa einer Stunde haben wir es auf über 100 Servern ausgerollt und sofort volle Sicht auf unsere Infrastruktur erhalten.

Wir haben das Monitoring für alle unsere Server in nur wenigen Stunden eingerichtet. Das Dashboard ist übersichtlich, leistungsstark und macht wirklich Freude in der Nutzung.

Wir haben Bleemeo in nur wenigen Stunden auf unserer gesamten Server-Infrastruktur ausgerollt. Das Uptime-Monitoring benachrichtigt uns jetzt sofort, wenn ein Dienst ein Problem hat.

Unser Prometheus + Grafana-Stack war zu einem Wartungsprojekt geworden. Mit Bleemeo haben wir den Agenten in Minuten ausgerollt und uns endlich auf die Nutzung des Monitorings statt auf dessen Wartung konzentriert.
Nach der Installation des Agenten hat Bleemeo automatisch unsere Datenbanken, Container und Services erkannt. Innerhalb einer Stunde hatten wir volle Infrastruktur-Sichtbarkeit — ohne Dashboards oder Exporter bauen zu müssen.
Bleemeo hat mehrere Monitoring-Tools durch eine einzige Plattform ersetzt. Metriken, Alerts und Logs sind jetzt an einem Ort, was unserem Team erheblich Zeit spart.
Bleemeo gab uns sofortigen Einblick in unsere Infrastruktur ohne die übliche Komplexität. Innerhalb weniger Stunden liefen Metriken, Alerts und Dashboards reibungslos.
Die Einrichtung von Bleemeo war erfrischend einfach. Das Agent-Deployment dauerte Minuten und die automatische Erkennung ersparte uns Tage an Konfiguration.
Dank Bleemeo erkennt unser Team Probleme jetzt, bevor unsere Nutzer sie bemerken. Die Alerting-Funktion ist zuverlässig und die Oberfläche macht die Fehlersuche deutlich schneller.
Der Wechsel zu Bleemeo hat unseren Monitoring-Stack dramatisch vereinfacht. Statt mehrere Tools zu verwalten, ist alles, was wir brauchen, auf einer einzigen Plattform verfügbar.
Die Zentralisierung unserer Logs in Bleemeo hat die Fehlersuche drastisch vereinfacht. Statt zwischen Tools zu wechseln, können wir jetzt Metriken und Logs sofort korrelieren, um zu verstehen, was passiert.
Bleemeo hat das Kubernetes-Monitoring überraschend einfach gemacht. Innerhalb von Minuten hatten wir Einblick in unsere Cluster, Pods und Workloads, ohne komplexe Dashboards selbst bauen zu müssen.
Bleemeo in Aktion sehen
Sehen Sie, wie Teams in unter 5 Minuten von der Installation zum vollständigen Monitoring gelangen
Häufig gestellte Fragen
Kann Bleemeo den gesamten Grafana-Stack ersetzen?
Ja. Bleemeo ersetzt Grafana, Prometheus, Loki, Alertmanager und Mimir durch eine einzige verwaltete Plattform. Metriken, Logs, Dashboards und Alerting sind alle enthalten.
Muss ich Dashboards von Grund auf erstellen?
Nein. Bleemeo erstellt automatisch Dashboards für jeden automatisch erkannten Dienst. Benutzerdefinierte Dashboards sind ebenfalls verfügbar, wenn Sie spezifische Ansichten benötigen.
Unterstützt Bleemeo Prometheus-Metriken?
Ja. Glouton, der Bleemeo-Agent, scrapt Prometheus-Exporter nativ, sodass bestehende Exporter und benutzerdefinierte Instrumentierung sofort funktionieren.
Was ist mit Grafana Cloud?
Die Preise von Grafana Cloud skalieren mit der Nutzung (Metriken, Logs, Traces). Bleemeos Pro-Agent-Preise sind vorhersehbar unabhängig vom Datenvolumen — keine Per-Series- oder Per-GB-Gebühren.
Kann ich Bleemeo neben meinem bestehenden Grafana-Setup verwenden?
Ja. Sie können Bleemeo-Agenten während der Migration neben Ihrem aktuellen Grafana-Stack betreiben. Glouton arbeitet unabhängig und beeinträchtigt Prometheus oder andere Collectors nicht.
Unterstützt Bleemeo benutzerdefinierte Dashboards?
Ja. Während Bleemeo Dashboards für jeden erkannten Dienst automatisch erstellt, können Sie auch benutzerdefinierte Dashboards mit Drag-and-Drop-Widgets für spezifische Ansichten erstellen, die Ihr Team benötigt.
Gibt es ein kostenloses Angebot?
Ja. Überwachen Sie bis zu 3 Server kostenlos ohne Zeitlimit. Alle Funktionen inklusive — Dashboards, Alerts, Logs, Service-Erkennung.
Wie vergleicht sich das Log-Management mit Loki?
Bleemeo bietet zentrale Log-Sammlung und -Suche für 0,50€/GiB aufgenommen. Kein separates Loki-Deployment, keine Promtail-Agenten, kein Storage-Backend zu verwalten.
Bereit, die LGTM-Stack-Komplexität Hinter Sich zu Lassen?
Schließen Sie sich Hunderten von Engineering-Teams an, die vom separaten Betrieb von Prometheus, Loki, Alertmanager und Grafana zu einer einzigen Plattform gewechselt haben, die einfach funktioniert. Starten Sie heute Ihre kostenlose Testversion und erleben Sie vollständiges Infrastruktur-Monitoring ohne operativen Overhead. Stellen Sie Ihren ersten Agenten in unter fünf Minuten bereit und sehen Sie sofort Metriken fließen.
Keine Kreditkarte erforderlich · 15 Tage kostenlose Testversion · Funktioniert neben Ihrem bestehenden Grafana-Stack · Voller Funktionszugang