Monitoreo Kubernetes
Observabilidad completa para sus clusters Kubernetes. Monitoree nodos, pods, contenedores y servicios con descubrimiento automatico, compatibilidad con Prometheus y alertas inteligentes.
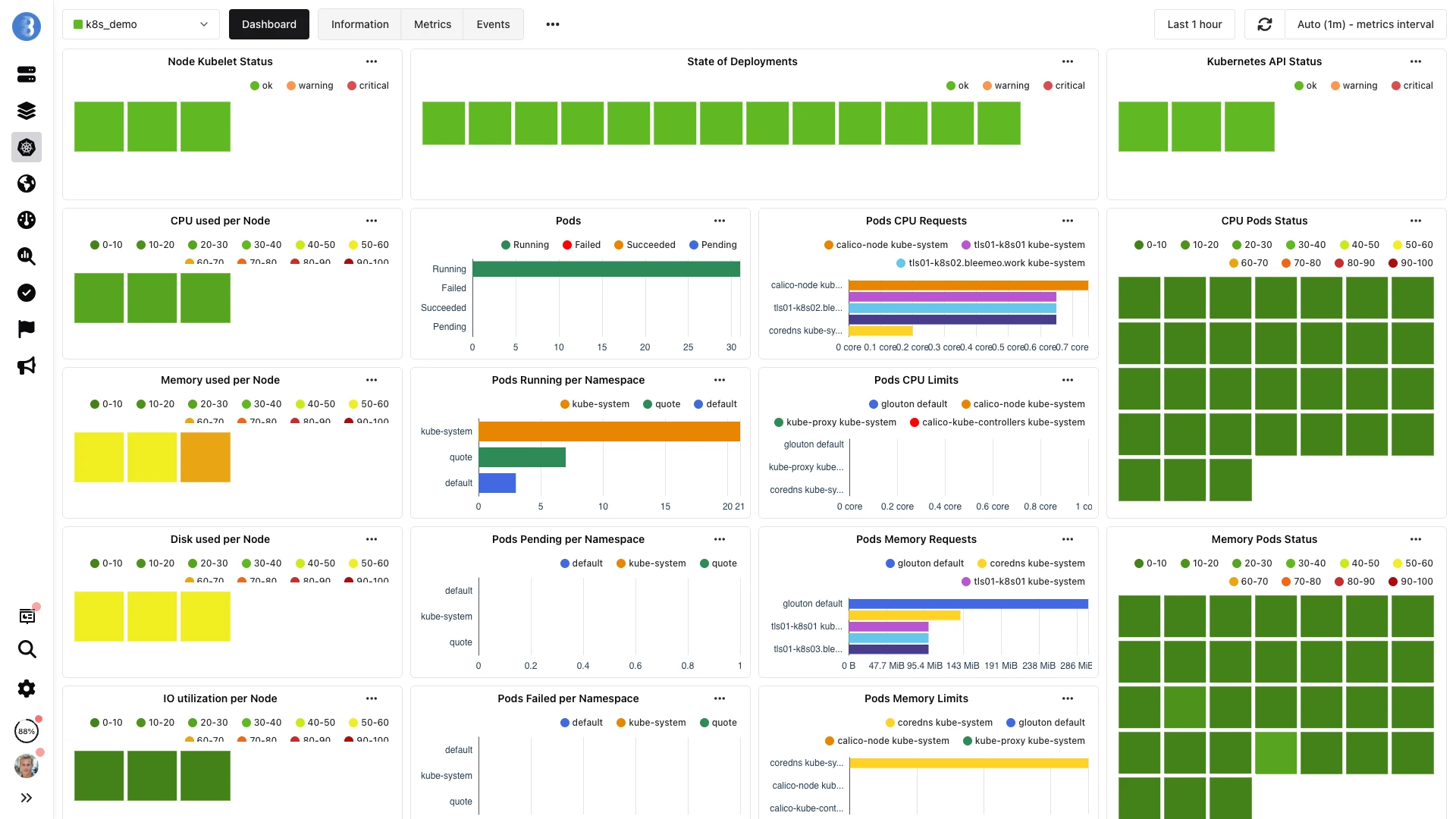
Observabilidad Full-Stack de Kubernetes
Desde la salud del cluster hasta las metricas de contenedores individuales, obtenga visibilidad completa de su entorno Kubernetes.
Nivel de Cluster
Salud del plano de control, latencia del API server, rendimiento de etcd, metricas del scheduler
Nivel de Nodo
CPU, memoria, disco, red, estado de kubelet, condiciones del nodo
Nivel de Pod
Ciclo de vida de pods, conteo de reinicios, requests vs limits de recursos, readiness
Nivel de Contenedor
Throttling de CPU, uso de memoria, eventos OOM, estados de contenedores
Que Monitoreamos
Plano de Control
Monitoree el corazon de su cluster Kubernetes para confiabilidad y rendimiento.
- Latencia de solicitudes del API Server
- Salud y latencia de etcd
- Profundidad de cola del Scheduler
- Metricas del Controller manager
- Expiracion de certificados
Nodos y Kubelet
Rastree la salud de los nodos y el rendimiento de kubelet en todo su cluster.
- CPU, memoria, disco del nodo
- Estado de salud de Kubelet
- Condiciones del nodo (Ready, DiskPressure, etc.)
- Capacidad y asignacion de pods
- Metricas del runtime de contenedores
Pods y Contenedores
Visibilidad profunda del rendimiento de cargas de trabajo y consumo de recursos.
- Uso de CPU y throttling
- Uso de memoria y OOM kills
- Conteo de reinicios y crash loops
- Resource requests vs limits
- Estados y eventos de contenedores
Servicios y Red
Monitoree endpoints de servicios y conectividad de red.
- Salud de endpoints de servicios
- Trafico y latencia de Ingress
- Efectividad de network policies
- Tiempos de resolucion DNS
- Metricas de service mesh (Istio, Linkerd)
Recursos de Cargas de Trabajo
Rastree Deployments, StatefulSets, DaemonSets y Jobs.
- Estado de replicas de Deployment
- Progreso de rolling updates
- Ordenamiento de StatefulSet
- Cobertura de DaemonSet
- Completacion de Job y CronJob
Almacenamiento Persistente
Monitoree PersistentVolumes y rendimiento de almacenamiento.
- Estado de binding PV/PVC
- Uso de capacidad de almacenamiento
- Throughput y latencia de E/S
- Aprovisionamiento de StorageClass
- Errores de montaje de volumenes
Caracteristicas Nativas de Kubernetes
Auto-Descubrimiento
Descubra y monitoree automaticamente pods, servicios y endpoints. Sin configuracion manual necesaria mientras las cargas de trabajo escalan.
Compatible con Prometheus
Soporte nativo de PromQL. Recolecte endpoints Prometheus existentes. Use sus recording rules y alertas existentes.
Consciente de Labels
Filtre y agregue por labels y annotations de Kubernetes. Agrupe metricas por namespace, deployment o labels personalizados.
Optimizacion de Recursos
Dimensione correctamente los resource requests y limits basandose en el uso real. Identifique cargas de trabajo sobre-provisionadas y sub-provisionadas.
Alertas Inteligentes
Alertas preconfiguradas para problemas comunes de K8s: CrashLoopBackOff, pods pendientes, nodo NotReady, expiracion de certificados.
Multi-Cluster
Monitoree multiples clusters Kubernetes desde un unico dashboard. Compare el rendimiento entre entornos.
Despliegue con Helm
Despliegue el agente Bleemeo con un unico Helm chart. Listo para GitOps con opciones de personalizacion completas.
OpenTelemetry
Ingeste trazas y metricas via OpenTelemetry. Correlacione metricas de infraestructura con trazas de aplicacion.
Configuracion Rapida con Helm
Agregar Repositorio Helm de Bleemeo
Agregue el repositorio oficial de Helm charts de Bleemeo a su instalacion de Helm.
helm repo add bleemeo-agent https://packages.bleemeo.com/bleemeo-agent/helm-charts
helm repo updateInstalar el Agente
Despliegue el agente Glouton como DaemonSet con las credenciales de su cuenta.
helm upgrade --install glouton bleemeo-agent/glouton \
--set account_id="your_account_id" \
--set registration_key="your_registration_key" \
--set config.kubernetes.clustername="my_k8s_cluster_name" \
--set namespace="default"Ver Su Cluster
Los nodos, pods y servicios aparecen automaticamente en su dashboard de Bleemeo en segundos.
Alertas Predefinidas de Kubernetes
Reciba notificaciones sobre problemas comunes de Kubernetes antes de que impacten a sus usuarios.
Problemas de Pods
- CrashLoopBackOff detectado
- Pod atascado en Pending
- Alto conteo de reinicios
- Contenedores OOMKilled
Problemas de Nodos
- Nodo NotReady
- Alta presion de CPU/memoria
- Espacio en disco bajo
- Demasiados pods programados
Problemas de Cluster
- Errores del API server
- Latencia alta de etcd
- Certificado por expirar
- PVC pendiente
Problemas de Cargas de Trabajo
- Replicas de Deployment no disponibles
- StatefulSet no listo
- Job fallido
- HPA en replicas maximas
Funciona Con Su Stack
Por Que Bleemeo para Kubernetes?
Visibilidad en Tiempo Real
Vea la creacion de pods, eventos de escalado y fallos a medida que ocurren. Sin demora en la recoleccion de metricas.
Optimizacion de Costos
Identifique desperdicio de recursos y dimensione correctamente sus cargas de trabajo. Reduzca el gasto en la nube sin impactar el rendimiento.
Agente Ligero
Glouton usa recursos minimos. Menos de 100MB de memoria por nodo. No competira con sus cargas de trabajo.
13 Meses de Retencion
Mantenga datos historicos para planificacion de capacidad y analisis de tendencias. Compare el rendimiento a lo largo del tiempo.
Comience a Monitorear Sus Clusters Kubernetes
Despliegue en minutos. Obtenga visibilidad completa de su infraestructura K8s.